
티스토리 뷰
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.)
Meta-Learning: Learning to Learn Fast
Meta-learning, also known as “learning to learn”, intends to design models that can learn new skills or adapt to new environments rapidly with a few training examples. There are three common approaches: 1) learn an efficient distance metric (metric-based);
lilianweng.github.io
"Learning To Learn" 이라고 알려져 있는 Meta-learning은 몇몇 training 예제를 통해서 모델로 하여금, 새로운 기술을 배우거나, 새로운 환경에 빠르게 적응할 수 있도록 설계하는 것을 나타낸다. 보통 3개 정도의 접근 방식이 있다.
1) (metric 기반의) efficient distance metric을 학습하는 방식
2) (model 기반의) external/internal memory를 통한 (recurrent) network을 사용하는 방식
3) (optimization 기반의) fast learning을 위한 model parameter를 최적화하는 방식
머신러닝을 통해서 좋은 모델을 만들기 위해서는 일반적으로 수많은 샘플을 활용해서 학습을 시키는 것이 필요하다. 이와 반대로 인간의 경우에는 훨씬 빠르고 효율적으로 새로운 개념이나 기술들을 학습한다. 고양이나 새를 많이 보지 않은 아이들이라고 할지라도 빠르게 그걸 구분할 수 있다. 자전거를 타는 방법을 아는 사람들은 시연 같은 과정 없이도 빠르게 오토바이를 타는 방법을 발견하곤 한다. 머신러닝에서도 이와 같이 적은 샘플만 가지고도 새로운 개념과 기술을 빠르게 학습하는 것이 가능할까? 이 것이 바로 본질적으로 meta-learning이 풀고자 하는 문제점이다.
보통 좋은 meta-learning model이라고 하면, training time 동안에 접하지 않았던 새로운 task나 environment에 대해서 잘 적응하거나, 일반화가 잘 되는 것을 말한다. adaptation process (본질적으로 말하자면 mini learning session)은 test 과정에서 일어나게 되는데, 사실 이 때에는 새로운 task configuration에 대해서 제한적으로만 노출되어 있다. 어쨌든, 이렇게 적응된 모델은 새로운 task를 잘 수행할 수 있다. 이 것이 바로 meta-learning이 learning to learn 이라고 알려져 있는 이유이기도 하다.
여기서 task란 supervised learning 이나 reinforcement learning과 같이 machine learning로 정의될 수 있는 모든 문제들이 될수 있다. 예를 들어 meta-learning task를 나열해보면 다음과 같다.
- 고양이가 없는 이미지를 학습시킨 classifier도 몇개의 고양이 사진을 본 후에는 test image상에 고양이가 있는지 여부를 판단할 수 있다.
- 게임 봇이 새로운 게임에 대해서 빠르게 마스터 할 수 있다.
- 평평한 지면 환경에서만 학습해온 미니 로봇이 경사진 환경에서도 task를 수행할 수 있다.
Define the Meta-Learning Problem
이 포스트에서는 처리해야 할 task가 image classification과 같이 supervised learning problem인 것에 초점을 맞춰본다. Reinforcement Learning과 결합된 meta-learning (보통 "Meta Reinforcement Learning"이라고 알려져 있다.)에 대해서 많은 얘기들이 나오고 있지만 여기에서는 다루지 않을 예정이다.
A Simple View
보통 좋은 meta-learing model이라고 하면, 학습하는 task에 대한 다양성(variety)에 대해서 학습되어야 하고, 잠재적으로 인지되지 못한 task를 포함해서 여러 task들의 분포상에서 최고의 성능을 낼 수 있도록 최적화되어야 한다. 각 task들이 dataset \( \mathcal{D} \)로 구성되어 있는데, 여기에는 각각 feature vector들과 true label들이 포함되어 있다. 이때 optimal model parameter는 다음과 같이 정의할 수 있다.
$$ \theta^{*} = \arg\min_{\theta} \mathbb{E}_{\mathcal{D} \sim p(\mathcal{D})}[\mathcal{L}_{\theta}(\mathcal{D})] $$
(첨언을 하자면 위 식의 목표는 여러 개의 dataset 중에서 샘플링된 dataset \(\mathcal{D}\)에 대해서 Loss function \(\mathcal{L}_{\theta}(\mathcal{D}) \)을 최소화할 수 있는 \( \theta\)를 찾겠다는 의미이다.)
위의 식은 일반적인 learning task와 매우 유사하지만, 한가지 다른 부분은 하나의 dataset 자체가 하나의 data sample로 활용되고 있다는 것이다.
Few-shot classification은 supervised learing 상에서 meta-learning을 활용한 예시이다. 여기서 dataset \( \mathcal{D}\)는 크게 두개로 나눠볼 수 있는데, 하나는 learning을 위한 support set \(S\)이고, 다른 하나는 training이나 testing을 위한 prediction set \(B\)이다. 그러면 dataset \(\mathcal{D} =\) <\(S, B\)> 로 표현할 수 있게 된다. 보통 K-shot N-class classification task를 다루게 되는데, 이건 support set이 각 N개 class에 대해서 K개로 labelling된 데이터들을 포함하고 있다는 것을 말한다.

Training in the Same Way as Testing
위의 예시에 나온 dataset \(\mathcal{D}\)는 여러 쌍의 feature vector와 label들을 포함하고 있고, \(\mathcal{D} = \{(\mathbf{x}_{i}, y_{i})\}\) 라고 표현할 수 있고, 이때 각 label은 우리가 알고있는 label set \(\mathcal{L}\) (참고로 위에 나온 Loss function이 아닌 label set이다.)에 속해 있다고 해보자. 이제 우리가 만들 parameter \(\theta\)를 가진 classifier \(f_{\theta}\)는 주어진 데이터가 feature vector \(\mathbf{x}\)에 대해서 class \(y\)에 속할 확률인 \(P_{\theta}(y|\mathbf{x})\)를 출력으로 내보낼 것이다.
이 때의 optimal parameter는 dataset \(\mathcal{D}\)내에 있는 여러 개의 training batch \(B\)에 대해서 true label을 얻을 수 있는 확률을 높일 수 있어야 한다. 이를 수식으로 표현하면 다음과 같다.
$$ \begin{aligned}
\theta^* &= {\arg\max}_{\theta} \mathbb{E}_{(\mathbf{x}, y)\in \mathcal{D}}[P_\theta(y \vert \mathbf{x})] &\\
\theta^* &= {\arg\max}_{\theta} \mathbb{E}_{B\subset \mathcal{D}}[\sum_{(\mathbf{x}, y)\in B}P_\theta(y \vert \mathbf{x})] & \scriptstyle{\text{; trained with mini-batches.}}
\end{aligned} $$
Few-shot classification의 목표는 "fast learning" 을 위해서 추가한, 약간의 support set을 가지고, unknown label에 대한 데이터의 prediction error를 줄이는 것이다. ("fine-tuning"이 수행되는 과정과 유사하다고 보면 좋을거 같다.) Inference 중에도 training process를 모방한 과정을 넣기 위해서, dataset에 약간에 "fake"를 가해볼 것이다. 이를 통해서 모델이 모든 label에 대해서 인지하고, optimization procedure를 수정하는 것을 막고, 궁극적으로 fast learning이 이뤄질 수 있도록 하는 것이다.
- Label set에서 일부를 샘플링한다. \( L \subset \mathcal{L} \)
- Support set과 training batch를 dataset으로부터 샘플링한다. (\(S^{L} \subset \mathcal{D}, B^{L} \subset \mathcal{D}\)) 두 개의 set 모두 1에서 샘플링된 label set에 속하는 label을 가진 데이터만 가지고 있어야 한다. (\( y \in L, \forall (x, y) \in S^{L}, B^{L} \))
- Support set은 모델의 input이 된다.
- Final optimization 단계에서는 supervised learning에서 하는 것과 동일한 방법으로, mini-batch \(B^{L}\)을 이용해서 loss를 계산하고, backpropagation을 통해서 model parameter를 update한다.
이때 앞에서 샘플링한 \((S^{L}, B^{L})\)을 하나의 data point로 고려할 수 있다. 그러면 모델은 다른 dataset에 대해서도 generalize할 수 있도록 학습되게 된다. 그러면 위에서 언급한 supervised learning의 수식은 빨간색으로 표기된 meta-learning 관련 term을 추가해서 조금 바뀌게 된다.
$$ \theta = \arg\max_\theta \color{red}{E_{L\subset\mathcal{L}}[} E_{\color{red}{S^L \subset\mathcal{D}, }B^L \subset\mathcal{D}} [\sum_{(x, y)\in B^L} P_\theta(x, y\color{red}{, S^L})] \color{red}{]} $$
위와 같은 방식은 ImageNet과 같이 image classification에서 pre-trained된 model을 사용하는 것이나 big text corpora와 같은 language modeling에서 쓰는 방식과 많이 유사하다. Meta-learning은 이런 아이디어를 가져와서, 한단계 낮은 task를 통해 fine-tuning하는 것을 넘어서 전부는 아니더라도 많은 label에 대해서 잘 동작할 수 있도록 모델을 최적화시켜준다.
Learner and Meta-Learner
meta-learning을 바라보는 또다른 관점은 model update하는 과정을 두가지 단계로 나누는 것이다.
- Classifier \(f_{\theta}\)는 "learner" model인데, 주어진 task를 수행할 수 있도록 학습된 상태이다.
- 한편, optimizer \(g_{\phi}\)는 주어진 support set \(S\)를 가지고, learner model의 parameter를 update하는 방법을 학습하게 된다.
(\(\theta = g_{\phi}(\theta, S)\))
그러면 final optimization step에서는 \(\theta\)와 \(\phi\)를 최대화할 수 있도록 update하는 것이 필요하게 된다.
$$ \mathbb{E}_{L\subset\mathcal{L}}[ \mathbb{E}_{S^L \subset\mathcal{D}, B^L \subset\mathcal{D}} [\sum_{(\mathbf{x}, y)\in B^L} P_{g_\phi(\theta, S^L)}(y \vert \mathbf{x})]] $$
Common Approaches
서두에 이야기 했던 것처럼 meta-learning에는 크게 3가지 접근방식이 있다.(metric-based, model-based, optimization-based) Oriol Vinyals이 NIPS 2018에서 진행된 meta-learning symposium에서 talk를 통해서 간단하게 요약했다.
| Model-based | Metric-based | Optimization-based | |
| Key Idea | RNN; memory | Metric learning | Gradient Descent |
| How \(P_{\theta}(y|\mathbf{x})\) is modeled? | \(f_{\theta}(\mathbf{x}, S)\) | \( \sum_{(\mathbf{x}_i, y_i) \in S} k_\theta(\mathbf{x}, \mathbf{x}_i)y_i \) (*) | \(P_{g_\phi(\theta, S^L)}(y \vert \mathbf{x}) \) |
(*) 참고로 \(k_{\theta}\)는 \(\mathbf{x}_{i}\)와 \(\mathbf{x}\) 사이의 similarity를 측정하는 kernel function을 말한다.
Metric-Based Approach
Metric-based meta-learning의 근본적인 개념은 (k-NN classifier나 k-means clustering과 같은) nearest neighbors algorithm과 kernel density estimation과 유사하다. 알려진 label \(y\)에 대한 predicted probability는 support set sample들의 label에 대한 weighted sum과 같다. 이 때 weight는 kernel function \(k_{\theta}\)를 통해서 구할 수 있는데, 이 값은 두 개의 data sample간에 similarity 정도를 나타내는 것이다.
$$ P_{\theta}(y|\mathbf{x}, S) = \sum_{(\mathbf{x}_{i},y_{i}) \in S} k_{\theta}(\mathbf{x}, \mathbf{x}_{i})y_{i} $$
Metric-based meta-learning model이 잘 동작하기 위해서는 좋은 kernel function을 학습하는 것이 중요하다. Metric Learning이 이런 관점에서는 데이터에 대한 metric이나 distance function을 학습한다는 점에서 잘 맞는 학습법이다. 사실 좋은 metric이라는 정의는 문제에 따라서 달라지는데, 중요한 것은 이 metric이 task space내의 input들간의 관계를 잘 표현할 수 있어야 하고, 문제를 해결하는데 이점을 주어야 한다는 것이다.
이제 아래에서 설명할 방법론들은 input data에 대한 embedding vector를 학습하고, 이를 통해서 적절한 kernel function을 설계하는 것에 대해 소개하게 된다.
Convolutional Siamese Neural Network
Siamese Neural Network은 두 개의 twin neural network으로 구성되어 있고, 이에 대한 출력은 input data samples pair간의 관계를 이해하기 위한 함수와 연동되어 학습된다. 이 때 twin network은 서로 동일하고, 같은 weight과 network parameter들을 공유한다. 다르게 표현하자면, data point pair간에 관계를 알아내기 위해서 효율적인 embedding을 학습하는 embedding network를 서로 참고하고 있다고 보면 될거 같다.
Koch, Zemel & Salakhutdinov (2015) 에서는 one-shot image classification을 위해서 siamese neural network를 사용하는 방법을 제안했다. 우선, siamese network은 입력으로 들어온 두개의 image가 같은 class에 속하는지 여부를 판단하는 검증 task를 위해서 학습된다. 이때의 출력은 두개의 image가 같은 class에 들어있을 확률을 나타낸다. 그런 후에, test가 진행되는 동안, siamese network은 test image와 support set내에 들어있는 모든 이미지들간의 image pair에 대해서 모두 위와 같은 작업을 수행하게 되고, 결과적으로 나올 final prediction은 그렇게 처리된 support set image 중에서 가장 높은 정확성을 보이는 class가 될 것이다.

- 우선 Convolutional siamese neetwork은 여러개의 convolutional layer들로 구성된 embedding function \( f_{\theta} \)을 통해서 입력으로 들어온 두 개의 image를 feature vector로 encode하는 것을 학습한다.
- 이때 두개의 embedding간의 L1-distance는 \( | f_{\theta}(\mathbf{x}_{i}) - f_{\theta}(\mathbf{x}_{j})|\)가 된다.
- 이렇게 계산된 L1 distance는 linear feedforward layer와 sigmoid를 통해서 확률 \(p\)로 변환시킬 수 있는데, 이때의 확률은 두개의 image가 같은 class에 속하는지에 대한 확률을 나타낸다.
\(p(\mathbf{x}_{i}, \mathbf{x}_j) = \sigma(\mathbf{W}| f_{\theta}(\mathbf{x}_{i}) - f_{\theta}(\mathbf{x}_{j}|) \) - 직관적으로 보면, 여기서 label은 binary이기 때문에 loss는 cross entropy로 놓고 계산하면 된다.
\( \mathcal{L}(B) = \sum_{ (\mathbf{x}_{i}, \mathbf{x}_{j}, y_{i}, y_{j}) \in B} \mathbf{1}_{y_{i} = y_{j}} \log p(\mathbf{x}_{i}, \mathbf{x}_{j}) + (1 - \mathbf{1}_{y_{i}=y_{j}}) \log (1 - p( \mathbf{x}_{i}, \mathbf{x}_{j} )) \)
(참고로 \( \mathbf{1}_{y_{i} = y_{j}} \) 는 \(y_{i}\)와 \(y_{j}\)가 같은지 여부를 판단하는 binary 상수라고 보면 될거 같다.)
이 때 training batch \(B\)내의 image들은 distortion으로 약간 실제의 image와 다르게 표현될 수도 있다. 물론 위의 과정에서는 L1 Distance를 사용하긴 했지만, L2 distance나 consine distance같은 다른 distance metric을 사용해도 된다. 아무튼 미분가능한 distance metric을 쓰면 동일하게 동작할 것이다.
최종적으로 support set \(S\)와 test image \(\mathbf{x}\)가 주어져 있을때, final predicted class는 다음과 같이 구할 수 있다.
$$ \hat{c}_{S}(\mathbf{x}) = c(\arg \max_{\mathbf{x}_{i} \in S} P(\mathbf{x}, \mathbf{x}_{i})) $$
위 식에서 \(c(\mathbf{x})\)는 image \(\mathbf{x}\)에 대한 class label이고, \(\hat{c}(\cdot)\)은 predicted label이다.
여기에 전제되어 있는 가정은 학습된 embedding이 알려지지 않은 category에 속하는 image들간에 distance를 측정하는데 유용하게 활용할 수 있게끔 generalize될 수 있다는 것이다. 사실 이 개념은 transfer-learning에서도 pre-trained model를 적용하는 과정에서 정의한 가정과 동일한 것이다. 예를 들어 ImageNet으로 pre-train된 model로 학습시킨 convolutional feature들도 사실 다른 image classification task에서도 잘 동작할 것으로 생각하는 것과 같은 것이다. 하지만 차이가 있다면, transfer-learning에서 pre-train된 model을 사용함으로써 얻는 장점이 model이 학습되면서 새로운 task가 기존의 task에서 멀어지면 멀어질수록 떨어진다는 것이다.
Matching Networks
Matching Networks (Vinyals et al, 2016)는 적은 양의 support set \( S=\{x_i, y_i\}_{i=1}^k \) (k-shot classification)을 가지고 classifier \(c_{S}\)를 학습시키는 방법이다. 이 classifier는 주어진 test sample image \(\mathbf{x}\)에 대해서 output label \(y\)에 대한 probability distribution을 정의한다. 다른 metric-based model과 유사하게, classifier의 출력은 attention kernel \(a(\mathbf{x}, \mathbf{x}_{i})\)에서 weight가 가해져 있는 support sample의 label sum으로 정의되어 있는데, 이때 attention kernel의 값은 image \(\mathbf{x}\)와 \(\mathbf{x}_{i}\)사이의 유사한 정도와 비례해야 한다.

$$ c_S(\mathbf{x}) = P(y \vert \mathbf{x}, S) = \sum_{i=1}^k a(\mathbf{x}, \mathbf{x}_i) y_i
\text{, where }S=\{(\mathbf{x}_i, y_i)\}_{i=1}^k $$
여기서 attention kernel은 두개의 embedding function인 \(f\)와 \(g\)에 따라서 달라지는데, \(f\)는 test sample을 embedding vector로 encoding해주는 함수이고, \(g\)는 support sample을 embedding vector로 encoding해주는 함수이다. 이 때 두 data point간의 attention weight는 두개의 embedding vector간의 cosine similarity \(\text{cosine}(.)\) 이고, 최종적으로는 softmax에 의해서 normalize되게 된다.
$$ a(\mathbf{x}, \mathbf{x}_i) = \frac{\exp(\text{cosine}(f(\mathbf{x}), g(\mathbf{x}_i))}{\sum_{j=1}^k\exp(\text{cosine}(f(\mathbf{x}), g(\mathbf{x}_j))} $$
Simple Embedding
Embedding function이란 개념이 나오는데, 간단하게 말해서 single data sample을 하나의 input으로 받는 neural network을 말한다. 잠재적으로는 \(f\)와 \(g\)을 동일하게 취급할 수 있다.
Full Context Embeddings
Embedding vector는 좋은 classifier를 만드는데 있어 중요한 입력이라고 볼 수 있다. 그래서 전체 feature space를 효율적으로 정의하는데 있어서 single data point만 가지고 입력으로 하기에는 충분하지 않을 것이다. 그렇기 때문에, Matching Network model은 원래의 input에 덧붙여서 전체 support set \(S\)을 입력으로 집어넣음으로써 embedding function의 성능을 개선하는 방향을 제안했다. 이를 통해서 학습된 embedding function은 다른 support sample들과의 관계를 활용해서 보정될 수가 있다.
- \(g_{\theta}(\mathbf{x}_i, S)\)는 전체 support set \(S\)의 맥락에 맞춰 \(\mathbf{x}_i\)을 encoding하기 위해서 bidirectional LSTM을 사용한다.
- \(f_{\theta}(\mathbf{x}, S)\)는 전체 support set \(S\)에 대한 read attention를 활용해서 LSTM을 통해서 test sample \(\mathbf{x}\)를 encoding한다.
1) 우선 test sample은 기본적인 feature \(f'(\mathbf{x}\) 을 뽑아내기 위해서, CNN과 같은 간단한 neural network에 통과시킨다.
2) 그러면 LSTM은 hidden state의 일부 영역에서 support set에 대한 read attention vector를 학습한다.
$$ \begin{align} \hat{\mathbf{h}}_t, \mathbf{c}_t &= \text{LSTM}(f'(\mathbf{x}), [\mathbf{h}_{t-1}, \mathbf{r}_{t-1}], \mathbf{c}_{t-1}) \\
\mathbf{h}_t &= \hat{\mathbf{h}}_t + f'(\mathbf{x}) \\
\mathbf{r}_{t-1} &= \sum_{i=1}^{k} a(\mathbf{h}_{t-1}, g(\mathbf{x}_i))g(\mathbf{x}_i) \\
a(\mathbf{h}_{t-1}, g(\mathbf{x}_i)) &= \text{softmax}(\mathbf{h}_{t-1}^\top g(\mathbf{x}_i)) = \frac{\exp(\mathbf{h}_{t-1}^\top g(\mathbf{x}_i))}{\sum_{j=1}^k \exp(\mathbf{h}_{t-1}^\top g(\mathbf{x}_j))} \end{align} $$
3) 결과적으로 "read"를 K번 수행할 경우 \(f(\mathbf{x}, S) = \mathbf{h}_{K}\) 라는 함수를 구할 수 있게 된다.
이런 embedding 방식을 "Full Contextual Embeddings (FCE)" 이라고 부른다. 흥미로운 것은 (Mini ImageNet model로 few-shot classification을 하는 것과 같은) 어려운 task에 대해서도 성능을 높일 수 있다는 것이다. 반면, (Omniglot 같은) 간단한 task에서는 별 차이가 없다.
Matching Networks에서의 training process는 test time 동안에도 inference를 수행할 수 있도록 설계되어 있는데, 자세한 내용은 앞의 "Training in the same way as testing" 부분을 참고하면 좋을거 같다. 여기서 기억하면 좋을 것은 Matching Networks 자체가 training condition과 testing condition을 맞춰야 한다는 생각을 잘 다듬었다는 것이다.
$$ \theta^{*} = \arg \max_{\theta} \mathbb{E}_{L\subset\mathcal{L}}[ \mathbb{E}_{S^L \subset\mathcal{D}, B^L \subset\mathcal{D}} [\sum_{(\mathbf{x}, y)\in B^L} P_\theta(y\vert\mathbf{x}, S^L)]] $$
Relational Network
Relational Network (RN) (Sung et al, 2018) 은 앞에서 언급했던 Siamese network와 유사하긴 하지만, 몇가지 부분에서 차이가 좀 있다.
- Relationship은 Siamese에서는 간단한 L1 Distance를 통해서 구했었는데, RN에서는 그렇게 구하지 않고, CNN Classifier \( g_{\phi} \)에 의해서 predict된다. 이 때 relation score는 입력으로 들어온 \(\mathbf{x}_i\)와 \(\mathbf{x}_{j}\)사이에 대해서 계산하게 되는데, 다음과 같이 구할 수 있다.
$$ r_{ij} = g_{\phi}([ \mathbf{x}_i, \mathbf{x}_j]) $$
( 참고로 \( [ \cdot , \cdot ] \)은 두개의 data를 concatenate시키는 것이라고 보면 된다.) - Siamese Network에서는 objective function을 Cross-entropy를 사용했었지만, 여기서는 MSE Loss를 사용했는데, 그 이유는 이론적으로 놓고 봤을때 RN 자체가 binary classification에 썼던 Loss \( \mathcal{L}(B) = \sum_{(\mathbf{x}_i, \mathbf{x}_j, y_i, y_j) \in B} (r_{ij} - \mathbf{1}_{ y_i = y_j })^2 \) 보다는 regression시 적합한 relation score를 예측하는 것에 초점을 맞추고 있기 때문이다.

(참고로 DeepMind에서 제안한 relational reasoning을 위한 Relational Network이 따로 존재한다. 이것과 위의 내용과는 다른 개념이다.)
Prototypical Networks
Prototypical Networks (Snell, Swersky & Zemel, 2017) 에서는 각 입력을 M-dimensional feature vector로 encode하기 위해서 embedding function \(f_{\theta}\)를 사용했다. 여기서 전체 class \(C\)에 속하는 모든 class \(c\)에 대한 prototype feature vector를 정의할 수 있는데, 이 vector는 해당 class에 속하는 embedded support data sample들에 대한 mean vector라고 보면 된다.
$$ \mathbf{v}_c = \frac{1}{|S_c|} \sum_{(\mathbf{x}_i, y_i) \in S_c} f_\theta(\mathbf{x}_i) $$

주어진 test input \(\mathbf{x}\)에 대한 class의 distribution은 test data embedding vector와 prototype feature vector간의 distance의 inverse에 대해서 softmax를 취한 것과 같다.
$$ P(y=c\vert\mathbf{x})=\text{softmax}(-d_\varphi(f_\theta(\mathbf{x}), \mathbf{v}_c)) = \frac{\exp(-d_\varphi(f_\theta(\mathbf{x}), \mathbf{v}_c))}{\sum_{c' \in \mathcal{C}}\exp(-d_\varphi(f_\theta(\mathbf{x}), \mathbf{v}_{c'}))} $$
여기서 \( d_\varphi \)는 \(\varphi\)가 미분가능한 모든 distance function을 쓸 수 있다. 논문상에서는 squared euclidean distance를 사용했다. 그리고 논문에서는 Loss fuction을 negative log-likelihood를 사용했다.
$$ \mathcal{L}(\theta) = -\log P_\theta(y=c\vert\mathbf{x}) $$
Model-Based Approach
Model-based meta-learning은 \( P_{\theta}(y|\mathbf{x})\)와 같은 형식에서 어떠한 가정을 삽입하지 않는다. 대신에 fast-learning에 특화된 model의 영향을 많이 받는데, 이때 model은 몇번의 training step만 가지고도 network parameter를 빠르게 학습할 수 있는 형태를 나타낸다. 보통 이렇게 parameter를 빠르게 구하는 방식은 내부 구조를 통해서 얻을 수 있거나 또다른 meta-learner 모델을 통해서 제어가 된다.
Memory-Augmented Neural Networks (MANN)
이 형태를 가진 architecture는 Neural Turing Machine (NTM)나 Memory Network를 포함해서, neural network의 학습을 빠르게 하는데 있어, 외부 memory storage를 사용한다. 이렇게 storage buffer를 통해서, network은 새로운 정보에 대해서는 빠르게 이해할 수 있고, 미래에도 이 정보들을 잊지 않고 가지고 있을 수 있다. 이런 model들을 "Memory-Augmented Neural Network", 줄여서 MANN이라고 한다. 참고로 vanilla RNN이나 LSTM같이 internal memory만 사용하는 recurrent neural network은 MANN에 포함되지 않는다.
MANN이 새로운 정보를 빠르게 encoding하고, 몇 개의 sample만 가지고도 새로운 task에 적용할 수 있도록 설계되었기 때문에, meta-learning에 적합한 구조이다. Neural Turing Machine (NTM)을 base model로 삼으면서, Santoro et al. (2016) 에서는 training setup과 memory retrieval mechanism (혹은 "addressing mechanism"이라고 표현되기도 하는데, 이는 attention weight들이 memory vector에 어떻게 할당되는지 결정하는 규칙이라고 보면 좋을거 같다.)에 대해서 약간의 수정을 가했다. 혹시 넘어가기에 앞서서 이런주제에 대해서 익숙하지 않다면, 원저자가 쓴 포스트 중 NTM section을 살펴보고 넘어갈 것을 권한다.
빠르게 복습하자면, NTM은 controller neural network에 external memory storage를 묶은 형태로 되어 있다. 이 때, controller는 soft attention을 통해서 memory row에 읽고 쓰는 방법을 학습한다. 반면 memory는 일종의 지식 창고(knowledge repository)처럼 활용된다. 여기서 attention weight는 content-based와 location-based로 정의된 나름의 addressing mechanism에 의해서 결정된다.
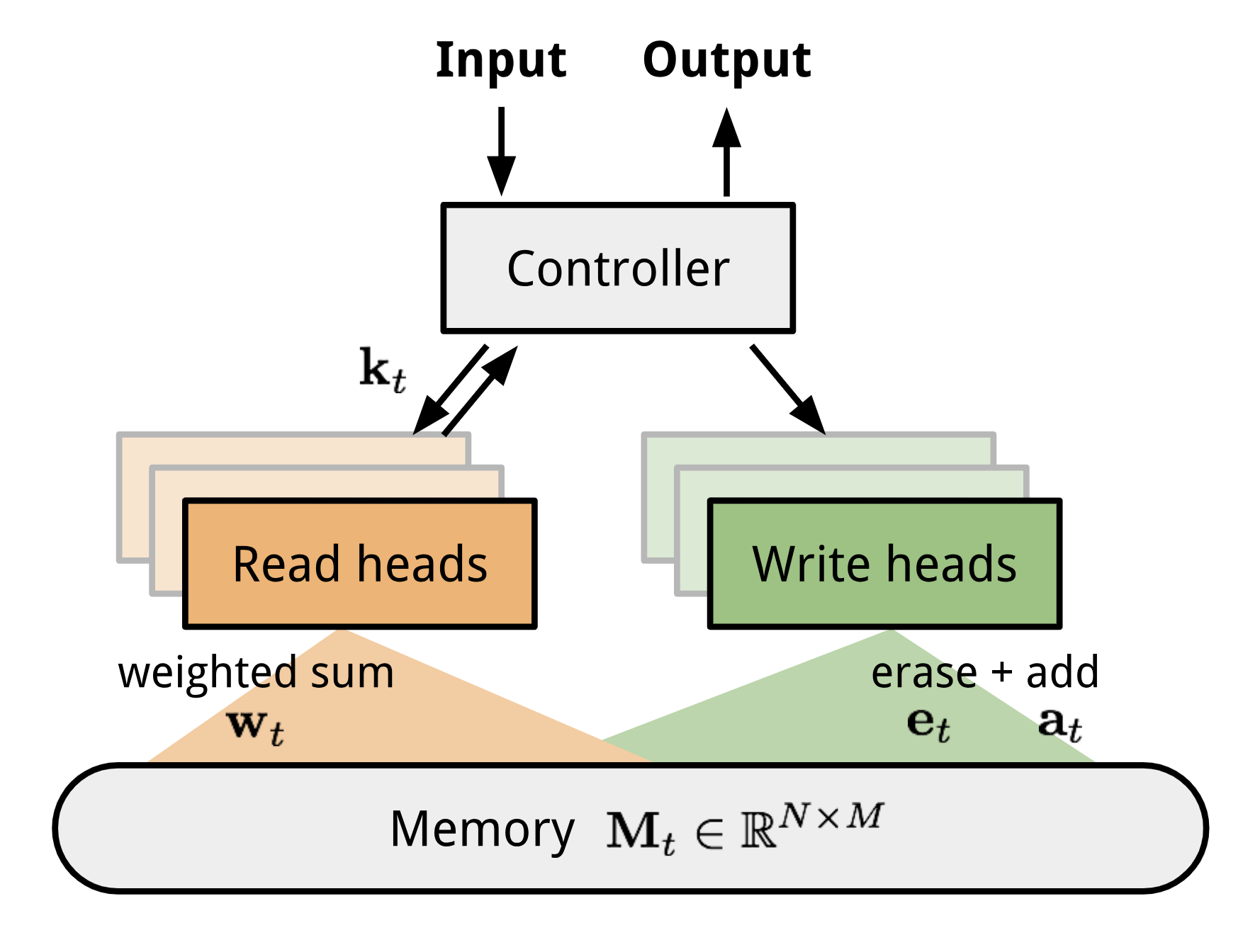
MANN for Meta-Learning
MANN을 meta-learning task에 활용하기 위해서는, memory가 새로운 task에 대한 정보를 빠르게 encoding하고 얻어내는 방법을 이용해서 학습이 되어야 하며, 반면 저장된 representation에 대해서도 쉽고, 안정적으로 접근이 가능해야 한다.
Santoro et al, 2016 에서 기술되어 있는 학습 과정에서는 적절한 label이 나중에라도 등장할 때까지 계속 memory가 정보를 가지고 있게끔 하는 방법이 포함되어 있다. 그래서 매 training episode마다, true label \(y_t\)는 \((\mathbf{x}_{t+1}, y_{t})\)와 같이 one step offset \(\mathbf{x}_{t+1}\)과 함께 나타나게 되는데, 이를 통해서 이전 time step \(t\)에서는 true label이 input으로 들어가지만, time step \(t+1\)에서는 input의 일부로 나타나게 되는 것이다.

이렇게 하면, MANN은 새로운 dataset에 대한 정보를 기억하게끔 동작하게 되는데, 그 이유는 memory가 현재 input에 대한 label이 나중에 나올때까지는 input을 계속 가지고 있어야 하고, 그런 후에는 여기에 맞춰서 prediction을 할때 이전에 저장된 정보를 다시 가져올 수 있어야 하기 때문이다.
다음 파트에서 memory에 어떻게 효율적으로 정보를 가져오고 저장하는지를 살펴보자.
Addressing Mechanism for Meta-Learning
training process와 다른 측면으로, 현재의 model을 meta-learning에 맞게끔 만들기 위해서 새로운 content-based addressing mechanism이 적용되었다.
How to read from memory?
Read Attention은 순전히 content similarity에 기반해서 생성된다.
우선, time step \(t\)마다 key feature vector \(k_{t}\)가 controller network에 의해서 생성되는데, 이때의 형태는 \(\mathbf{x}\)를 input으로 받는 함수의 형태를 띈다. NTM과 유사하게 \(N\)개의 element에 대한 read weighting vector \(w_{t}^{r}\)는 key vector와 memory내 모든 vector row에 대한 cosine similarity를 통해서 구할 수 있고, 최종적으로는 softmax에 의해서 normalize가 된다. 그러면 결과적으로 read vector \(r_t\)는 아래의 수식과 같이 모든 memory record에 대해서 weight가 가해진 것들의 합으로 표현할 수 있게 된다.
$$ \mathbf{r}_t = \sum_{i=1}^N w_t^r(i)\mathbf{M}_t(i)
\text{, where } w_t^r(i) = \text{softmax}(\frac{\mathbf{k}_t \cdot \mathbf{M}_t(i)}{\|\mathbf{k}_t\| \cdot \|\mathbf{M}_t(i)\|}) $$
위 식에서 \(M_t\)는 \(t\) time에서의 memory matrix를 말하고, \(M_t(i)\)는 해당 matrix의 i번째 row를 나타내는 것이다.
How to write into memory?
새롭게 얻은 정보를 memory에 write하는 것에 대한 addressing mechanism은 cache replacement policy와 많이 유사하다. 그 중 Least Recently Used Access (LRUA) writer는 MANN이 meta-learning환경에서 잘 동작할 수 있도록 설계되었다. LRUA writer는 새로운 정보를 memory내에서 가장 적게 사용된(least used) 영역에 쓰거나 혹은 가장 최근에 쓰여진(most recently used) 영역에 쓰게 된다.
- 적게 써진 영역 : 이를 통해서 자주 사용된 정보를 보존할 수 있다. (LFU 참고)
- 가장 최근에 써진 영역 : 한번 정보를 가지고 오면, 일반적으로 잠깐동안은 다시 불러오지 않는 부분에서 착안했다. (MRU 참고)
이외에도 많은 cache replacement algorithm들이 있고, 다른 케이스 상에서 더 좋은 성능을 보일 수 있도록 위의 algorithm을 대체할 수 있다. 확실히 자기 마음대로 memory addressing을 하는 것보다는 memory usage pattern과 addressing strategy를 학습하는 것은 좋은 방법이다.
LRUA에서는 모든 변수들이 미분 가능하다는 부분에서 과정을 수행하게 된다.
- time \(t\)에서의 usage weight \( \mathbf{w}^u_t\)는 현재의 read vector와 write vector들의 합에다가 이전의 usage weight에 감쇄된 형태 ( \( \gamma \mathbf{w}^u_{t-1} \))를 가한 식으로 표현된다. 여기서 \(\gamma\)는 decay factor이다.
$$ \mathbf{w}_t^u = \gamma \mathbf{w}_{t-1}^u + \mathbf{w}_t^r + \mathbf{w}_t^w $$ - Read vector는 앞에서 잠깐 언급했던 바와 같이 key vector와 모든 memory row간의 cosine similarity를 계산하고, 최종적으로 softmax로 normalize된 형태로 나타난다.
$$ \mathbf{w}_t^{r} = \text{softmax}( \text{cosine} (k_t, M_t(i))) $$ - Write vector는 이전의 read weight vector (혹은 "가장 최근에 사용된 영역")와 이전의 덜 사용된 weight 들간의 interpolation으로 나타난다. 이때 interpolation을 결정짓는 parameter는 hyperparameter \(\alpha\)를 가지는 sigmoid 함수이다.
$$ \mathbf{w}_t^{w} = \sigma(\alpha) \mathbf{w}_{t-1}^r + (1 - \sigma(\alpha)) \mathbf{w}_{t-1}^{lu} $$ - 위 식에서 잠깐 나온 least-used weight \(\mathbf{w}^{lu}\)는 usage weight \(\mathbf{w}_t^u\)에 scale된 형태로 나타나는데, 이때 특정 dimension이 vector내에서 n번째로 작은 것보다도 더 작으면 1이 되고, 아니면 0이 되는 식이다.
$$ \mathbf{w}_t^{lu} = \mathbf{1}_{ w_{t}^{u}(i) \le m(\mathbf{w}_t^u, n)} \text{, where } m(\mathbf{w}_t^u, n) \text{ is the }n\text{-th smallest element in vector } \mathbf{w}_t^u \text{.} $$
최종적으로는 \( \mathbf{w}_t^{lu} \)에 의해서 지정된 least used memory location은 0으로 설정되고, 그 나머지 memory row들은 다음과 같이 update된다.
$$ M_t(i) = M_{t-1}(i) + w_{t}^w(i) k_t , \forall i$$
Meta Networks
Meta Networks (Munkhdalai & Yu, 2017)은 짧게 줄여서 MetaNet이라고 표현하는데, 전반적인 task에 대한 rapid generalization을 하게끔 내부 training process가 설계된 meta-learning model이다.
Fast Weights
MetaNet에서 rapid generalization이 되게끔 하는 것은 "fast weights"라는 것 때문이다. 이 주제에 대한 논문들이 많이 나와 있지만, 원저자도 이걸 전부 읽어보지 못했고, 개념에 대한 좀 애매한 정의만 할 수 있을 뿐, 뭔가 정확한 정의를 찾을수는 없었다고 한다. 일반적으로 neural network의 weight는 object function에 대한 stochastic gradient descent에 의해서 update되는 것으로 알고 있고, 이 과정 자체가 매우 느리다는 것으로 알려져 있다. 이런 학습 과정을 빠르게 하기 위한 방법 중 하나는 다른 neural network의 parameter를 예측할 수 있는 또하나의 neural network을 사용하자는 것이고, 이를 통해서 만들어진 weight를 fast weight라고 표현하는 것 같다. 반면 기존 SGD 방식으로 만든 weight를 slow weight라고 한다.
MetaNet에서는, loss gradient가 바로 앞에서 언급한 fast weights들을 학습하는 새로운 모델을 만들어내기 위한 meta information으로 사용된다. 그리고 slow weight와 fast weight들이 neural network에서 prediction을 수행하기 위해 결합되는 형태로 되어 있다.

Model Components
참고로, 밑에 나올 표현들이 논문에 나와있는 것과 다른 것을 볼 수 있을텐데, 원 저자가 생각하기에는 논문의 아이디어 자체는 참 좋지만, 논문이 이해하기 어렵게 써졌다고 하는 것 같다. 그래서 아래에서는 나름 본인이 생각한 방향대로 기술될 예정이다.
MetaNet을 구성하는 핵심 요소는 다음과 같다.
- \(\theta\)에 의해서 조절되는 embedding function \(f_{\theta}\)가 있는데, 이는 raw input을 feature vector로 encoding해주는 역할을 한다. 앞에서 언급했던 Siamese Neural Network와 유사하게, 이 embedding vector는 두개의 input이 같은 class에 속하는지 여부를 알려주는데 유용하게끔 학습이 된다. (마치 verification task처럼 말이다.)
- Weight \(\phi\)에 의해서 조절되는 base learner model \(g_{\phi}\)가 있는데, 이는 실제 learning task를 마무리하는 역할을 한다.
여기까지만 놓고 보면, 앞에서 언급했던 Relation Network와 거의 똑같은 것처럼 보일 것이다. MetaNet은 여기에 덧붙여서 embedding function과 learner model 에 대한 fast weights를 모델링하고, 이를 모아서 다시 mode에 넣어주는 부분이 추가되었다. (그림 8 참고)
결과적으로 embedding function \(f\)와 learner model \(g)\ 각각의 fast weights들을 output으로 내보내주는 두개의 함수가 추가로 필요하게 된다.
- \(F_w\) : embedding function \(f\)의 fast weight \(\theta^{+}\)을 학습하기 위한 LSTM이고 \(w\)에 의해서 조절된다. verification task를 위해서, input으로는 \(f\)의 embedding loss에 대한 gradient를 받는다.
- \(G_v\) : base learner \(g\)의 loss gradient로부터 fast weight \(\theta^{+}\)을 학습하기 위한 neural network이고, \(v\)에 의해서 조절된다. MetaNet에서는 learner의 loss gradient는 task에 대한 meta information으로 정의된다.
이제 meta network이 이떻게 학습되는지 살펴보자. 학습 데이터에는 여러 pair의 dataset들이 포함되어 있는데, 앞에서도 계속 나왔던 support set \( S=\{\mathbf{x}'_i, y'_i\}_{i=1}^K \) 와 test set \( U=\{\mathbf{x}_i, y_i\}_{i=1}^L \) 들이 그 것들이다. 다시한번 우리는 4개의 network와 학습을 위한 4개의 model parameter \( ( \theta, \phi, w, v ) \) 가 있는 것을 기억해보자.

Training Process
1. 우선 support set \(S\)으로부터 매 time step \(t\)마다 input으로 사용할 random pair를 sampling 한다. 그리고 이를 \((\mathbf{x}_i', y_i')\)와 \((\mathbf{x}_j', y_j)\) 라고 하자. 그리고 \(\mathbf{x}_{(t,1)} = \mathbf{x}_i', \mathbf{x}_{(t,2)} = \mathbf{x}_j'\) 라고 정의해보자.
그리고 매 \(t = 1, \ldots, K\)에 대해서,
1) representation learning에 대한 loss를 계산해보자. 예를 들어 verification task에 대한 cross entropy를 구하면, 다음과 같다.
$$ \mathcal{L}^\text{emb}_t = \mathbf{1}_{y'_i=y'_j} \log P_t + (1 - \mathbf{1}_{y'_i=y'_j})\log(1 - P_t)\text{, where }P_t = \sigma(\mathbf{W}\vert f_\theta(\mathbf{x}_{(t,1)}) - f_\theta(\mathbf{x}_{(t,2)})\vert) $$
2. 이제 loss를 가지고 task-level fast weights를 계산해본다.
$$ \theta^{+} = F_w(\nabla_{\theta} \mathcal{L}^\text{emb}_1 ,\ldots, \mathcal{L}^\text{emb}_T) $$
3. 다음으로 support set \(S\)에서 example을 뽑아 example-level fast weight를 계산한다. 이번에는 학습된 representation을 바탕으로 memory를 update한다.
그리고 매 \(i = 1, \ldots, K\)에 대해서,
1) base learner는 probability distribution을 output으로 내보낸다. (\(P(\hat{y_i}|\mathbf{x}_i) = g_{\phi}(\mathbf{x}_i)\)) 이때의 loss는 cross-entropy나 MSE를 쓸수 있다.
$$ \mathcal{L}^\text{task}_i = y'_i \log g_\phi(\mathbf{x}'_i) + (1- y'_i) \log (1 - g_\phi(\mathbf{x}'_i)) $$
2) task에 대한 meta information(loss gradient)를 뽑아내고, 이를 통해서 example-level fast weight를 계산한다.
$$ \phi_i^{+} = G_v(\nabla_{\phi}\mathcal{L}_i^{\text{task}}) $$
-> 이렇게 얻은 \( \phi_u^{+} \)를 "value" memory \(M\)의 i번째 row에 저장한다.
3) 앞에서 사용했던 support set의 sample을 task-specific input representation으로 encoding하는데, 이때 앞에서 구한 slow weight와 fast weight를 활용한다.
$$ r_i' = f_{\theta, \theta^{+}}(\mathbf{x}_i') $$
-> 이렇게 얻은 \( r_i' \)를 "key" memory \(R\)의 i번째 row에 저장한다.
4. 마지막으로 test set \(U = \{\mathbf{x}_i, y_i\}_{i=1}^L \)를 이용해서 training loss를 만들 차례이다.
우선 \(\mathcal{L}_{\text{train}} = 0\)에서 시작한다.
그리고 매 \(j = 1, \ldots, L\)에 대해서,
1) test sample을 task-specific input representation으로 encoding 해준다.
$$ r_j = f_{\theta, \theta^{+}}(\mathbf{x}_j) $$
2) 여기서 fast weight는 "key" memory \(R\)에 저장된 support set sample의 representation을 통해서 계산할 수 있는데, 이때 사용되는 attention function은 어떤 것을 선택해도 된다. MetaNet논문에서는 cosine similarity를 사용했다.
$$ \begin{aligned}
a_j &= \text{cosine}(\mathbf{R}, r_j) = [\frac{r'_1\cdot r_j}{\|r'_1\|\cdot\|r_j\|}, \dots, \frac{r'_N\cdot r_j}{\|r'_N\|\cdot\|r_j\|}]\\
\phi^+_j &= \text{softmax}(a_j)^\top \mathbf{M}
\end{aligned} $$
3) 이제 training loss를 update한다.
$$ \mathcal{L}_{\text{train}} \leftarrow \mathcal{L}_{\text{train}} + \mathcal{L}^{\text{task}}(g_{\phi, \phi^{+}}(\mathbf{x}_i), y_i) $$
5. 최종적으로 \(\mathcal{L}_{\text{train}}\)을 이용해서 \((\theta, \phi, w, v)\)을 update한다.
Optimization-Based Approach
Deep learning model은 gradient에 대한 backpropagation을 통해서 학습한다. 하지만 이런 gradient-based optimization은 적은 수의 training sample을 다루기 위해서 만들어진 것이 아닐뿐더러, 적은 optimization step내에서 converge되지 않는다. Optimization algorithm을 수정해서 적은 수의 example만 가지고 model이 잘 학습할 수 있는 방법이 있을까? 그것이 바로 optimization-based approach가 적용된 meta-learning algorithm이 지향하는 목표이다.
LSTM Meta-Learner
사실 optimization algorithm은 확실하게 모델링할 수 있다. Ravi & Larochelle (2017)는 task를 다루는 original model을 "learner"라고 부르는데에서 가져와, 이런 방식을 "meta-learner"라고 이름을 붙였다. Meta-learner의 목표는 적은 support set만 가지고도 learner의 parameter를 효율적으로 update해서 learner가 새로운 task에 빠르게 적응할 수 있도록 하는 것이다.
앞으로 나올 표현 중 \(\theta\)에 의해서 조절되는 learner를 \(M_{\theta}\)라고 하고, \(\Theta\)에 의해서 조절되는 meta-learner를 \(R_{\Theta}\)라고 하며, 이때의 Loss function을 \(\mathcal{L}\)이라고 하겠다.
Why LSTM?
Meta-learner는 LSTM으로 모델링되어 있는데 그 이유는 다음과 같다.
- Backpropagation에서 gradient-based update 방식과 LSTM에서 cell-update하는 방식이 어느정도 유사성을 띄고 있다.
- Gradient가 어떻게 변화하는지 정보를 아는 것은 gradient를 update할 때 도움을 줄 수 있다. 한번 momentum이 어떻게 동작하는지 생각해보면 좋을거 같다.
time step \(t\)에 learning rate \(\alpha_t\)를 가지고 learner의 parameter를 update하는 것은 다음과 같이 표현할 수 있다.
$$ \theta_t = \theta_{t-1} - \alpha_t \nabla_{\theta_{t-1}} \mathcal{L}_t $$
LSTM에서 cell state를 update하는 것도 위 식과 같은 형태를 가지고 있는데, 예를 들어 forget gate \(f_t\)를 1로 설정한 상태에서 input gate \(i_t\)에 \(\alpha_t\)를 넣고, cell state \(c_t\)에 \(\theta_t\)를 넣고, new cell state \( \tilde{c}_t \)를 \( -\nabla_{\theta_{t-1}}\mathcal{L}_t \)라고 정의하게 되면 cell state는 다음과 같이 정의할 수 있다.
$$ \begin{aligned}
c_t &= f_t \odot c_{t-1} + i_t \odot \tilde{c}_t\\
&= \theta_{t-1} - \alpha_t\nabla_{\theta_{t-1}}\mathcal{L}_t
\end{aligned} $$
\(f_t = 1, i_t = \alpha_t \)로 고정을 해버리면 그렇게 optimal하지는 않지만, 두개의 항 모두 다른 dataset에 대해서 learnable하고, adaptable하게 된다.
$$ \begin{aligned}
f_t &= \sigma(\mathbf{W}_f \cdot [\nabla_{\theta_{t-1}}\mathcal{L}_t, \mathcal{L}_t, \theta_{t-1}, f_{t-1}] + \mathbf{b}_f) & \scriptstyle{\text{; how much to forget the old value of parameters.}}\\
i_t &= \sigma(\mathbf{W}_i \cdot [\nabla_{\theta_{t-1}}\mathcal{L}_t, \mathcal{L}_t, \theta_{t-1}, i_{t-1}] + \mathbf{b}_i) & \scriptstyle{\text{; corresponding to the learning rate at time step t.}}\\
\tilde{\theta}_t &= -\nabla_{\theta_{t-1}}\mathcal{L}_t &\\
\theta_t &= f_t \odot \theta_{t-1} + i_t \odot \tilde{\theta}_t &\\
\end{aligned} $$
Model Setup
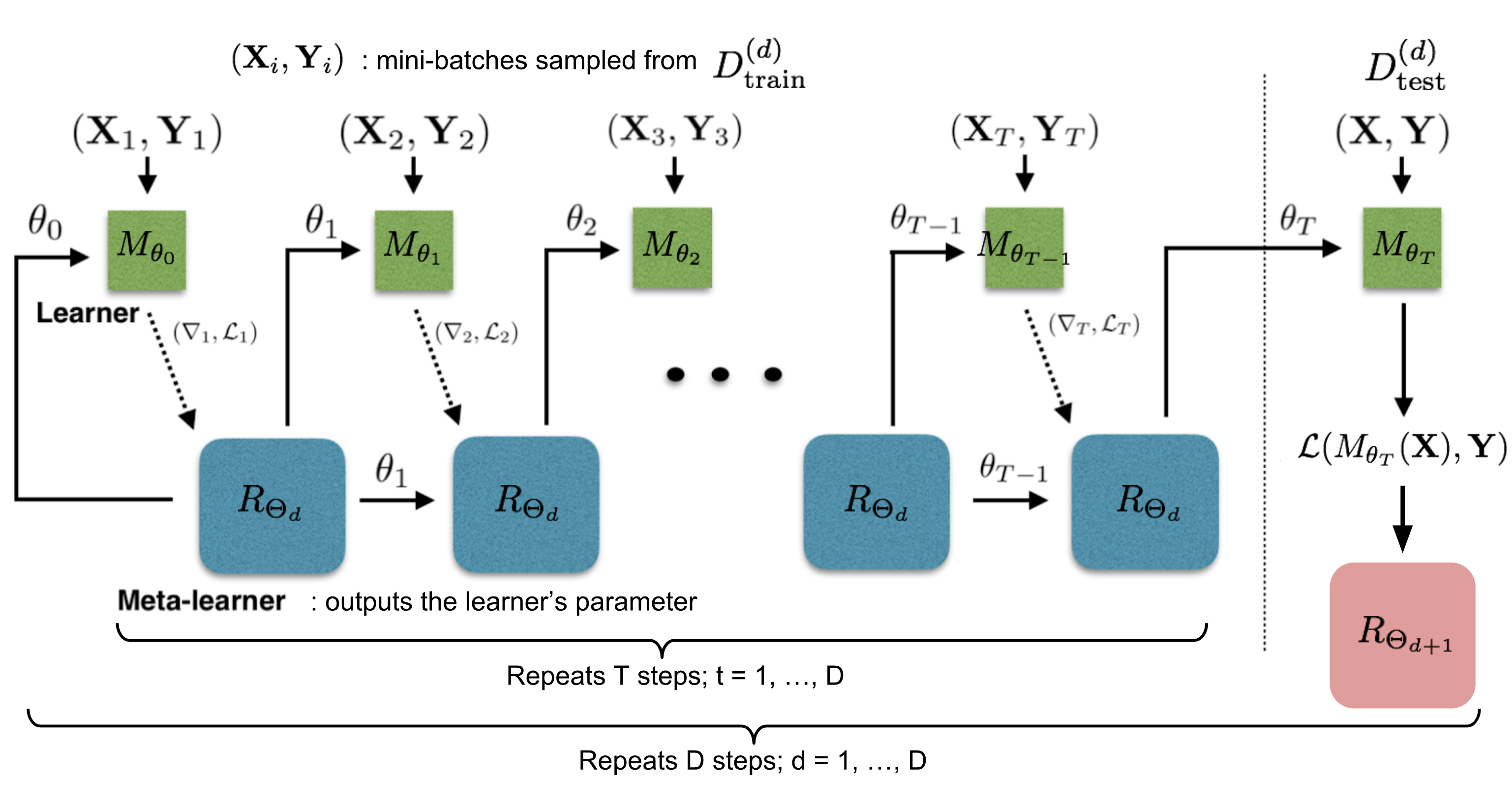
Training process는 test process에서 일어난 일들을 모방하는데, 이런 방식은 앞에서 소개했던 Matching Network에서도 이미 좋다고 증명된 방식이다. 매 training epoch동안, 먼저 data \( \mathcal{D} = (\mathcal{D}_\text{train}, \mathcal{D}_\text{test}) \in \hat{\mathcal{D}}_\text{meta-train} \) 을 sampling하고, \(T\) round동안 \( \theta\)를 update하기 위해서 \( \mathcal{D}_\text{train} \) 중 일부를 mini-batch만큼 sampling한다. 그리고 learner parameter \(\theta_T\)의 final state는 test data set \( \mathcal{D}_{\text{test}} \) 을 이용해서 meta-learner를 학습시키는데 사용한다.
meta-learner의 구현부분중 조금 더 신경써야 할 부분은 다음과 같다.
- LSTM meta-learner에서 parameter space를 어떻게 하면 줄일수 있을까 이다. meta-learner가 현재의 model이 아닌 또다른 neural network의 parameter를 가지고 학습하는 이상, 학습에 있어서 엄청 많은 parameter variable들이 존재할 것이다. 이 문제에 대해서는 coordinate기반으로 parameter를 공유하는 방식을 적용한 다음 논문을 참고해보면 좋을거 같다.
- Training process를 간단히하기 위해서 meta-learner는 사전에 loss \(\mathcal{L}_t\)와 gradient \(\nabla_{\theta_{t-1}} \mathcal{L}_t\) 가 independent하다고 가정을 둔다.
위의 내용을 하나의 과정으로 표현하면 다음과 같다.

Model-Agnostic Meta-Learning (MAML)
Model-Agnostic Meta-Learning (Finn et al, 2017)을 줄인 MAML은 gradient descent를 통해서 학습하는 어떤 모델에도 적용이 가능한, general optimization algorithm이다.
우선 \(\theta\)에 의해서 조절되는 모델 \( f_\theta\)를 학습시킨다고 가정해보자. 주어진 task \(\tau_i\)와 이와 관련된 dataset \(( \mathcal{D}_{\text{train}}^{(i)}, \mathcal{D}_{\text{test}}^{(i)} )\)가 있을때, 하나나 여러 gradient descent step를 통해서 model의 parameter를 update할 수 있다. (아래 예시는 one step만 표현한 것이다.)
$$ \theta_i' = \theta - \alpha \nabla_{\theta} \mathcal{L}_{\tau_i}^{(0)}(f_\theta) $$
여기서 \( \mathcal{L}^{(0)}\)은 첫번째로 뽑은 mini batch dataset (id = 0)을 사용해서 계산한 loss를 말한다.

아마 잘 아는 사람은 알겠지만, 위의 식은 하나의 task에 대해서만 optimize가 가능하다. 여러 task들을 통틀어서 generalization을 잘 시키기 위해서는 optimal \( \theta^{*}\)를 찾아야 하며, 그래야만, task-specific fine-tuning이 효율적으로 이뤄질 수 있다. 이제 meta-objective를 update하기 위해서 다음 mini batch data (id=1)를 sampling한다. 이때 Loss \(\mathcal{L}^{(1)}\)는 mini batch (id=1)에 따라 결정되게 된다. 참고로 \(\mathcal{L}^{(0)}\)과 \(\mathcal{L}^{(1)}\)의 위에 붙은 첨자는 단순히 서로 다른 mini-batch data를 사용했다는 것을 의미하며, 이 두개의 loss 모두 같은 task에 대해서 같은 loss objective로부터 나온 값이다.
$$ \begin{aligned}
\theta^*
&= \arg\min_\theta \sum_{\tau_i \sim p(\tau)} \mathcal{L}_{\tau_i}^{(1)} (f_{\theta'_i}) = \arg\min_\theta \sum_{\tau_i \sim p(\tau)} \mathcal{L}_{\tau_i}^{(1)} (f_{\theta - \alpha\nabla_\theta \mathcal{L}_{\tau_i}^{(0)}(f_\theta)}) & \\
\theta &\leftarrow \theta - \beta \nabla_{\theta} \sum_{\tau_i \sim p(\tau)} \mathcal{L}_{\tau_i}^{(1)} (f_{\theta - \alpha\nabla_\theta \mathcal{L}_{\tau_i}^{(0)}(f_\theta)}) & \scriptstyle{\text{; updating rule}}
\end{aligned} $$

First-Order MAML (FOMAML)
위에서 설명한 meta-optimization step은 second derivative의 영향을 많이 받는다. 미분을 두번 해야 하기 때문에 computation power가 많이 필요한데 이를 줄이기 위해서, MAML의 수정된 형태는 second derivative를 생략하고, 조금더 더 간단하고, cost가 많이 필요하지 않는 형태로 제시되었는데, 이를 First-Order MAML (FOMAML)이라고 한다.
우선 \(k\)개 (\(k \ge 1\)) 의 inner gradient step 과정을 생각해보자. 초기 model parameter를 \(\theta_{\text{meta}}\)라고 지정했을 때, \(k\) step까지의 parameter update는 다음과 같이 표현할 수 있다.
$$ \begin{aligned}
\theta_0 &= \theta_\text{meta}\\
\theta_1 &= \theta_0 - \alpha\nabla_\theta\mathcal{L}^{(0)}(\theta_0)\\
\theta_2 &= \theta_1 - \alpha\nabla_\theta\mathcal{L}^{(0)}(\theta_1)\\
&\dots\\
\theta_k &= \theta_{k-1} - \alpha\nabla_\theta\mathcal{L}^{(0)}(\theta_{k-1})
\end{aligned} $$
그러면 outer loop에서는 meta-objective를 update하기 위한 새로운 data batch를 sampling할 수 있다.
$$ \begin{aligned}
\theta_\text{meta} &\leftarrow \theta_\text{meta} - \beta g_\text{MAML} & \scriptstyle{\text{; update for meta-objective}} \\[2mm]
\text{where } g_\text{MAML}
&= \nabla_{\theta} \mathcal{L}^{(1)}(\theta_k) &\\[2mm]
&= \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) \cdot (\nabla_{\theta_{k-1}} \theta_k) \dots (\nabla_{\theta_0} \theta_1) \cdot (\nabla_{\theta} \theta_0) & \scriptstyle{\text{; following the chain rule}} \\
&= \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) \cdot \prod_{i=1}^k \nabla_{\theta_{i-1}} \theta_i & \\
&= \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) \cdot \prod_{i=1}^k \nabla_{\theta_{i-1}} (\theta_{i-1} - \alpha\nabla_\theta\mathcal{L}^{(0)}(\theta_{i-1})) & \\
&= \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) \cdot \prod_{i=1}^k (I - \alpha\nabla_{\theta_{i-1}}(\nabla_\theta\mathcal{L}^{(0)}(\theta_{i-1}))) &
\end{aligned} $$
이때 MAML의 gradient는 다음과 같다.
$$ g_\text{MAML} = \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) \cdot \prod_{i=1}^k (I - \alpha \color{red}{\nabla_{\theta_{i-1}}(\nabla_\theta\mathcal{L}^{(0)}(\theta_{i-1}))}) $$
First-Order MAML은 위 식의 빨간색으로 표현된 second derivative term을 무시한다. 이를 통해서 결국 마지막 inner gradient update 결과에 대한 derivative와 같은 형태로 축약되는 것을 확인할 수 있다.
$$ g_\text{FOMAML} = \nabla_{\theta_k} \mathcal{L}^{(1)}(\theta_k) $$
Reptile
Reptile (Nichol, Achiam& Schulman, 2018)은 정말 놀라울 정도로 매우 간단한 meta-learning optimization algorithm이다. MAML과 이 algorithm 모두 gradient descent를 통해서 meta-optimization을 수행하고, model-agnostic 하다는 점에서 상당수 유사한 부분이 있다.
Reptile은 다음 과정을 반복적으로 수행한다.
- Task를 samling한다.
- Multiple Gradient Descent step을 통해 task를 학습한다.
- 새로운 parameter를 얻을 수 있게끔 model weight를 움직인다.
아래 알고리즘을 한번 살펴보자.

여기서 \(\text{SGD}(\mathcal{L}_{\tau_i}, \theta, k) \)는 initial parameter \(\theta\)를 가진 상태에서 Loss \(\mathcal{L}_{\tau_i}\) 에 대한 \(k\) step 동안의 stochastic gradient descent를 수행하고, output으로 final parameter vector를 내보낸다. 그러면 위와 같은 batch 형태는 매 iteration마다 하나가 아닌 여러 task를 sampling한다. 그러면 repile gradient는 \( (\theta - W) / \alpha \)라고 정의할 수 있는데, 이때 \(\alpha\)는 SGD 수행시 사용되는 stepsize를 말한다.
한눈에 보면, 위의 algorithm은 평범한 SGD와 많이 유사하다는 것을 알 수 있다. 하지만, task-specific optimization이 one step 보다 더 걸릴 수 있기 때문에, \(k = 1\)인 상태에서는 \( \mathbb{E}_\tau [\text{SGD}(\mathcal{L}_{\tau}, \theta, k)] \)를 \( \mathbb{E}_\tau [\text{SGD}(\mathcal{L}_{\tau}, \theta, k)] \) 로 바꿀수 있게 된다.
The Optimization Assumption
어떤 task \(\tau \sim p(\tau) \)가 다양한(manifold) optimal network configuration \(\mathcal{W}_{\tau}^*\)를 가지고 있다고 가정해보자. 그러면 현재의 model \(f_{\theta}\)은 \(\theta\)가 \(\mathcal{W}_{\tau}^*\) 에 놓여있을때, task \(\tau\)에 대해서 최고의 성능을 얻을 수 있을 것이다. 그럼 task 전반적으로 잘 동작하는 solution을 찾기 위해서, 일단 모든 task에 대해서 optimal manifold에 가까운 parameter를 찾아야 할 것이다.
$$ \theta^* = \arg\min_\theta \mathbb{E}_{\tau \sim p(\tau)} [\frac{1}{2} \text{dist}(\theta, \mathcal{W}_\tau^*)^2] $$

이제 L2 distance를 사용할텐데 수식상으로는 \(\text{dist}(\dot)\)라고 할 것이고, 기본 전제로 \(\theta\)라는 점과 특정 weight set \( \mathcal{W}_\tau^* \) 사이의 거리는 \(\theta\)와 \(\theta\)와 가장 가까운 manifold상의 점인 \( W_{\tau}^*(\theta) \) 간의 거리가 같다는 가정을 할 것이다.
$$ \text{dist}(\theta, \mathcal{W}_{\tau}^*) = \text{dist}(\theta, W_{\tau}^*(\theta)) \text{, where }W_{\tau}^*(\theta) = \arg\min_{W\in\mathcal{W}_{\tau}^*} \text{dist}(\theta, W) $$
그러면 squared L2 distance (euclidean distance)에 대한 gradient는 다음과 같다.
$$ \begin{aligned}
\nabla_\theta[\frac{1}{2}\text{dist}(\theta, \mathcal{W}_{\tau_i}^*)^2]
&= \nabla_\theta[\frac{1}{2}\text{dist}(\theta, W_{\tau_i}^*(\theta))^2] & \\
&= \nabla_\theta[\frac{1}{2}(\theta - W_{\tau_i}^*(\theta))^2] & \\
&= \theta - W_{\tau_i}^*(\theta) & \scriptstyle{\text{; See notes.}}
\end{aligned} $$
Notes : Reptile 논문에 따르면 " \(\theta\)와 \(S\)간의 squared euclidean distance의 gradient는 \(2(\theta - p)\)라고 표현할 수 있고, 이때 \(p\)는 \(\theta\)와 가장 가까운 S상의 점이다" 라고 표현되어 있다. 엄밀히 말해서는 S상의 가장 가까운 점도 \(\theta\)에 대한 함수이기 때문에, 원저자는 이 gradient수식이 p의 derivative와 상관이 없는지에 대해서 의문을 가지고 있다. (혹시 이에 대해서 생각이 있으면 원저자에게 메일을 보내면 좋을거 같다.)
결국 한 stochastic gradient step에 대한 update는 다음과 같이 진행된다.
$$ \theta = \theta - \alpha \nabla_\theta[\frac{1}{2} \text{dist}(\theta, \mathcal{W}_{\tau_i}^*)^2] = \theta - \alpha(\theta - W_{\tau_i}^*(\theta)) = (1-\alpha)\theta + \alpha W_{\tau_i}^*(\theta) $$
그래서 optimal task manifold \( W_{\tau_i}^*(\theta)\)에 대한 가장 가까운 점은 정확하게 계산할 수는 없지만, Reptile algorithm은 \( \text{SGD}(\mathcal{L}_\tau, \theta, k) \)을 사용해서 그나마 가까운 점을 근사할 수 있다.
Reptile vs FOMAML
Reptile과 MAML간의 관계를 확인해보기 위해서, \(\text{SGD}(\dot)\)상에서 두 개의 gradient step를 update하는 과정 (\(k=2\))을 한번 살펴보자. 참고로 MAML에서 정의한대로 \(\mathcal{L}^{(0)}\)와 \(\mathcal{L}^{(1)}\)은 서로 다른 mini-batch에서 뽑은 data에 대한 loss이다. 수식의 가독성을 위해서 Loss에 대한 gradient를 각각 다음과 같이 표기했다. (\( g^{(i)}_j = \nabla_{\theta} \mathcal{L}^{(i)}(\theta_j), H^{(i)}_j = \nabla^2_{\theta} \mathcal{L}^{(i)}(\theta_j) \))
그러면 위 식에 따른 \(\theta\)에 대한 update는 다음과 같다.
$$ \begin{aligned}
\theta_0 &= \theta_\text{meta}\\
\theta_1 &= \theta_0 - \alpha\nabla_\theta\mathcal{L}^{(0)}(\theta_0)= \theta_0 - \alpha g^{(0)}_0 \\
\theta_2 &= \theta_1 - \alpha\nabla_\theta\mathcal{L}^{(1)}(\theta_1) = \theta_0 - \alpha g^{(0)}_0 - \alpha g^{(1)}_1
\end{aligned} $$
FOMAML에서 설명한 바에 따르면, FOMAML의 gradient는 마지막으로 수행한 inner gradient update의 결과라고 했었다. 그렇기 때문에 \(k=1\)이면 다음과 같이 gradient를 계산할 수 있다.
$$ \begin{aligned}
g_\text{FOMAML} &= \nabla_{\theta_1} \mathcal{L}^{(1)}(\theta_1) = g^{(1)}_1 \\
g_\text{MAML} &= \nabla_{\theta_1} \mathcal{L}^{(1)}(\theta_1) \cdot (I - \alpha\nabla^2_{\theta} \mathcal{L}^{(0)}(\theta_0)) = g^{(1)}_1 - \alpha H^{(0)}_0 g^{(1)}_1
\end{aligned} $$
그리고 Reptile에 대한 gradient는 다음과 같이 정의된다.
$$ g_\text{Reptile} = (\theta_0 - \theta_2) / \alpha = g^{(0)}_0 + g^{(1)}_1 $$
이제 Reptile과 FOMAML의 gradient update 과정을 도식화하면 아래와 같다.
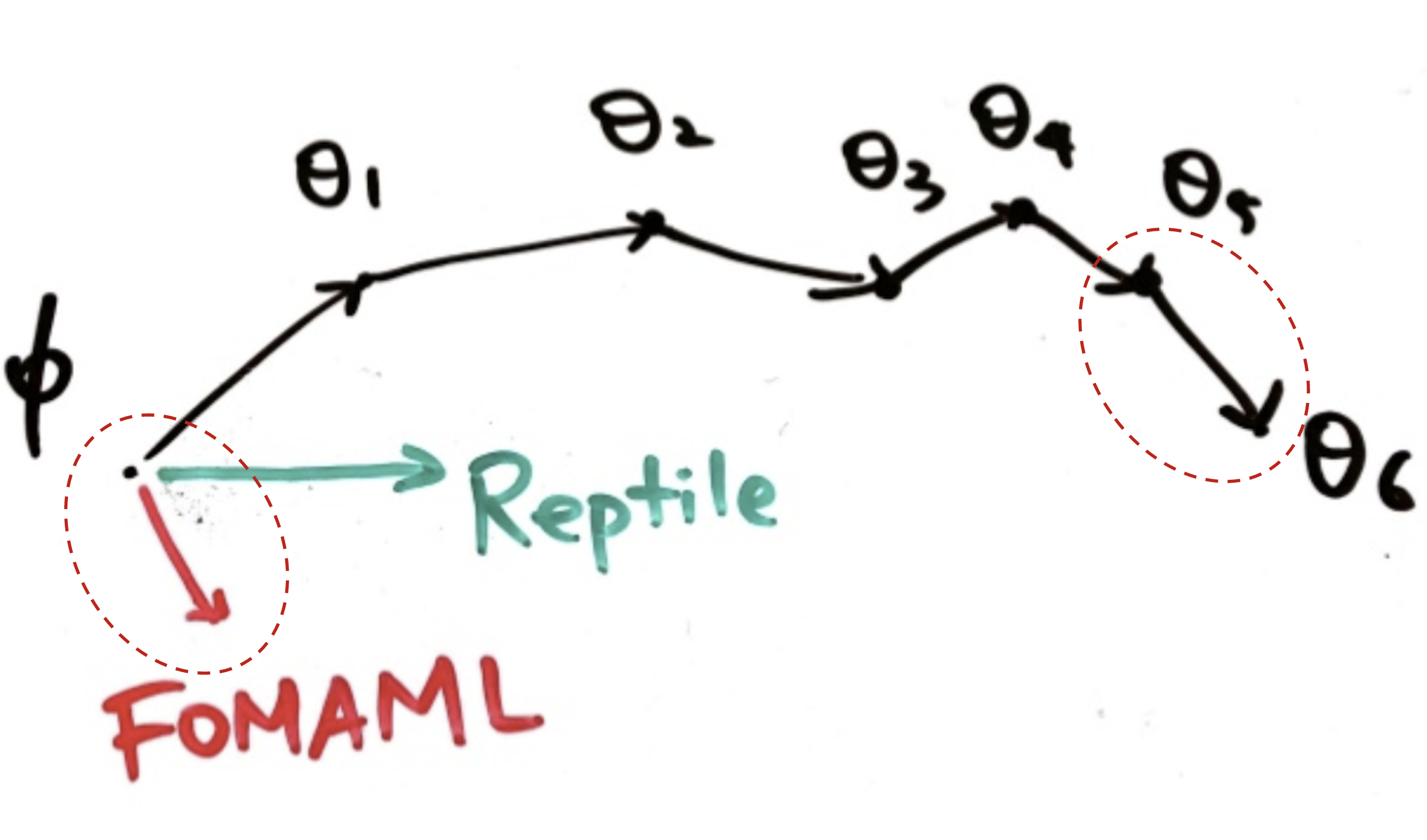
앞의 수식을 요약하면, 우리는 MAML과 FOMAML, Reptile에 대한 gradient을 구할 수 있었다.
$$ \begin{aligned}
g_\text{FOMAML} &= g^{(1)}_1 \\
g_\text{MAML} &= g^{(1)}_1 - \alpha H^{(0)}_0 g^{(1)}_1 \\
g_\text{Reptile} &= g^{(0)}_0 + g^{(1)}_1
\end{aligned} $$
이제 Taylor expansion을 사용해서 \(g_1^{(1)}\)을 풀어볼 수 있다. \(a\)에서 미분가능한 function \(f(x)\)의 Taylor expansion을 다시 살펴보면 다음과 같다.
$$ f(x) = f(a) + \frac{f'(a)}{1!}(x-a) + \frac{f''(a)}{2!}(x-a)^2 + \dots = \sum_{i=0}^\infty \frac{f^{(i)}(a)}{i!}(x-a)^i $$
여기서 \(\nabla_{\theta}\mathcal{L}^{(1)}(\dot)\)을 하나의 함수로 간주하고, \(\theta_0\)를 어떤 특정값이라고 해보면 해당 특정값 \(\theta_0\)에 대한 \(g_1^{(1)}\)의 Taylor expansion을 다음과 같이 전개할 수 있다.
$$ \begin{aligned}
g_1^{(1)} &= \nabla_{\theta}\mathcal{L}^{(1)}(\theta_1) \\
&= \nabla_{\theta}\mathcal{L}^{(1)}(\theta_0) + \nabla^2_\theta\mathcal{L}^{(1)}(\theta_0)(\theta_1 - \theta_0) + \frac{1}{2}\nabla^3_\theta\mathcal{L}^{(1)}(\theta_0)(\theta_1 - \theta_0)^2 + \dots & \\
&= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + \frac{\alpha^2}{2}\nabla^3_\theta\mathcal{L}^{(1)}(\theta_0) (g_0^{(0)})^2 + \dots & \scriptstyle{\text{; because }\theta_1-\theta_0=-\alpha g_0^{(0)}} \\
&= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2)
\end{aligned} $$
(참고로 \(O(\alpha^2)\)은 taylor expansion의 뒷부분을 Complexity 관점에서 축약한 것이다.)
위에서 구한 확장된 형태의 \(g_1^{(1)}\)을 앞에서 언급한 one-step inner gradient update시의 MAML gradient에 대입해보면 아래와 같다.
$$ \begin{aligned}
g_\text{FOMAML} &= g^{(1)}_1 = g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2)\\
g_\text{MAML} &= g^{(1)}_1 - \alpha H^{(0)}_0 g^{(1)}_1 \\
&= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2) - \alpha H^{(0)}_0 (g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2))\\
&= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} - \alpha H^{(0)}_0 g_0^{(1)} + \alpha^2 \alpha H^{(0)}_0 H^{(1)}_0 g_0^{(0)} + O(\alpha^2)\\
&= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} - \alpha H^{(0)}_0 g_0^{(1)} + O(\alpha^2)
\end{aligned} $$
그리고 Reptile Gradient는 다음과 같이 된다.
$$ \begin{aligned}
g_\text{Reptile}
&= g^{(0)}_0 + g^{(1)}_1 \\
&= g^{(0)}_0 + g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2)
\end{aligned} $$
정리해보면 각 gradient는 이렇게 된다.
$$ \begin{aligned}
g_\text{FOMAML} &= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2)\\
g_\text{MAML} &= g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} - \alpha H^{(0)}_0 g_0^{(1)} + O(\alpha^2)\\
g_\text{Reptile} &= g^{(0)}_0 + g_0^{(1)} - \alpha H^{(1)}_0 g_0^{(0)} + O(\alpha^2)
\end{aligned} $$
Training시 multiple data batch에 대해서 보통 평균을 취하게 된다. 위에서 다룬 예제에서는 id=0인 mini-batch data와 id=1인 mini-batch 는 Random하게 뽑아낸 data이기 때문에 서로 교환이 가능하다. 이에 대한 expectation \(\mathbb{E}_{\tau,0,1} \)는 현재의 task \(\tau\)에 대한 두개의 data batch의 평균을 취한 것이다.
이제 다음과 같이 내용을 전개할 것이다.
- \(A = \mathbb{E}_{\tau, 0, 1}[g_0^{(0)}] = \mathbb{E}{\tau, 0, 1}[g_0^{(1)}]\)
- A는 task loss에 대한 average gradient이다. 이렇게 A가 가리킨 방향을 따라감으로써 task performance를 향상시킬 수 있도록 model parameter를 개선시키기를 원하는 것이다. - \(B = \mathbb{E}_{\tau, 0, 1}[H^{(1)}_0, g^{(0)}_0] = \frac{1}{2}\mathbb{E}_{\tau, 0, 1}[H^{(1)}_0, g^{(0)}_1 + H^{(0)}_0 g^{(1)}_0] = \frac{1}{2} \mathbb{E}_{\tau, 0, 1}[ \nabla_{\theta} (g^{(0)}_0 g^{(1)}_0)] \)
- B는 같은 task에 대해서 두개의 다른 mini-batch에 대한 gradient의 inner product를 증가시킬 수 있는 gradient(방향)를 나타낸다. 이를 통해서 B가 가리킨 방향을 따라감으로써 또다른 data에 대한 generalization이 잘 이뤄질 수 있도록 model parameter를 개선시키기를 원하는 것이다.
결론을 내자면, MAML과 Reptile 모두 같은 goal을 가지고 optimize하는 것을 지향하며, gradient update가 아래의 세개의 항으로 근사됬을 때, (A에 의해서) 좋은 task performance를 낼수 있고, (B에 의해서) 좋은 generalization을 보여줄 수 있다.
$$ \begin{aligned}
\mathbb{E}_{\tau,1,2}[g_\text{FOMAML}] &= A - \alpha B + O(\alpha^2)\\
\mathbb{E}_{\tau,1,2}[g_\text{MAML}] &= A - 2\alpha B + O(\alpha^2)\\
\mathbb{E}_{\tau,1,2}[g_\text{Reptile}] &= 2A - \alpha B + O(\alpha^2)
\end{aligned} $$
사실 원저자 관점에서는 위의 식 중 생략된 항인 \(O(\alpha^2)\)이 parameter learning시 큰 영향을 줄 수 있다고 생각하는 것 같다. 하지만 위에서 설명한 대로 FOMAML이 완전한 MAML과 비교했을때 거의 비슷한 성능을 낼 수 있는 것처럼, gradient descent를 update할 때는 higher-level derivative는 그렇게 중요하지 않는 것처럼 보인다.
해당 포스트 글을 논문에 인용하려면 다음 bibtex를 참고하고, 포스트와 관련해서 오류나 문제가 발생하면 댓글이나 원저자 (lilian dot wengweng at gmail dot com), 혹은 역자(kcsgoodboy at gmail dot dom) 에게 문의해주시면 감사하겠습니다.
@article{weng2018metalearning,
title = "Meta-Learning: Learning to Learn Fast",
author = "Weng, Lilian",
journal = "lilianweng.github.io/lil-log",
year = "2018",
url = "http://lilianweng.github.io/lil-log/2018/11/29/meta-learning.html"
}
'Study > AI' 카테고리의 다른 글
| [RL] Domain Randomization for Sim2Real Transfer (5) | 2019.08.31 |
|---|---|
| [RL] Flexibility of the Policy Iteration Framework (0) | 2019.08.29 |
| [Me][ML] How AI and machine learning are improving customer experience (0) | 2019.08.16 |
| [RL] Temporal Difference Learning : TD(0) (0) | 2019.07.08 |
| [ML] Averaged Perceptron / Pegasos (0) | 2019.07.01 |
| [RL] Policy Gradient Algorithms (24) | 2019.06.17 |
| [ML][DS] ColumnTransformer를 활용한 Column Align (0) | 2019.05.30 |
- Total
- Today
- Yesterday
- Windows Phone 7
- dynamic programming
- 파이썬
- SketchFlow
- Kinect SDK
- Variance
- PowerPoint
- End-To-End
- TensorFlow Lite
- Kinect for windows
- bias
- Gan
- DepthStream
- ColorStream
- processing
- Expression Blend 4
- Policy Gradient
- Kinect
- 인공지능
- arduino
- Pipeline
- RL
- Off-policy
- 강화학습
- 한빛미디어
- Distribution
- Offline RL
- reward
- windows 8
- 딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |