
 [Daily] 2022년 우수학술도서 선정
[Daily] 2022년 우수학술도서 선정
아마 블로그를 자주 들어온 사람이라면 알고있겠지만, 개인적으로 강화학습을 공부하면서 책 한권을 번역했었다. [Me] 그로킹 심층 강화학습 몇 달전에 번역하고 있는 책에 대한 짧은 글을 썼었는데, 며칠 전에 하판되었다는 연락을 받고, 이번주 일요일에 출간한다는 이야기를 전달받았다. 실제로 출판사 웹사이트에도 등록되어 있는 talkingaboutme.tistory.com 작년 10월에 출간된 책이고, 나름 1년동안 준비하면서 시행착오도 겪었지만, 번역을 하면서 나름 결과물을 얻었던 것 같다. 물론 그 결과물이 책의 매출로 직결되었는지는 잘 모르겠지만, 그래도 개인적으로는 조금더 심층강화학습이라는 것을 접하면서 더 깊은 영역을 파고들 수 있게 해주지 않았나 싶다. 덕분에 회사에서도 관련된 주제로 계속 연구할 ..
 [RL][Review] Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (BEAR)
[RL][Review] Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (BEAR)
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction - Kumar et al, NeurIPS 2019 (논문, 코드) 요약 Off-policy RL은 샘플링 관점에서 효율적인 학습을 위해서 다른 policy (behavior policy)로부터 수집한 데이터로부터 경험을 배우는데 초점을 맞추지만, Q-learning이나 Actor-Critic 기반의 off-policy Approximate dynamic programming 기법은 학습시 사용된 데이터와 실제 데이터간의 분포가 다른 문제로 인해서 on-policy data를 추가로 활용하지 않고서는 성능을 개선하기가 어..
 [RL][Review] Off-Policy Deep Reinforcement Learning without Exploration (BCQ)
[RL][Review] Off-Policy Deep Reinforcement Learning without Exploration (BCQ)
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Off-Policy Deep Reinforcement Learning without Exploration - Fujimoto et al, ICML 2019 (논문, 코드) 요약 이 논문에서는 이미 모아져있는 고정된 dataset 상에서 강화학습 에이전트를 학습할 수 있는 알고리즘을 소개한다. 보통 강화학습은 exploration을 통해서 insight를 얻어내고, 이에 대한 경험으로 성능을 추출하는 형태로 되어 있지만, 고정된 dataset으로부터 학습하게 되면 exploration을 할 수 없기 때문에 성능을 얻어낼 요소가 부족하다. 이런 종류의 알고리즘을 Offline RL 혹은 Batch RL이라고 표현하고, 사실 이 알고리즘은 be..
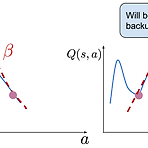 [RL] Offline (batch) Reinforcement Learning의 의미와 적용
[RL] Offline (batch) Reinforcement Learning의 의미와 적용
(해당 글은 U.C. Berkeley 박사과정에 재학중인 Daniel Seita가 작성한 포스트 내용을 원저자 동의하에 번역한 내용입니다) Offline (Batch) Reinforcement Learning: A Review of Literature and Applications Reinforcement learning is a promising technique for learning how to perform tasks through trial and error, with an appropriate balance of exploration and exploitation. Offline Reinforcement Learning, also known as Batch Reinforcement Learni..
 [RL] Windows에서 Dopamine 설치
[RL] Windows에서 Dopamine 설치
Dopamine은 Google Research에서 만든 강화학습 실험용 Framework이다. 사실 이 툴의 취지는 SW 개발적인 측면보다는 강화학습 알고리즘 개발에 치중할 수 있도록 환경과 에이전트 설정을 configuration화시킨 것이다. 그래서 소개란에도 "Fast prototyping of reinforcement learning algorithm"이라고 되어 있다. Framework에 대한 논문은 아래에 있다. Dopamine: A Research Framework for Deep Reinforcement Learning Deep reinforcement learning (deep RL) research has grown significantly in recent years. A number..
 [Me] 그로킹 심층 강화학습
[Me] 그로킹 심층 강화학습
몇 달전에 번역하고 있는 책에 대한 짧은 글을 썼었는데, 며칠 전에 하판되었다는 연락을 받고, 이번주 일요일에 출간한다는 이야기를 전달받았다. 실제로 출판사 웹사이트에도 등록되어 있는 것도 확인했다. 그로킹 심층 강화학습 개념을 수식부터 실습 코드까지 하나씩 떠먹여주는 심층 강화학습 가이드 hanbit.co.kr 어떻게 보면 인생의 버킷리스트 중 하나였는데, 주변에서도 많이 배려해주시고 도와주셔서 무사히 출판까지 잘 진행되었다. 깜빡하고 옮긴이의 글에는 못 남겼지만, 책이 나오는데까지 힘써주신 분들께 감사하다는 말씀을 드리고 싶다. 이전 포스트에서도 간단하게 소개했었지만, 다시한번 언급하자면 너무 이론적인 내용이나 실용적인 구현에 치중하지 않고, 기본적인 강화학습 개념부터 많이 언급되는 심층 강화학습 알..
 [Book] 패키지 없이 R로 구현하는 심층 강화학습
[Book] 패키지 없이 R로 구현하는 심층 강화학습
(포스트에서 다뤄지는 해당 도서는 저자 및 출판사의 지원을 받아 제공되었고, 이에 대한 서평을 쓴 것임을 알려드립니다.) 딱 딥러닝을 공부하는 사람들이 딥러닝을 구현하려면 파이썬을 반드시 배워야 하는 것으로 알고있지만, 사실 알고보면 다양한 언어로도 딥러닝의 기능을 구현할 수 있다. 우리가 알고 있는 대부분의 언어들도 배열 형태로 수학 연산을 구현할 수 있고, 이를 계산할 수 있는 기능만 갖추고 있다면, 다양하지는 않지만 흔히 심층 신경망이라고 하는 딥러닝 구조를 구현할 수 있다. 그 언어 중 하나가 R이다. R은 쉽게 말하면, 통계 이론을 구현하는데 특화되어 있는 프로그래밍 언어이다. 사실 파이썬이 범용적으로 사용할 수 있는 형태로 쉽게 구현할 수 있기 때문에 오늘날에 많이 쓰이고 있는 언어긴 하지만,..
 [Me] 일상
[Me] 일상
참 하고 싶은게 많은 요즘인데, 할 일이 많아서 바쁘게 살고 있다. 그래도 놀고 싶은 맘 한켠으로 접어두고, 몰입해서 하고 있는 일이 있다. 연초에 세웠던 버킷리스트 중 하나인데, 바로 "책 번역하기"이다. (사실 연초라기에는 작년 말부터 시작한 일이긴 하지만...) 현재 번역중인 책은 아마 알 사람은 알겠지만 Manning 출판사에서 Grokking 시리즈 중 하나인 Grokking Deep Reinforcement Learning 이라는 책이다. (시중에는 인공지능, 딥러닝, 머신러닝 등은 출간한 것으로 알고 있다) 아마 한글로는 "그로킹 심층 강화학습"으로 나올거 같긴 하지만 어찌 될지는 모르겠다. 대략 470p정도 되는 책인데, 지금까지 한 83%까지 초벌 번역은 마무리한 것 같다. 사실 번역이 ..
 [MOOC] Reinforcement Learning Specialization
[MOOC] Reinforcement Learning Specialization
아마 강화학습을 공부하는 사람이라면 Introduction to Reinforcement Learning이란 책은 거의 다 접해봤을 것이다. (무료로 제공되기도 하고, 참고로 번역본도 있어서 워낙 읽기가 쉬워졌다.) 사실 요새 유행하는 심층 강화학습을 이해하기 위해서는 기본적인 강화학습 이론에 대한 이해가 선행되어야 하고, 그 관점에서 보면 해당 책은 이론의 전개나 증명이 자세하게 다뤄진 거의 유일한 강화학습 책이 아닐까 싶다. 그런데 그렇다고 뭔가 강화학습 이론을 실제로 적용해보고자 하는 사람은 이 책에서 언급된 SARSA나 Q-learning 이론을 구현해볼려고 딱 보면 난감하게 느낄 수 있다. 그도 그럴 것이 이 책은 프로그래밍 책이 아닌 엄연한 강화학습 이론서이기 때문에 자세한 알고리즘은 pseu..
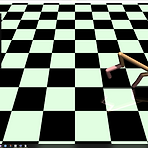 [RL] Windows 10에서 mujoco_py 구동
[RL] Windows 10에서 mujoco_py 구동
이전에 Linux에서 mujoco-py를 돌릴 때 발생할 수 있는 그래픽 라이브러리 관련 오류를 해결하는 방법에 대해서 공유한 적이 있다. 사실 그것도 그러려니와 Linux에서 할 수 있는게 많아, 집에서도 Windows 10이랑 Linux랑 듀얼부팅으로 설치해서 사용하고 있다. 그런데 아무래도 Windows 10에서 Linux로 넘어가려면 재부팅도 해야되고, 신경쓸게 많아져 Windows 10에서 할 수 있는 방법이 있지 않을까 찾아보다가, 마침 이와 관련된 글이 있어서 직접해보고 공유해보고자 한다. Install OpenAI Gym with Box2D and Mujoco in Windows 10 How to install OpenAI Gym[all] with Box2D v2.3.1 and Mujoco..
 [Book] 딥러닝과 바둑
[Book] 딥러닝과 바둑
(해당 포스트에서 소개하는 "딥러닝과 바둑" 책은 한빛미디어로부터 제공받았음을 알려드립니다.) 인공지능이 바둑 영역에서 본격적으로 활용되기 시작한 것은 4년전 알파고와 실제 인간과의 대결 이후였을 것이다. 그 이전에는 인공지능이 체스에 활용된 케이스가 있었지만, 제한된 영역에서 움직이는 체스와는 다르게 바둑에서는 활동 영역도 넓고, 무엇보다도 형세를 이해하고 몇수 뒤의 미래를 예측해야했기 때문에, 인공지능을 해결하기 어려운 분야라고 여겨졌었다. 그런 영역을 알파고는 머신러닝과 딥러닝, 더불어 강화학습까지 적용시켜 바둑 실력을 높이게 된 것이다. 혹시 이 영역에 관심있는 사람이라면 Deepmind에서 만든 알파고 관련 영화도 한번 보면 흥미가 있을것이다. 아무튼 알파고가 등장하고, 이를 어떻게 구현했는지에..
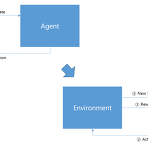 [RL] Reinforcement Learning
[RL] Reinforcement Learning
보통 아기들이 처음 태어나서 무엇을 할까? 잘 살펴보면 뒤집기, 앉기, 기어가기, 일어서기 까지 일련의 과정을 거친다. 옆에서 지켜보면 그 과정들이 조금 힘겨워 보일 때가 있다. 그런 동작 자체가 아기가 처음 세상 나오면서 처음 경험하는 행동이기 때문에 아기는 주변 사람들이 하는 동작을 보고 따라하려고 노력한다. 우선 아기가 그 동작을 보는 순간 우선 시도를 해볼 것이다. 당연히 처음 해보는 동작인만큼, 그 동작이 정답이 아닐 것이고, 뭔가 잘못된 자세가 나오게 된다. 이때 반복적으로 잘못된 동작을 고치기 위해서 노력할 것이고, 계속 연습을 하게 된다. 결국 동작을 하게 될 것이고, 그때부터는 다양한 주변환경에 대해서도 적응하는 과정도 포함이 될 것이다. 가령 일어서기 과정에서도 '뭔가를 짚고' 일어서는..
- Total
- Today
- Yesterday
- windows 8
- SketchFlow
- Gan
- 딥러닝
- Kinect for windows
- 파이썬
- dynamic programming
- Expression Blend 4
- Off-policy
- arduino
- reward
- processing
- Pipeline
- Distribution
- 강화학습
- 한빛미디어
- PowerPoint
- ai
- Windows Phone 7
- End-To-End
- TensorFlow Lite
- Policy Gradient
- Offline RL
- bias
- RL
- Variance
- Kinect
- ColorStream
- DepthStream
- Kinect SDK
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |