
(OpenAI Spinning Up 글을 개인적으로 정리했습니다. 원본) Extra Material — Spinning Up documentation Docs » Extra Material Edit on GitHub © Copyright 2018, OpenAI. Revision 97c8c342. Built with Sphinx using a theme provided by Read the Docs. spinningup.openai.com 이번 글에서는 finite-horizon undiscounted return 상태에서 다음 식을 증명하고자 한다. $$ \nabla_{\theta} J(\pi_{\theta}) = E_{\tau \sim \pi_{\theta}} \Big[ \sum_{t=0}^{T} \b..
(이 글은 OpenAI Spinning Up의 글을 개인적으로 정리한 내용입니다. 원본) Extra Material — Spinning Up documentation Docs » Extra Material Edit on GitHub © Copyright 2018, OpenAI. Revision 97c8c342. Built with Sphinx using a theme provided by Read the Docs. spinningup.openai.com 이번 글에서는 action이 이전에 얻은 reward에 reinforce되서는 안된다는 것을 증명하고 한다. 먼저 simplest policy gradient에서의 식 중 \(R(\tau)\)를 전개해보면 다음과 같다. $$ \begin{align} \n..
( 본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 3: Intro to Policy Optimization — Spinning Up documentation In this section, we’ll discuss the mathematical foundations of policy optimization algorithms, and connect the material to sample code. We will cover three key results in the theory of policy gradients: In the end, we’ll tie those results together and desc spinningup.openai.com 이번 글에서는..
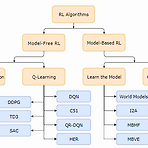 [RL] (Spinning up) Kinds of RL Algorithms
[RL] (Spinning up) Kinds of RL Algorithms
(본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 2: Kinds of RL Algorithms — Spinning Up documentation We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make somethin spinningup.openai.com RL Algorithm의 ..
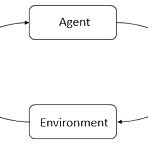 [RL] (Spinning Up) Key concepts in RL
[RL] (Spinning Up) Key concepts in RL
(본 글은 OpenAI Spinning Up 글을 개인적으로 정리한 글입니다. 원본) Part 1: Key Concepts in RL — Spinning Up documentation A state is a complete description of the state of the world. There is no information about the world which is hidden from the state. An observation is a partial description of a state, which may omit information. In deep RL, we almost always represent stat spinningup.openai.com RL을 다루면 가장 많이 나오..
 [ETC] Google Coral Dev Board
[ETC] Google Coral Dev Board
회사 지원을 받아서 미국으로 나와있다. 미국에 나오자마자 살려고 고민했던게 바로 Google에서 출시한 Coral Dev Board였는데, 이렇게 수령했다. 대충 가격은 150정도에 Tax 붙고 배송비까지 적용하니까 180불정도 했던거 같다. 이게 눈에 띄는 이유는 Google에서 만든 NPU인 TPU가 on-board 형식으로 embedded된 것이다. 지금까지 나온 형태는 Chip내에 내장되어 있던가, 아니면 Movidius에서 Neural Computing Stick 처럼 USB를 통해 처리를 지원받는 형식이었는데, 이건 위처럼 보드 타입도 있고, usb-c type으로 연결해 쓰는 타입도 있다. 나름 구글에서는 edge computing, fast ML을 지향하면 출시한 것이긴 한데, 예제좀 돌려..
 [ETC] Atari-wrapper 설치하다 error가 발생하는 경우
[ETC] Atari-wrapper 설치하다 error가 발생하는 경우
Windows 10에서 OpenAI Gym 중 Atari simulator를 설치하다가 다음과 같은 Error가 발생하는 케이스가 있다. Error 내용에도 보다시피 Microsoft Visual C++ 14.0이 설치되어 있지 않아 발생하는 문제이고, 이를 해결하기 위해서는 해당 컴파일러가 있는 위치를 환경변수의 Path로 지정해줘야 한다. 우선 다음 vs_build_tool을 설치한다.(vs 2019 기준) 아마 설치가 되어 있다면 추가 패키지 설치란이 있을텐데, 여기서 Windows 10 SDK (10.0.17134.0)을 설치해준다. 이를 설치하게 되면, C:\C:\Program Files (x86)\Windows Kits\10\bin\10.0.17134.0\x64 에 컴파일러들이 설치가 된다. ..
 [RL] Windows 10에서 OpenAI Gym & Baselines 설치하기
[RL] Windows 10에서 OpenAI Gym & Baselines 설치하기
아마 강화학습용 시뮬레이터와 알고리즘을 검증하는데 가장 많이 사용하는 것이 OpenAI Gym과 OpenAI Baselines 일 것이다. Gym은 원래의 뜻인 체육관이란 뜻에도 담겨있는 것처럼, 강화학습 알고리즘을 테스트해볼 수 있는 다양한 simulation environment가 포함되어 있다. 물론 강화학습을 하는 사람이라면 한번쯤 들어봤을 듯한 Atari나 robot Simulator인 MuJoCo도 들어있다. Baselines는 이와 반대로 Gym 환경 base에서 테스트해볼 수 있는 다양한 알고리즘들이 포함되어 있는 패키지이다. 제일 기초적인 DQN부터 시작해서 조금 발전된 형태인 DDPG, TRPO, PPO같은 알고리즘들도 구현되어 있다. 그래서 본인이 만약 알고리즘에 치중해서 개발하고 있..
이번 글은 cost와 state transition을 알지 못하는 상태에서의 optimal control을 위한 강화학습의 관점을 설명하는 것에서 시작해보고자 한다. 모두들 알다시피 Dynamic Programming을 통해서 optimal solution을 구할 수 있다. 하지만, 현재의 모델이나 cost를 모를 때나, 전체 dynamic program를 수정하기 어려운 상황이라면, RL 문제를 풀기 위해서는 approximation(근사) 기법에 의존해야 한다. 물론, dynamic program을 근사하는 것은 매우 어려운 부분이다. Bertsekas는 최근 "dynamic programming and optimal control"의 개정판을 출간했으며, 해당 책 2권의 6장을 살펴보면 dynami..
 [RL] Catching Signals That Sound in the Dark
[RL] Catching Signals That Sound in the Dark
강화학습의 본질은 시간대별로 dynamic하게 변하는 시스템의 미래를 형상화하는데 이전의 데이터를 활용하는 것이다. 강화학습의 가장 흔한 예가 episodic model을 따르는 것인데, 이는 특정 단위의 action이 정의되고, 시스템 상에서 테스트되었고, 특정 단위의 reward와 state가 관찰되고, 이런 이전의 action과 reward, state 정보들이 결합되어 행동을 결정하는 policy를 향상시키는데 사용되는 것이다. 시스템과 상호반응하는 것 자체가 매우 고급지고 복잡한 모델이기도 하고, 일반적인 확률적인 최적화 방식에 비하면 조금 더 복잡하다고 고려되기도 한다. 미래의 성능을 향상시키기 위해서 수집된 데이터 모두를 잘 활용하는 방법이 있을까? policy gradient나 random..
 [AWS] Sagemaker GPU instance 추가
[AWS] Sagemaker GPU instance 추가
udacity 마지막 과제가 AWS Sagemaker를 이용해서 XGBoost를 구현하고 training시키는 것인데, 많은 데이터를 학습하다보니, GPU instance가 필요한 경우가 생겼다. 분명 난 회사에서도 AWS Hands-on-Lab을 수행한다고 사전에 GPU instance 제한을 풀어놨었다.그런데 막상 Sagemaker내에서 GPU instance를 쓰려니까 다음과 같은 오류가 발생했다. from sagemaker.pytorch import PyTorch estimator = PyTorch(entry_point="train.py", source_dir="train", role=role, framework_version='0.4.0', train_instance_count=1, train_..
일하다 보니까, 딥러닝이나 강화학습으로 학습된 모델을 현장같은 데에서도 사용해야 할 경우가 생긴다. 물론 현장에다 고성능 서버를 갖다놓을 수는 없으니, 그래도 경량화된 Single Board Computer(SBC)가 필요할텐데, 요새는 이런 SBC의 성능도 많이 좋아져서 예전보다는 선택의 여지가 넓어진거 같다. 아무튼 몇가지 survey한 결과를 공유해보고자 한다. (참고 : 시중에서는 Tensor 연산을 가속화하는 장치를 Neural Processing Unit(NPU), Tensor Processing Unit(TPU) 라고 표현되는 것 같은데, 여기서는 TPU라고 통칭하고자 한다. 이에 대한 또다른 표현은 여기를 참고하면 좋을거 같다.)형태 - TPU-alone : 사실 이건 SBC라고 보긴 어려..
 [RL] The Best Things in Life Are Model Free
[RL] The Best Things in Life Are Model Free
몇몇 포스트를 통해서, 강화학습에서의 model-free method의 어두운 면을 소개했었지만, 그렇다고 model-free 기조를 완전히 저버린 것은 아니다. 사실 핵심 제어 시스템에서 가장 많이 쓰이는 방법이 바로 model-free method이다. 가장 광범위하게 쓰이는 형태가 PID 제어인데, 이 제어는 단지 3개의 parameter만 가지고 있다. 그래서 이번 포스트를 통해 PID 제어에 대해서 소개하고, machine learning의 수많은 주제들과 얼마나 가깝게 연관되어 있는지 설명하면서, 현대 강화학습 연구에서의 model-free method에 PID를 어떻게 끌어올 수 있는지 설명하고자 한다.PID 기초PID는 "Proportional Integral Derivative" 제어를 ..
 [RL] Clues for Which I Search and Choose
[RL] Clues for Which I Search and Choose
model-free 설명을 마치기 전에 다시 Linearization Principle에 대해서 살펴보자. 우리는 간단한 선형성 문제에서 random search도 잘 동작하는 것을 확인했고, 어쩔 때는 Policy Gradient같은 강화학습보다 더 잘 동작하는 것도 보았다. 그러면 뭔가 어려운 문제를 풀 때 Random Search로 해결해야 할까? 미리 말하자면, 아니다. 그래도 계속 읽어봐라! 이제 강화학습 커뮤니티에서 흥미있는 문제에 random search를 적용해보자. Deep RL 커뮤니티에서는 OpenAI에서 관리되고, MuJoCo 시뮬레이터를 기반으로 하는, 일종의 benchmark에 많은 시간을 할애하고 있다. 여기서 optimal control problem이란 다리가 달린 로봇을 ..
 [RL] Updates on Policy Gradients
[RL] Updates on Policy Gradients
지난번 nominal control에 대한 포스트 이후에, Pavel Christof로부터 메일을 받았었는데, 내용은 만약 Stochastic Gradient Descent를 Adam 으로 바꾼다면 Policy Gradient가 더 잘 동작한다는 것이었다. 실제로 내가 구현해보니까, 그가 말한 말이 맞았다. 한번 지난 Jupyter notebook과 함께 포스트 내용을 살펴보자. 우선 다른 딥러닝 패키지간의 dependency를 제거하기 위해서 adam을 순수 python으로 구현했다.( python으로 4줄로 구현했다.) 두번째로 지난번 코드에서 구현한 random search 부분에서 부적절하게 탐색방향을 잡는 것에 대한 버그를 수정했다. 이제 다시 median performance를 살펴보면 아래와..
- Total
- Today
- Yesterday
- reward
- Windows Phone 7
- dynamic programming
- 한빛미디어
- Expression Blend 4
- Kinect SDK
- Variance
- Distribution
- windows 8
- Kinect
- 강화학습
- ColorStream
- PowerPoint
- Gan
- bias
- Python
- DepthStream
- arduino
- End-To-End
- Policy Gradient
- processing
- Off-policy
- Kinect for windows
- 파이썬
- TensorFlow Lite
- Pipeline
- 딥러닝
- RL
- Offline RL
- SketchFlow
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |