
 [RL] Q-learning: Off-policy TD Control
[RL] Q-learning: Off-policy TD Control
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 사실 Q-learning에 대해서는 옛날에 한 포스트를 통해서 다뤘었는데, 다시 정리를 해보고자 한다. 일단 알고리즘은 아래와 같다. 이전 포스트에서 다뤘던 SARSA와 거의 비슷한데, 한가지 다른 부분이 바로 Value function을 update하는 부분이다. 다시 한번 SARSA의 update 부분을 살펴보자. $$ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (\color{red}{R_{t+1}} + \color{red}{\gamma Q(S_{t+1}, A_{t+1})} - Q(S_t, A_t)) $$ 그런데 위의 식은 사실 Dynamic Programm..
 [RL] SARSA : GPI with TD
[RL] SARSA : GPI with TD
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트 중에 Generalized Policy Iteration (GPI)에 대해서 다뤘던 내용이 있다. GPI는 현재 policy \(\pi\)에 대한 state value function을 구하는 Policy Evaluation과 해당 state value function을 바탕으로 greedy action을 취함으로써 해당 policy를 개선시키는 Policy Improvement 과정으로 나뉘어져 있다. 그 포스트에서는 Monte Carlo를 사용한 GPI를 소개했었다. 그런데 이제 TD Learning을 살펴봤으니, Monte Carlo method가 Episode가 terminat..
 [RL] Introduction to Temporal Difference Learning
[RL] Introduction to Temporal Difference Learning
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트에서는 Off-policy 방식의 Monte Carlo Prediction에 대해서 다뤘다. 일단 Monte Carlo의 특성상 policy에 대한 trajectory를 여러개 뽑아서 expectation을 취해야 한다. $$ v_{\pi}(s) \doteq \mathbb{E}_{\pi}[ \color{red}{G_t} | S_t=s] $$ 일단 위처럼 State value function을 구하기 위해서는 해당 state \(s\)에서의 total expected return \(G_t\)을 구해야 하고, 이때 Policy Evaluation에선 다음과 공식을 통해서 state val..
 [RL] Off-policy Learning for Prediction
[RL] Off-policy Learning for Prediction
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트에서는 Monte Carlo method를 Policy Iteration에 적용하기 위해서 필요한 Exploration policy 중 하나인 \(\epsilon\)-soft policy를 소개했다. 그러면서 참고로 소개한 내용 중에 On-policy와 Off-policy라는 것이 있었다. 이 중 Off-policy에 초점을 맞춰서 다뤄보고자 한다. 잠깐 설명이 되었던 바와 같이, On-policy는 action을 선택하는 policy를 직접 evaluate하고, improve시키는 방식을 말한다. 반대로 Off-policy는 action을 선택하는 policy와는 별개로 별도의 pol..
 [RL] Exploration Methods for Monte Carlo
[RL] Exploration Methods for Monte Carlo
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) Monte Carlo Control의 알고리즘을 보면 초기에 state와 action을 random하게 주는 Exploring Starts (ES)가 반영되어 있는 것을 확인할 수 있었다. 이 방법은 Optimal Policy를 찾는데 적합한 알고리즘일까? 사실 초기 state와 action을 random하게 주는 이유는 policy를 update하는데 있어 필요한 State-Action Value Function을 확보하기 위함이었고, 처음이 지난 이후에는 처음에 설정된 policy \(\pi\)에 따라 움직이는 이른바 deterministic policy이다. 분명 State-Action Va..
 [RL] Monte Carlo for Control
[RL] Monte Carlo for Control
(해당 포스트는 Coursera의 Sample-based Learning Method의 강의 요약본입니다) 일단 State Value Function을 이용한 Monte Carlo Method는 다음과 같이 정의가 된다. $$ V_\pi(s) \doteq \mathbb{E}_{\pi}[G_t | S_t = s] $$ 사실 State Value Function와 State-Action Value Function의 관계는 다음과 같이 정의되어 있기 때문에, $$ V_{*}(s) = \max_{a} Q_{*}(s,a) $$ 이를 활용해보면 다음과 같은 식도 구할 수 있다. $$ q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a] $$ 결국 위 식의 의..
 [RL] What is Monte Carlo?
[RL] What is Monte Carlo?
(해당 포스트는 Coursera의 Sample-based Learning Method의 강의 요약본입니다) Policy Evaluation이나 Policy Improvement는 내부적으로 value function \(V(s)\)를 구할 때 transition probability \(p(s', r| s, \pi(s))\)를 활용했고, 이를 Dynamic Programming을 통해서 구했다. 그런데 생각해보면 알겠지만, 보통 강화학습을 구할 때, 이 transition probability를 아는 상태에서 학습을 시키는 경우는 거의 드물다. 이 Probability를 Dynamic Programming을 통해서 구하는 것은 어렵기 때문에, 보통은 estimation을 통해서 구하는데, 이때 많이 활용..
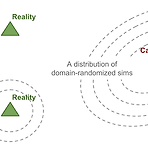 [RL] Domain Randomization for Sim2Real Transfer
[RL] Domain Randomization for Sim2Real Transfer
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Domain Randomization for Sim2Real Transfer If a model or policy is mainly trained in a simulator but expected to work on a real robot, it would surely face the sim2real gap. Domain Randomization (DR) is a simple but powerful idea of closing this gap by randomizing properties of the training environ lilianweng.github.io 만약 model이나 ..
 [RL] Flexibility of the Policy Iteration Framework
[RL] Flexibility of the Policy Iteration Framework
(해당 포스트는 Coursera의 Fundamentals of Reinforcement Learning의 강의 요약본입니다) Policy Iteration은 Policy Evaluation과 Policy Improvement를 반복하면서 현재의 policy \(\pi\)를 최대한 optimal policy \(\pi_*\)에 가깝게 update하는 방법을 말한다. 아마 Sutton책에서는 다음과 같은 그림으로 도식화를 해놨을 것이다. 아니면 이런 그림도 같이 보았을 것이다. 현재의 policy \(\pi\)와 초기의 value function \(v\)가 있으면, 처음에는 \(\pi\)에 따라 action을 취하고 이에 맞게 value function을 update하게 된다 (\(v=v_{\pi}\)) ..
 [Me][ML] How AI and machine learning are improving customer experience
[Me][ML] How AI and machine learning are improving customer experience
원본 : https://www.oreilly.com/ideas/how-ai-and-machine-learning-are-improving-customer-experience 작성자 : Ben Lorica, Mike Loukides (이 글은 한빛미디어의 콘텐츠 세션에서 "인공지능(AI)와 머신러닝(ML)은 어떻게 고객의 경험을 향상시키는가" 라는 글로 게시되었습니다.) 데이터의 질에서부터 개인화, 고객의 효용가치나 소유에 이르기까지 궁극적으로 AI와 ML은 미래의 고객의 경험적인 부분을 좌우할 것이다. 인공지능(AI)이나 머신러닝(ML)의 어떤 부분이 고객의 경험적인 부분을 향상시킬 수 있을까? 사실 AI와 ML은 이미 온라인 쇼핑이 시작하는 시점부터 온라인 쇼핑과 긴밀하게 연결되어 왔다. 아마 당신은 ..
 [DL] Meta-Learning: Learning to Learn Fast
[DL] Meta-Learning: Learning to Learn Fast
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Meta-Learning: Learning to Learn Fast Meta-learning, also known as “learning to learn”, intends to design models that can learn new skills or adapt to new environments rapidly with a few training examples. There are three common approaches: 1) learn an efficient distance metric (metric-based); lilianweng.github.io "Learning To Lea..
이전에 다뤘던 Q-learning같은 방법들을 보면, 각 state에 대한 expected return들을 일종의 table 형식으로 관리하는 것을 확인할 수 있었다. Bellman Equation을 사용해서 우리는 나름의 각 state에 대한 \(v_{\pi}(s)\) 를 구하거나, 각 state-action pair에 대한 \(q_{\pi}(s, a)\)를 구하고 매 step마다 table을 업데이트하면서 나름의 optimal policy를 찾으려고 노력할 것이다. 여기서 주어진 환경내에서 취할 action을 정의한 policy \(\pi\)에 대한 state value function \(v_{\pi}(s)\) 를 구한다고 해보자. 강화학습의 특성상 우리는 미래에 얻을 수 있는 expected re..
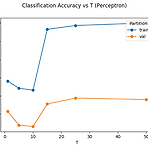 [ML] Averaged Perceptron / Pegasos
[ML] Averaged Perceptron / Pegasos
이전에 강의들을 때는 Perceptron이 그냥 Linear classification을 할때 쓰는 간단한 알고리즘이라고 생각했었는데, 나중에 와서 다시 공부해보니까, weight의 update 주기나 convergence에 대한 고민을 하면서 여러가지 기법들이 더 나온것을 알았다. 마침 하던 과제 중에 sentiment_analysis를 여러가지 perceptron으로 해서 성능 비교하는 내용이 있어 공유해본다. 참고로 Pegasos(Primal Estimated sub-GrAdient SOlver for SVM, Shalev-Shwartz et al, 2011)은 SVM을 사용할 때 gradient descent를 접목시킨 내용인데, 여타 알고리즘에 비해 convergence가 잘 되는 것으로 알고 ..
 [RL] Policy Gradient Algorithms
[RL] Policy Gradient Algorithms
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Policy Gradient Algorithms Abstract: In this post, we are going to look deep into policy gradient, why it works, and many new policy gradient algorithms proposed in recent years: vanilla policy gradient, actor-critic, off-policy actor-critic, A3C, A2C, DPG, DDPG, D4PG, MADDPG, TRPO, lilianweng.github.io Policy Gradient 강화학습의 목적은 o..
이전에 다뤘던 포스트 중에 ANN을 사용해서 Churn prediction을 했던 내용이 있다. 간단히 말해 개인에 대한 정보를 바탕으로 이 사람이 credit이 있는지 없는지 여부를 판단해주는 예제였다. 그때 사용했던 데이터를 보통 데이터 필드가 numerical variable도 있고, categorical variable도 있었다. 물론 categorical variable을 ML이나 Deep Learning에서 다루기 위해서는 뭔가 의미있는 정보로 변화시켜주는 일련의 Encoding 과정이 필요했고, 그 때 기억으로는 Scikit-learn에서 제공하는 LabelEncoder와 OneHotEncoder를 사용해서 데이터를 Binary 처리를 하고, 학습에 반영했다. 아마 이렇게 처리하는 방식이 C..
- Total
- Today
- Yesterday
- DepthStream
- 딥러닝
- Windows Phone 7
- 한빛미디어
- Variance
- Distribution
- Kinect
- PowerPoint
- Kinect for windows
- Policy Gradient
- SketchFlow
- Pipeline
- arduino
- TensorFlow Lite
- Python
- ColorStream
- Off-policy
- 파이썬
- RL
- dynamic programming
- processing
- Gan
- windows 8
- Expression Blend 4
- Offline RL
- Kinect SDK
- bias
- reward
- End-To-End
- 강화학습
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |