
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Deterministic Policy Gradient Algorithm (D.Silver et al, 2014) Abstract 이 논문에서는 Continuous Action을 수행할 수 있는 Deterministic Policy Gradient (DPG)에 대해서 소개하고 있다. DPG는 (보통 Q value function이라고 알고 있는) action-value function(\(Q^{\pi}(s, a)\) )의 expected gradient 형태로 되어 있어, 일반적으로 알고 있는 (Stochastic) Policy Gradient 보다 data efficiency 측면에서 이점이 있다. 대신 Deterministic하기 때문에..
 [Book] 전문가를 위한 C
[Book] 전문가를 위한 C
(해당 포스트에서 소개하고 있는 "전문가를 위한 C" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 전문가를 위한 C 실제 애플리케이션 개발과 유지 보수에 필요한 C의 기초 개념과 활용법, 고급 기능까지 살펴보는 C 중고급서. C와 유닉스의 역사부터 객체지향, 커널, 스레드, 프로세스, 다른 언어와 통합하는 법 hanbit.co.kr 항상 프로그래밍 언어와 관련된 책을 리뷰할 때면 TIOBE Index를 인용해오곤 하는데, 현재 시점에서 C는 Python에 이어 2위에 위치해있다. C는 1972년 Dennis Ritchie가 만들었고, 올해는 언어가 태어난지 만 50년이 되는 시점이다. 물론 최근에는 뭔가 다방면으로 활용할 수 있는 언어들이 인기를 얻고 많이 사용되고 있지만, 그 중에서도 시스템 어..
 [Book] Pandas in Action
[Book] Pandas in Action
(해당 포스트에서 소개하고 있는 "판다스 인 액션" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 판다스 인 액션 대표적인 파이썬 데이터 분석 라이브러리, 판다스의 기본 자료구조 개념부터 데이터 분석법까지 차근차근 배울 수 있는 도서입니다. 초급자부터 상급자까지 모두 만족시킬 수 있는 구성과 내용 hanbit.co.kr 내가 회사에서 하고 있는 일은 생활가전에 인공지능 기술을 넣는 방법에 대해 고민하는 것이다. 이에 대한 결과가 사용자 편의를 가지고 오던, 제어 효율성을 높여서 에너지를 절감할 수 있게 한다던지 이런 방향으로 연구하는 일을 주로 하고 있다. 그런데 가끔 내 직무가 무엇인가에 대해서 진지하게 고민할 때가 있다. 공식적인 직무는 Software Engineer이긴한데, 하는 일을 생각해..
 [Daily] 논문 회고
[Daily] 논문 회고
올해 몇가지 벌여논 일이 있었는데, 한 해의 끝으로 가면서 하나씩 마무리가 되어간다. 진짜 연초에는 과연 할 수 있을까 하는 의구심을 가지고 버킷리스트에 넣어놓은 것들이 하나씩 해결되어가는 모습을 보니 참 감회가 새롭다. 요 근래 몇달동안 논문을 써보는데 집중했었다. 석사과정때도 경험했던 일이긴 했지만, 마지막 제출까지 피를 말리는 경험을 하곤했다. 막 살펴보면 오타도 있고, page limit에 걸려서 있던 그림도 반으로 잘라서 single column에 넣고... 제일 힘들었던 것은 latex내에서 그림을 넣었는데, 원하는대로 이쁘게 그림이 달리지 않는 것은 두고두고 짜증이 났던 부분이다. 그렇게 힘든 과정을 거치고 막상 내고 나니까 뭐랄까... 원래 이런 고생을 해야 글이 나오는건가 싶다. 아 참고..

 [Thing] Lattepanda 3 Delta 864
[Thing] Lattepanda 3 Delta 864
작년 말에 Kickstarter에서 funding했던 Lattepanda delta 3가 드디어 왔다. (원래 배송일자는 3월이었지만, 코로나로 인해서 중국이 봉쇄되면서, 배송이 지연되었다.) 참고로 나는 Lattepanda 초창기 모델부터 계속 funding을 했었는데, 뭔가 저렴한 가격에 계속 성능 개선을 하려는 시도가 보이는 것 같아서 계속 투자를 했던 것 같다. 사실 동 가격에 비슷한 성능을 내는 노트북은 300~400불 정도 하는데 비해 이 정도 single board computer가 200불 내외로 구입할 수 있는 것은 좋은 기회가 아닐까 싶다. 참고로 국내에는 icbanq를 통해서 8월 중순부터 정식으로 유통될 예정인듯하다. 간단하게 unboxing 사진 공유한다. 사실 board의 외형 ..
 [Book] 파이썬을 활용한 베이지안 통계
[Book] 파이썬을 활용한 베이지안 통계
(해당 포스트에서 소개하고 있는 "파이썬을 활용한 베이지안 통계" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 파이썬을 활용한 베이지안 통계(2판) 수학 기호 대신 파이썬 코드를, 연속형 확률 분포 대신 이산형 확률 분포를 사용해서 통계 문제를 푸는 방법을 알려준다. 수학 방법에서 빠져나와 코드로 기본 베이지안 개념을 명확하게 보면 hanbit.co.kr 오라일리에서 출판하는 책 중에 Think 시리즈라는게 있다. Olin college에서 교수를 하고 있는 Allen B. Downey가 쓴 책들의 모음인데, 이 책들의 시리즈를 보다보면 진짜 대단한게, 정말 다양한 분야를 대상으로 책을 쓴다. 파이썬이나 자바, 자료 구조와 관련된 책들도 있고, 통계와 시뮬레이션, DSP와 관련된 책도 쓴다. 물론..
 [Daily] 2022년 우수학술도서 선정
[Daily] 2022년 우수학술도서 선정
아마 블로그를 자주 들어온 사람이라면 알고있겠지만, 개인적으로 강화학습을 공부하면서 책 한권을 번역했었다. [Me] 그로킹 심층 강화학습 몇 달전에 번역하고 있는 책에 대한 짧은 글을 썼었는데, 며칠 전에 하판되었다는 연락을 받고, 이번주 일요일에 출간한다는 이야기를 전달받았다. 실제로 출판사 웹사이트에도 등록되어 있는 talkingaboutme.tistory.com 작년 10월에 출간된 책이고, 나름 1년동안 준비하면서 시행착오도 겪었지만, 번역을 하면서 나름 결과물을 얻었던 것 같다. 물론 그 결과물이 책의 매출로 직결되었는지는 잘 모르겠지만, 그래도 개인적으로는 조금더 심층강화학습이라는 것을 접하면서 더 깊은 영역을 파고들 수 있게 해주지 않았나 싶다. 덕분에 회사에서도 관련된 주제로 계속 연구할 ..
 [Book] Learning algorithm
[Book] Learning algorithm
(해당 포스트에서 소개하고 있는 "Learning Algorithm: 똑똑한 코드 작성을 위한 실전 알고리즘" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 똑똑한 코드 작성을 위한 실전 알고리즘 파이썬 예제를 실행해보면서 컴퓨터 과학의 핵심 알고리즘과 문제 해결법을 익히는 책 hanbit.co.kr 아마 유명한 IT 업계로 취업하려는 사람들은 알겠지만 시중에는 정말 다양한 알고리즘 책들이 존재한다. 다양한 책들마다 나름대로의 내용을 풀어가는 방향이 다 다르다. 예를 들어서 어떤 책은 문제은행 식으로 많은 케이스들을 제공하고 이에 대한 해설을 제공하는 형태가 있다. 또 다른 책은 정렬이나 탐색, 그래프와 같이 문제를 푸는데 있어서 필요한 기본 지식들에 대해서 하나씩 다루는 형태로 되어있는 경우도 있..

 [Book] 구글 엔지니어는 이렇게 일한다
[Book] 구글 엔지니어는 이렇게 일한다
(해당 포스트에서 소개하고 있는 "구글 엔지니어는 이렇게 일한다" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 구글 엔지니어는 이렇게 일한다 지난 20년간 구글 소프트웨어 엔지니어가 구글에서 직접 경험한 내용을 바탕으로 코드의 가치를 가장 잘 유지하는 방법, 소프트웨어를 효율적으로 관리하는 프로세스 도입 방법, 구글의 문화를 hanbit.co.kr 아마 IT업계에서 일하는 사람들이라면 각자 속한 팀내에서 활용되는 규칙이나 철학같은 것이 있을 것이다. 나름의 규칙을 가지고 에자일 프로세스를 따르기도 하고, 코드 리뷰를 통해 오류를 찾는 과정을 거치며, 정적분석을 통해 소프트웨어의 품질을 유지하려고 노력할 것이다. 내가 속한 팀도 그렇게 엄격하지는 않더라도 나름의 규칙을 통해서 이런 개발 프로세스를 ..
 [RL][Review] Hyperparameter Selection for Offline Reinforcement Learning
[RL][Review] Hyperparameter Selection for Offline Reinforcement Learning
(본문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Hyperparameter Selection for Offline Reinforcement Learning - Le Paine et al, NeurIPS 2020 Offline RL workshop (논문, 영상) 요약 Offline RL은 실제 환경에 RL 기법들을 적용하기 좋은 방법론이긴 하지만 환경상에서 어떤 policy가 좋은 policy인지 각 hyperparameter에 따라서 평가하는 과정으로 인해 offline 가정이 깨지게 된다. 이렇게 online 상에서 수행하는 과정으로 인해 offline RL을 통해 추구하는 목표가 상대적으로 약화된다. 그래서 이 논문에서는 offline hyperparameter selection,..
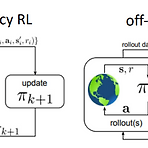 [RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
[RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
(본문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Offline Reinforcement Learning from Algorithms to Practical Challenges - Kumar et al, NeurIPS 2020 Tutorial (사이트, 실습코드) 원래 거진 3시간짜리 tutorial이기 때문에 정리하는데 시간이 걸릴듯 하다. 그래도 전반적인 Offline RL의 문제와 이론에 대해서 잘 설명되어 있어서 차근차근 설명해보고자 한다. 기본적인 RL 내용도 포함되어 있어, Offline RL 부분만 뽑아서 정리한다. Can we develop data-driven RL methods? 보통 강화학습이라고 하면 다음과 같은 환경을 가정하고 진행한다. 일반적으로는 어떤 환경이 주..
 [Book] 파이썬을 활용한 금융 분석
[Book] 파이썬을 활용한 금융 분석
(해당 포스트에서 소개하고 있는 "파이썬을 활용한 금융 분석" 책은 한빛 미디어로부터 제공받았음을 알려드립니다.) 파이썬을 활용한 금융 분석(2판) 금융 분야 종사자, 관련 개발자들이 파이썬을 시작하고 이를 활용하여 중용한 금융 분석 업무를 할 수 있도록 도와주는 최적의 실무 가이드 북입니다. hanbit.co.kr 아마 주식을 하고 있다면 솔깃한 내용 중 하나는 과연 인공지능으로 주식을 자동으로 거래하게 해서 돈을 벌 수 있을까 일 것이다. 그래서 시중에도 증권API를 파이썬으로 다루는 방법에 대한 내용을 소개한 책들이 다수 소개되어 있다. 물론 수많은 접근 방식이 있겠지만, 모든 접근 방식보다도 선행되어야 할 것은 데이터 분석이 아닐까 생각된다. (과거를 포함하여) 현재 쌓여 있는 특정 데이터속에서 ..
 [RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl)
[RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl)
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Offline RL without Off-Policy Evaluation - Brandfonbrener et al, NeurIPS 2021 (논문, 코드) 요약 이전에 수행된 대부분의 Offline RL에서는 off-policy evaluation과 관련된 반복적인 Actor-critic 기법을 활용했다. 이 논문에서는 behavior policy의 on-policy Q estimate를 사용해서 제한된/정규화된 policy improvement를 단순히 한번만 수행해도 잘 동작하는 것을 확인했다.이 one-step baseline이 이전에 발표되었던 논문에 비하면 눈에 띌만큼 간단하면서도 hyperparameter에 대해서 robust한..
- Total
- Today
- Yesterday
- End-To-End
- TensorFlow Lite
- Distribution
- processing
- Variance
- Pipeline
- ai
- SketchFlow
- Offline RL
- dynamic programming
- reward
- Off-policy
- Gan
- PowerPoint
- RL
- 딥러닝
- Policy Gradient
- bias
- Windows Phone 7
- 강화학습
- arduino
- Expression Blend 4
- DepthStream
- windows 8
- ColorStream
- Kinect SDK
- 파이썬
- Kinect
- Kinect for windows
- 한빛미디어
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |