
티스토리 뷰
(해당 글은 U.C. Berkeley 박사과정에 재학중인 Daniel Seita가 작성한 포스트 내용을 원저자 동의하에 번역한 내용입니다)
Offline (Batch) Reinforcement Learning: A Review of Literature and Applications
Reinforcement learning is a promising technique for learning how to perform tasks through trial and error, with an appropriate balance of exploration and exploitation. Offline Reinforcement Learning, also known as Batch Reinforcement Learning, is a variant
danieltakeshi.github.io
강화학습은 적절한 exploration과 exploitation을 통해서 어떤 task에 대해 trial-and-error 방식으로 학습할 수 있는 대표적인 기법이다. Batch Reinforcement Learning (Batch RL)이라고도 알려져 있는 Offline Reinforcement Learning (Offline RL)은 이런 강화학습의 부류 중 하나로, exploration없이도 정해진 배치만큼의 데이터만 가지고도 에이전트를 학습할 수 있다. 다르게 표현하자면, 고정된 데이터셋만 가지고 극도로 exploitation을 수행하는 것이다. 이 방식은 실제 로봇의 정책을 학습할 때, 많은 데이터들이 필요하다는 부분에서 학계의 관심을 계속 가져왔다. 사실 실제 로봇을 가지고 exploration을 하게 되면, 로봇내에 장착되어 있는 하드웨어나 부가적인 요소들에 손상을 가져올 수 있다. 또한 Offline RL 자체가 어쩌면 exploitation으로부터 exploration을 도출하는 것이기 때문에, 여타 강화학습 알고리즘들간의 exploitatoin 성능을 비교할 수 있는 표준 척도가 될 수 있다.
Offline RL은 역시 exploration없이도 정해진 데이터셋을 통해서 학습하는 방식인 Imitation Learning (IL) 과도 많이 유사하다. 그런데 다음과 같이 몇가지 부분에서 큰 차이점이 있다.
- Offline RL은 Bellman equation이나 TD error의 형태를 최적화한 형태로 일반적인 off-policy Deep RL 알고리즘으로 구현되어 있다.
- 대부분의 IL 관련 문제에서는 optimal하거나 적어도 성능을 잘 내는 전문가 관련 데이터가 존재한다고 가정하지만, Offline RL은 suboptimal한 데이터만 다루는 환경을 가정한다.
- 대부분의 IL 관련 문제는 보상 함수가 없지만, Offline RL은 보상 함수를 고려하고, 더 나아가 수행된 결과를 바탕으로 보상함수를 변형시킬 수 있다.
- 일부 IL 문제에서는 전문가와 비전문가 데이터를 구분할 수 있는 label이 필요하지만, Offline RL에서는 이를 고려하지 않는다.
위의 비교 중 IL에 대해서 "일부"와 "대부분"이란 용어를 썼는데, IL 알고리즘에 대한 몇가지 예외 사항에 대해서는 다른 포스트에서 소개했다.
결국 Offline RL은 주어진 데이터에 대해서 최선의 정책을 찾는 것과 관련된 방법론이다. Imitation Learning에서는 전문가의 성능을 넘어선 결과를 보여주기 어렵지만, 적어도 Offline RL에서는 이에 대한 가능성을 제공한다. 조금 더 부연 설명을 하자면, 만약 표 방식으로 되어 있는 state visitation에서 무한대의 state를 표현할 수 있는 경우, Q-learning과 같은 알고리즘도 suboptimal 하면서 off-policy data만 가지고도 optimal policy로 수렴할 수 있다는 것은 이미 알려져 있다. 하지만 이어지는 몇몇 논문에서도 소개되겠지만, Deep Q-Network (DQN)과 같은 off-policy Deep RL 알고리즘도 결국 학습을 효율적으로 하기 위해서는 현재 수행중인 정책(behavior policy)로부터 충분한 "on-policy" 데이터가 필요하고, 이게 충족되지 않으면 성능이 급격하게 나빠진다.
Offline RL에 대해서 조금 더 자세한 설명을 찾고자 하면, Batch Reinforcement Learning (Lange et al, 2012)을 살펴보면 좋을 것 같다. 해당 장에서는 문제에 대한 전체적인 내용도 들어있고, "Offline RL에서의 Q-learning"이라고 할 수 있는 Fitted Q Iteration (Ernst et al, 2005)를 다른 알고리즘들과 비교해서 소개하고 있다. 내용이 유용하기도 하지만, 앞에서 소개한 Batch RL 책은 아마도 Neural Fitted Q-Iteration을 신경망으로 변형한 형태인 Deep Fitted Q-iteration에 대해서 소개하고 있는 Deep RL 참고서가 될 것 같다. 최근 딥러닝의 발전으로 인해서, 최근에 나오는 Offline RL 논문에서는 깊은 신경망을 통해서 정책을 학습시키고, 이를 조금 더 복잡한 환경에 적용하는 방식으로 소개하고 있다. 참고로 앞의 책의 저자 중 한명은 Martin Riedmiller는 DeepMind에서 Offline RL 연구를 계속하고 있다.
나머지 포스트에서는 Offline RL의 의미에 대해서 요약할텐데, Offline RL은 크게 두가지 분류로 나눠볼 수 있다.
- 데이터 상에서 나타나는 것처럼 에이전트가 행동이나 상태-행동 쌍을 선택할 수 있도록 알고리즘을 제한하는 방법
- 데이터셋에 초점을 맞춰서 강력한 off-policy 방법(그렇다고 offline 설정을 크게 벗어나지 않는 선에서)을 사용하면서 데이터의 다양성이나 크기를 최대화하거나, 이를 활용하여 새로운 벤치마크 환경을 만드는 방법
우선 첫번째 종류에 대해서 소개하고, 이어서 두번째 종류를 소개한 후 마지막으로 요약과 함께 관련 논문들에 대한 링크를 제공하고자 한다.
참고로 2020년 5월 UC Berkeley의 Sergey Levine 교수가 Offline RL에 대한 연구의 결과를 다룬 서베이 논문을 발표했었다. Levine 교수는 다른 종류의 Offline을 다뤘고, 논문에서도 다양한 주제에 대해서 소개하고 있는데, 이 포스트가 이해에 도움이 되었으면 좋겠다.
Exploration없이도 수행하는 Off-Policy Deep Reinforcement Learning
Off-Policy Deep Reinforcement Learning without Exploration (Fujimoto et al., 2019)은 내가 처음 Offline RL에 대해서 알게 된 논문이었다. 이 논문에 대해서는 다른 포스트에서 자세하게 다뤗지만, 여기에서는 최대한 요약을 해보고자 한다. 해당 논문에서는 대부분의 Deep RL에서의 "Off-policy 알고리즘"들은 좋은 결과를 보여주지 못하는데 이는 주어진 off-policy 데이터들이 추정 오차(해당 데이터 배치 이외의 데이터에서 state-action pair \( (s, a) \)가 부정확한 값을 가지는 경우)를 가지면서, 이 값을 직접적으로 활용하는 알고리즘들이 나쁜 영향을 받기 때문이다. 만약 online 설정이었다면 이렇게 부정확한 값도 실제로 ground-truth 값을 가지고 있기 때문에 수정이 될 가능성이 있지만, offline 설정에서는 이런 경향이 부족하다.
그래서 논문에서 소개한 알고리즘은 Batch Constrained Deep Q-learning (BCQ)이라는 것이다. 아이디어는 일반적인 Q-learning을 수행하되, Q value에 대한 최대값을 수행하는 단계에서 (보통 bellman equation에 의해서 \(\max_{a'}Q(s', a')\)으로 계산되는 부분) 모든 가능한 행동에 대한 최대값을 구하지 않고, 배치 데이터에서 "실제로" 나타난 \((s', a')\) 중 \(a'\)에 대해서만 고려하자는 것이다. 아니면, 조금 더 실제 상황을 고려해서 behavior policy \(\pi_b\) (아마 알겠지만 off policy 설정 중 static data를 생성하는 policy)에 의해서 잘 선택되지 않는 행동들은 제거할 수도 있다.
BCQ는 생성 모델 중 하나인 Variational AutoEncoder (VAE)를 학습시켜서 배치 데이터에서 잘 나오는 행동과 그 행동에 대해서 교란(perturb)시키는 perturbation 모델을 만들어낸다. 그리고 실제 test에서 롤아웃이 발생할 때, generator로부터는 \(N\)개의 행동을 샘플링하고, 각 행동을 교란시키면서, 이 중 가장 큰 Q-value에 대한 추정치를 가지는 행동을 선택하는 것이다.
성능에 대한 실험은 다음과 같이 설계했는데, 모든 경우에 대해서 Offline RL시 필요한 데이터 배치를 생성하는 Behavior DDPG 에이전트가 있는 것을 가정했다.
- Final Buffer: Behavior agent를 탐색을 많이 하게끔 설정해서 백만번만큼 학습시키고, 이 때 쌓은 데이터를 replay buffer에 넣는다. 그리고 새로운 DDPG 에이전트를 처음부터 학습시키되 이번에는 replay buffer에 있는 데이터에 대해서 탐색을 수행하지 않는 상태로 학습시킨다. 그러면 behavior agent는 백만번동안 학습이 된 상태이기 때문에 상태 측면에서는 수렴 경향이 클 것이다.
- Concurrent: behavior agent를 학습시키면서, 새 DDPG 에이전트도 behavior DDPG 에이전트가 쌓은 replay buffer 데이터를 가지고 "동시에" 학습시킨다. 이 때도 새 DDPG agent는 탐색을 수행하지 않는다. 결과적으로 이 두 에이전트는 학습이 수행되는 동안 동일한 replay buffer를 가지게 될 것이다.
- Imitation Learning: Behavior agent가 충분히 잘 동작할 때까지 학습시키고, 이 후에 replay buffer를 얻기 위해서 백만번만큼 수행한다. (이 때는 수렴이 되는 동안 noise가 조금 더 있을 가능성이 크다) 앞에서 소개한 "final buffer"와의 차이는 이 방법에서는 백만번동안 같은 정책에서 데이터를 뽑아내는 반면, final buffer 방법에서는 백만번의 수행시간동안 지속적으로 gradient update가 발생해서 결과적으로 환경에 대한 step이 발생할 때마다 gradient에 의해서 모델이 update되는 형태를 띄게 된다는 것이다 (결과적으로 이 수치도 hyperparameter일 수 있다.)
가장 큰 신기한 부분은 concurrent setting에서 새로 학습시키는 DDPG 에이전트는 잘 학습되지 않는다는 것이다. 조금 더 명확하게 하자면, 해당 에이전트는 동일한 replay buffer를 가지고 시작하고, offline agent는 online agent의 buffer에서 직접 minibatch를 샘플링한다. 이 학습단계에서 몇가지 차이점을 찾을 수 밖에 없는데, 내가 생각한 것은 (1) 초기 정책의 randomness, 그리고 (2) minibatch 샘플리에서의 noise 이다. 이 것외에 다른 것이 있나? 아무튼 이런 요소는 성능을 들쭉날쭉하게 할만큼 중요한 요소가 아니어야 한다. 반면 BCQ는 DDPG 데이터에서 샘플링한 주어진 배치 데이터를 가지고 offline 환경에서 효율적으로 학습한다.
논문을 읽으면서, 궁금증이 생긴 부분이 과연 관련 논문들간의 알고리즘에 사용된 배치들간의 관계가 있는지의 여부다. 참고로 논문의 저자가 알고리즘의 성능을 평가하는데 사용한 벤치마크에 대한 NeurIPS 2019 워크샵 논문이 있으니, 다음 절에서 다뤄보고자 한다.
Batch Deep Reinforcement Learning 알고리즘에 대한 벤치마킹
NeurIPS 2019 workshop에서 발표된 논문인 Benchmarking Batch Deep Reinforcement Learning Algorithms은 BCQ 논문의 동일한 저자가 작성했었는데, 이 논문에서는 통합적인 설정 상에서 배치 강화학습 알고리즘의 성능을 평가할 필요성에 대해서 주장했다. 이전의 논문에서도 밝혔다시피 offline 환경에서는 off-policy Deep RL 알고리즘은 학습에 실패하는 경향이 있었고, An Optimistic Perspective on Offline Reinforcement Learning (Agarwal et al, 2020)논문에서는 이를 해결하긴 했지만, 역시 offline 학습시 더 많은 데이터셋을 사용해야 한다는 단점이 있었다.
이 논문의 좋은 점은 배치 RL에서 사용되는 몇몇 알고리즘에 대한 서베이를 했다는 것인데, 여기에는 Quantile Regression DQN (QR-DQN), Random Ensemble Mixture (REM), Batch Constrained Deep Q-Learning (BCQ), Bootstrapping Error Accumulation Reduction Q-Learning (BEAR-QL) KL-Control 그리고 Safe Policy Improvement with Baseline Bootstrapping DQN (SPIBB-DQN) 등이 포함되어 있다. 이 알고리즘 중 QR-DQN을 제외하고는 배치 RL 설정에 특화되어 있었고, QR-DQN은 offline 설정에서 잘 동작하는 강한 off-policy 알고리즘이다.
이제, 저자인 Fujimoto가 제안했던 새 알고리즘에 대해서 소개할텐데, 이건 BCQ의 discrete한 형태라고 보면 된다. 알고리즘을 살펴보면 직관적이다.

짧게 요약하자면 상태에 기반해서 behavior policy의 행동을 예측할 수 있는, 일종의 behavior cloning network을 학습하자는 것이다. 매 \(k\)회별 Q함수에 대한 update가 발생할 때마다, 어떤 threshold를 만족하는 행동만 고려할 수 있도록 이후의 상태-행동 쌍에 대한 최대치를 변화시킨다.
$$ \mathcal{L}(\theta) = \ell_k \left(r + \gamma \cdot
\Bigg(
\max_{a' \; \mbox{s.t.} \; \frac{G_\omega(a'|s')}{\max \hat{a} \; G_\omega(\hat{a}|s')} > \tau} Q_{\theta'}(s',a')
\Bigg)
- Q_\theta(s,a)
\right) $$
그리고 테스트 시점에서 rollout을 하면서 정책을 수행할 때, 비슷한 threshold를 사용한다.
$$ \pi(s) = \operatorname*{argmax}_{a \; \mbox{s.t.} \; \frac{G_\omega(a|s')}{\max \hat{a} \; G_\omega(\hat{a}|s')} > \tau} Q_\theta(s,a) $$
(보면 알겠지만 \(a'\)이 아닌 \(a\)가 사용되고 있다)
참고로 일반적인 Q-learning과 비교했을 때, 취할 수 있는 행동의 전체 set에 대해 단순히 max나 argmax 연산을 취하고 있는 것을 알 수 있다. 이를 통해서 잠재적으로 Q value가 높은 값을 가지는 몇몇 행동들에 대해서는 무시하게 되지만 이런 행동들이 어떤 경우에는 over-estimated된 Q value를 갖는 경우도 있으므로, 좋은 효과를 불러올 수 있다.
여기에 몇가지 생각을 조금 더 덧붙이자면:
- 기존의 discrete BCQ와 비교했을 때 \(G_{\omega}\)가 continuous한 경우에는 병렬 연산이 필수적이다. 보통 이렇게 continuous한 경우에는 학습하기 복잡한 generative model을 사용할 필요가 있다. 반대로 discrete한 경우라면 단순히 behavior cloning을 수행하면 된다.
- 처음에는 loop안에서 BCQ가 \(\omega\)에 대해서 behavior cloning update를 수행하는지에 대해서 의문을 가졌었다. 학습하는 데이터가 고정되어 있기 때문에 \(\theta\)에 대한 최적화를 수행하면 초기의 몇 step을 거치는 동안 부정확한 모델에 대한 \(G_{\omega}\)로 수렴할 가능성이 있기 때문에, 어떻게보면 suboptimal한 결과가 나올 수 있다. 저자인 Fujimoto와 이야기를 한 결과, 그도 최적화 과정을 loop 이전에 수행하는 것이 좋겠다는 점에 대해서는 동의했었지만, 그렇게 조치를 하고 다시 실험해도 결과가 그렇게 좋지 않았다.
- \(\tau\)라는 계수를 설정할 수 있는데, 만약 \(\tau = 0\)인 경우에는 어떻게 될까? 결과는 간단하게도 일반적인 Q-learning이 된다. 그 이유는 generative model에서 나오는 모든 행동들이 0이 아닌 확률, 즉 적어도 한번씩은 수행되기 때문이다. 그러면 만약 \(\tau=1\)인 경우에는 어떻게 될까? 실제로는, behavior cloning으로 동작하는데 그 이유는 policy가 action을 선택할 때, Q value와는 상관없이, 온전히 \(G_{\omega}\)가 가장 큰 action만을 고려하기 때문이다. 이로 인해서 결국 Q-network을 무시하게 되므로 BCQ내에서의 Q-learning에 대한 부분이 완전히 불필요하게 된다.
- 논문에서는 \(\tau = 0.3\) 으로 설정했다.
사실 이 논문에는 이론적인 전개는 없고, 완전히 실험 위주로 작성되어 있다. 실험은 9개의 atari game 환경에서 수행되었고, 학습에 사용하기 위한 배치 데이터는 10M step에 걸쳐서 부분적으로 학습된 DQN agent로부터 생성했다. (일반적으로는 50M step을 학습시킨다) 참고로 여기에서 설계에 따른 중요한 고려사항들이 있다. (에이전트로부터 행동을 뽑을 때 두가지의 선택사항)
- 데이터를 에이전트로부터 추출할 때 single fixed snapshot (혹은 stationary policy이라고 표현할 수 있음)를 사용하거나
- 혹은 학습 과정동안 에이전트로부터 로깅된 데이터를 활용(이경우는 non-stationary policy)할 수 있다.
Fujimoto는 첫번째 경우에 대해서 고려해서 구현했고, 논문에서는 이 경우가 조금 더 현실적이기 때문이라고 언급했지만, 내가 생각하기에는 여기에는 논란의 여지가 있는 것 같다. policy가 고정되어 있기 때문에, 저자는 임의의 noise를 위해서 전체 시간 중 80% 동안에는 \(\epsilon = 0.2\)로 설정했고, 나머지에 대해서는 \(\epsilon=0.001\)로 설정했다. 사실 이 부분은 에피소드가 생성되는 시점, 즉 observation이 일어나기 전에 이미 결정되었어야 하며, 에피소드가 진행되는동안 \(\epsilon\)이 변경되는 것은 이치에 맞지 않는 것 같다.
여하튼, 이 논문에서 내릴 수 있는 결론은 무엇일까?
- Discrete BCQ는 검증한 "Batch RL" 알고리즘 중에서도 가장 최고의 성능을 보여주기는 하지만, 학습 곡선을 보면 약간 이상한 형태를 보여준다. BCQ의 성능이 noise-free policy보다 조금 좋거나 확 좋아지는 경우가 있기는 하지만, 그렇게 좋아지고 난 후에는 정체되는 현상이 나타난다. 그래서 여기에다가 조금 첨언을 하자면 base가 되는 noise-free policy의 넘어서는 것 자체는 좋지만, 문제는 해당 알고리즘도 부분적으로 학습된 DQN에서 파생되었기 때문에, 여기에 대한 단점 역시 존재한다는 점이다.
- 전형적인 off-policy 알고리즘인 DQN이나 QR-DQN, 그리고 REM 중에서도 QR-DQN의 성능이 가장 좋았지만, 여전히 noise behavior policy 처럼 성능이 좋지 않게 나오는 경우도 존재한다. 하지만 offline 설정에서 QR-DQN을 시도해보는 것 자체는, 해당 알고리즘이 수행하는 환경에 맞지 않더라도, 데이터가 충분히 많다면 취해볼 수 있는 좋은 접근 방식이라고 생각한다.
- 앞에서 소개한 Agarwal et al, 2020 논문의 일부 결과는 distributional RL이 exploitation의 도움을 받은 것으로 보여주지만, 성능이 좋았던 것은 저자가 지정한 설정에 따라서 크게 좌우된다. 논문에서는 teacher의 replay buffer에 들어있는 50M 전체 데이터를 사용했고, 여기에 변화하는 snapshot을 적용했으며, 몇몇 행동에 대해서는 noise도 추가했다.
결과에 대해서 요약하자면 아래와 같다.
BCQ가 가장 좋은 성능을 보여주기는 하지만, 대부분의 atari game에서는 online DQN과 같은 성능을 보여주며, 사실 online DQN이 BCQ안에 포함되어 있는 noise-free behavior policy이기 때문이다. 결과를 놓고 보자면 BCQ는 강력한 imitation에 가까운 성능을 보여주는 것이지, 탐색 데이터가 제한되어 있는 화녕에서의 진짜 batch RL과는 거리가 있어보인다.
이 논문을 읽고 난 후에 든 한가지 질문은 "과연 noise-free behavior policy를 넘어서면서 offline RL을 수행할 수 있을까?" 였다. 사실 이 것이 우리가 꿈꾸는 방향일 것이다.
Bootstrapping Error Reduction을 통해서 Off-policy Q-learning 안정화시키기
NeurIPS 2019에서 발표된 이 논문은 앞에서 다뤘던 Fujimoto의 BCQ 논문과는, Q-learning을 완전 off-policy 컨셉으로 수행할 때, action에 대한 distribution에 제한을 두는 것에 초점을 맞춘 알고리즘이라는 점에서 관련성이 크다. 이 부분은 abstract에서 bootstrapping error라는 개념으로 묘사되어 있다.
우리는 현재 방법론에서 bootstrapping error가 불안정성을 야기하는 핵심요소로 판별했다. Bootstrapping error란 학습 데이터 분포 이외의 영역에 놓여 있는 행동으로부터 bootstrapping함으로써 발생하는 error이며, Bellman Backup operator에 의해서 누적된다. 논문을 통해서 이론적으로나마 bootstrapping error를 분석하고, backup내에서 action 선택을 제한함으로써 이 error를 완화시키는 방법에 대해서 소개한다.
처음 이 논문을 봤을 때 생각한 것은, (fujomoto et al. 2019)에서 소개된 extrapolation error과 bootstrapping error간의 차이가 무엇이냐 하는 것이다. 두 항 모두 Q-learning 동안 부정확한 Q-value를 추구하면서 생기는 동일한 문제에서 활용할 수 있다. 하지만 extrapolation error는 지도학습 문맥에서 파생된, 조금 더 넓은 범위의 문제인 반면, bootstrapping error는 bootstrapped estimates에 의존하는 강화학습 알고리즘에 특화된 문제이다.
논문의 저자들이 BAIR에 쓴 블로그 포스트는 읽어볼 것을 강력하게 권하는데, 그 이유는 이 포스트에서 고정된 데이터셋으로 학습시킬 때 bootstrapping error가 offline Q-learning에 영향을 미치는 것에 대한 직관적인 내용을 소개하고 있기 때문이다. 예를 들어서
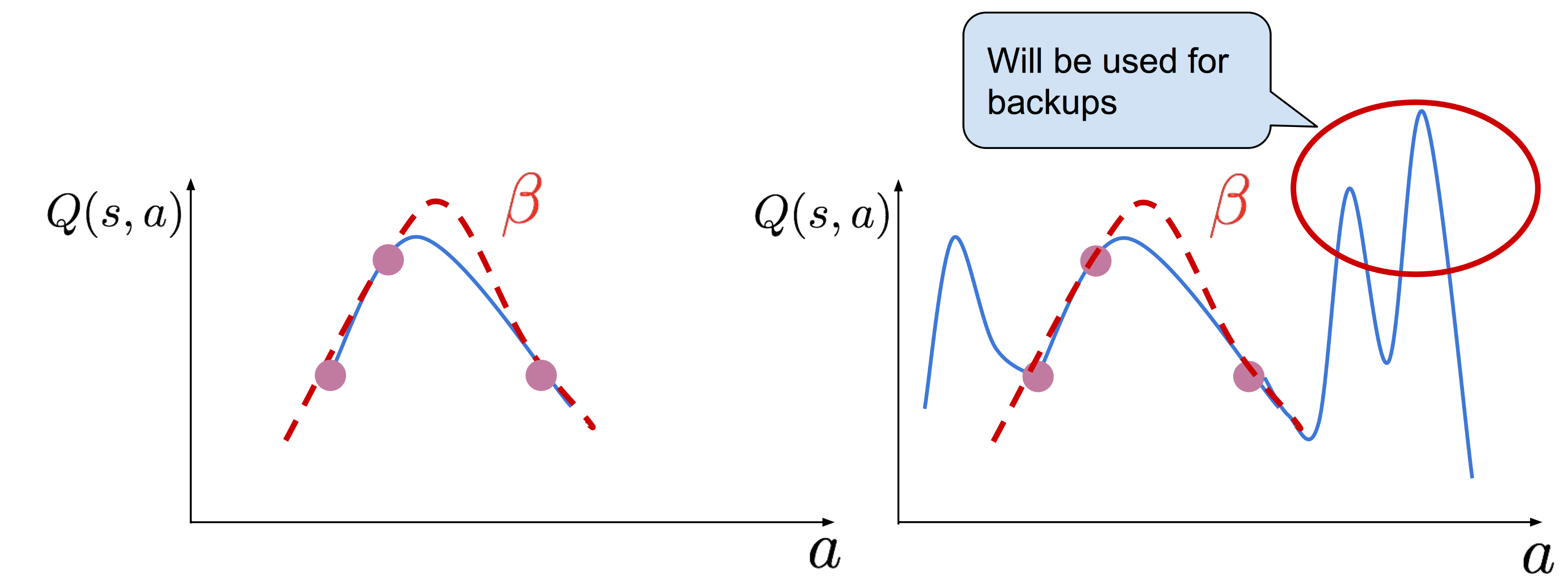
위의 그림 중 두번째 그림에서는 behavior policy \(\beta(a \vert s)\)에서 도출한 action들의 분포에서 벗어난 행동 \(a\)가 있다고 가정하고 이를 점선으로 표기했다. (참고로 OOD는 out-of-distribution의 약자이다) 불행하게도 그런 행동들이 매우 큰 \(Q(s, a)\)를 가진다면, Q-learning 에서의 갱신시 사용될 target을 만드는 bootstrapping 과정에서 사용되게 된다.
또한 만약 이를 (offline이 아닌) off-policy RL 알고리즘을 수행할 경우, dataset의 크기를 단순히 증가시켜도 성능 문제를 해결할 수 없다는 것을 보여준다. 이 때문에 이후 연구에 대한 필요성이 제기되었다.
위 논문에서 주요 핵심은 다음과 같다.
- Q-learning이 error에 대한 propagation을 해결할 수 있도록 행동을 신중하게 선택하는 것에 대한 이론적인 분석
- "Bootstrapping Error Accumulation Reduction" (BEAR) 라고 알려진 실용적인 알고리즘 도출
BEAR 알고리즘은 아래와 같이 도식화할 수 있다.

핵심은 학습된 policy가 고정된 data에 대한 action distribution의 support와 일치시켜 주도록 알고리즘이 보장해준다는 것이다. 반대로 앞에서 소개한 BCQ같은 알고리즘은 분포 자체에 대한 일치에 초점을 맞추고 있다. 이런 특징은 사실 강력한 것인데, 단순히 support에 대한 일치 여부만 필요한 것은 문제에 대한 가정을 훨씬 약하게 해줘서, Offline RL이 넓은 범위의 action에 대해서 유연하게 고려할 수 있도록 해주기 때문에, 어떤 특정 상태에서는 데이터에 대한 배치가 이런 action들을 무시할 수 없는 확률로 사용된다.
이런 원리를 실제로 적용하는 것을 뒷받침하기 위해서, BEAR에서는 Maximum-Mean-Discrepancy (MMD) Distance라고 하는, 알려지지 않은 behavior policy \(\beta\)와 actor policy \(\pi\)에 들어있는 action들간의 거리를 나타내는 수치를 사용했다. 이 값은 샘플링을 통해서 직접적으로 추정할 수 있다. 이 모든 것은 적용하게 되면. 논문의 공식 q에서 소개되어 있는 actor-critic에서의 policy improvement 는 아래와 같이 이뤄지게 된다.
$$ \pi_{\phi} := \max_{\pi \in \Delta_{\vert S \vert}} \mathbb{E}_{s \sim D} \mathbb{E}_{a \sim \pi(\cdot \vert s)} \big[ \min_{j=1, \dots, K} \hat{Q}_j(s, a) \big] \quad \text{s.t.} \quad \mathbb{E}_{s \sim D} [\text{MMD}[D(\cdot \vert s), \pi(\cdot \vert s))] \le \epsilon $$
이 수식에 대한 설명은 논문에 언급되어 있지만, 간단하게 설명하자면, \(D\)는 behavior policy \(\beta\)에 의해서 수집된 transition에 대한 static data를 나타내고, 첨자로 표기되어 있는 \(j\)는 Q-value에 대해서 보수적으로 추정하기 위해서 사용되는 Q function들의 집합(ensemble)을 나타내기 위해서 사용되었다. 사실 이 부분은 앞에서 언급한 MMD constraint와 비교했을 때는 policy update 측면에서는 그렇게 흥미로운 관점이 아니기도 하고, 사실 BAIR에서 언급된 블로그 포스트에서도 policy update시 ensemble이 표함되어 있지는 않다. 여기서 내가 말할 수 있는 것은 단일 혹은 2개의 Q network(ensemble을 적용한 방식과 MMD constraint를 적용한 방식)만 가지고 실험할 수 있는 연구는 존재하지 않다는 것이다. 그래서 두 방식 중 어떤 것이 더 중요한지는 개인적으로 궁금하다.
BEAR 알고리즘과 가장 유사한 알고리즘은 앞에서 언급한 BCQ(Fujimoto et al. 2019)인데, 이 두 알고리즘의 차이는 무엇인가? BEAR 저자(Kumar et al. 2019)는 다음 내용에 대해서 언급하고 있다.
- BEAR는 조금 더 완화된 가정상에서도 수렴하는 특성을 보여주며, 이 접근 방법을 통해서 어느 정도의 suboptimality를 달성할 수 있다.
- BCQ는 기본적으로 전문가에 의해서 수집된 off-policy data가 있을 때 잘 동작하지만, BEAR는 조금 약한 policy (어쩌면 random policy가 될 수도 있다)에 의해서 수집된 데이터에서 더 잘 동작한다. 이는 BCQ가 action의 분포에 대해서 너무 강력한 제한을 두었기 때문이라고 생각하며, 이 부분은 BCQ가 데이터 배치에서의 policy에 대한 분포를 일치시켜야 하지만, BEAR는 단순히 action을 뒷받침할 수 있는 것에 대해서만 일치시키면 되는 부분에서 어느정도 일맥상통한다.
여기까지 읽었을 때, 문득 위 알고리즘들의 장점들을 모은 방법이 있는지에 대해서 궁금해졌다. 또한 MuJoCo 시뮬레이터가 이런 알고리즘들을 검증할 수 있는 가장 좋은 방법이라는 주장에 대해서 완전히 반박하기 어렵기 때문에, BEAR와 BCQ를 조금 더 확장해서 비교할 수 있는 미래의 데이터셋을 찾기을 있으면 좋겠다.
여기에서부터, 이제 두번째 주제에 대한 논문들을 다룰 것인데, 어떤 측면에서 action에 제한을 주기보다는 일반적인 off-policy Deep RL알고리즘의 exploitation 능력을 최대화하면서 크고 광범위한 데이터셋 기반에서 어떤 현상이 나타나는지 이해하는데 초점을 맞추고자 한다.
Offline RL에서의 낙관적 관점
이전의 논문들에서는 고려된 행동들의 조합에 대해 제한을 두는 알고리즘을 소개한 반면, 이 논문에서는 반드시 뭔가에 특화된 Offline RL 알고리즘을 사용할 필요할 필요가 없다고 주장한다. 대신, 뎌 나은 exploitation 능력을 가지는 강력한 off-policy Deep RL알고리즘을 사용하라는 것이다. 특히 내가 이 논문에 대해서 흥미로웠던 것은 이 논문이 off-policy RL에 대한 관점을 제공했기 때문이며, 논문에서 수행된 실험들도 명확하면서, 이해하기 쉬웠기 때문이다. 놀랍게도 이 논문은 ICLR 2020에서 떨어졌었고, 사실 수많은 배경 실험에 대한 결과를 포함한 이 논문이 떨어진 것에 대해서는 의구심을 가지고 있다. 평가자도 왜 Offline RL에 대해서 신경써야 하는지에 대해서 물었었고, 저자들도 이에 대한 답을 주기도 했다. (다행이도, 이 논문은 ICML 2020에서 통과되었다.)
이 논문의 실험과 기여에 대해서 간단하게 요약하면 다음과 같다. 참고로 이 논문이나 그림에 대해서 언급할 때, 내가 참고한 것은 arXiv에 올라가 있는 두번째 버전에 대한 것이고, 이 논문은 ICLR 2020에 제출된 내용이며, "Offline RL" 대신 "Batch RL"이란 개념을 사용했기 때문에 여기에서도 이 두 용어를 같이 사용하고자 한다. 또한 이 논문은 원래 "Striving for Simplicity in Off-Policy Deep Reinforcement Learning" 이란 제목을 가지고 있었다.
- Offline RL에 대한 배치 데이터를 생성하기 위해서, 일반적인 online DQN을 50M step만큼 학습시키면서 기록된 데이터를 사용했다. 일반적으로 한 step은 4개의 환경 프레임으로 구성되어 있기 때문에, 총 200M 프레임으로 구성되어 있는 것과 동일하며, 결국 Atari 벤치마크에서 사용하는 표준과 동일하다. 내가 생각하기에는 일반적으로 학계에서는 1 step을 4개의 frame으로 구성하는 것으로 형식화된 것 같다. 아무튼 (Machado et al, 2018)에서 소개된 바와 같이, stochasticity를 유발하기 위해서 에이전트는 sticky action을 하게 된다. 그래서 기록된 데이터가 주어진 상태에서 Batch RL을 수행하게 되면, 50M 크기의 replay buffer를 가지는 off-policy Deep Q-learning을 수행하게 되고, replay buffer로부터 경험을 균등한 확률로 샘플링하게 되는 것이다.
- 이 논문에서는 off-policy 분산기반의 Deep RL알고리즘인 Categorical DQN (C51이라고 알려져 있다.)과 Quantile Regression DQN (QR-DQN)을 순전히 기록된 데이터만 가지고 학습시켜도 (이 조건이 offline 설정이 되겠다.) online DQN보다 더 좋은 성능을 보여줬다. 예를 들어서 논문의 그림 2를 살펴보면 된다. 참고로 논문에서 주장하는 것에 주의할 내용이 있는데, C51과 QR-DQN은 이미 vanila DQN 보다 좋은 성능을 보여주는 것을 보여준다고 알려져 있지만, 실제 실험에서는 두 방법에서 탐색 기능을 제거했음에도 여전히 online DQN( 혹은 exploration을 하는) DQN보다 좋은 성능을 보여준다는 것이다.
- 우연히도 offline C51과 offline QR-DQN 역시 offline DQN보다 좋은 성능을 보여주는데, 예상했던 바와 같이 offline DQN은 online DQN보다 나쁜 것으로 알려져 있다. (객관적으로 보자면, 그림 2에서는 전체 60 게임 중 10-15 게임 정도는 offline DQN이 online DQN보다 좋은 성능을 보여주는 것을 확인할 수 있다.) 이 때 수행했던 실험들이 exploitation으로부터 exploration을 분리했기 때문에, 우리는 offline DQN과 offline C51, offline QR-DQN간의 성능 차이는 exploitation 기능의 차이 때문이라는 것을 알 수 있다.
- 그렇기 때문에 알고리즘의 성능을 게임 점수로 평가하여 나쁜 순부터 좋은 순으로 나열하면 offline DQN, online DQN, offline C51, offline QR-DQN 등으로 볼 수 있다. 참고로 논문에서는 부록에 소개된 몇몇 게임을 제외하고는 offline C51에 대한 전체 결과를 소개하지는 않았지만, 내가 추측하건데 QR-DQN이 offline과 online 경우에서 모두 좋은 성능을 얻었을 것 같다. 추가로, 적어도 offline C51과 QR-DQN이 순수 DQN이 생성한 데이터만 가지고 학습했다면, 이 알고리즘들보다는 online C51과 online QR-DQN의 성능이 더 좋지 않았을까 생각한다.
- off-policy Deep RL알고리즘이 Batch RL 설정에서 더 잘 동작할 수 있는 것에 대한 증거를 추가하기 위해서 논문에서는 그림 4를 통해 충분한 성능을 얻을 수 있는 DQN에 대한 RMSprop를 optimizer로 사용하지 않고, Adam을 사용했다. 이를 통해서 offline DQN이 평균적으로 online DQN의 성능보다 더 좋은 것을 보여줬다. 사실 Adam이 그렇게 큰 개선점을 제공하지 않기 때문에 이 결과를 신뢰할 수 있을지에 대해서는 의문이긴 하다.
- 논문에서는 DDPG를 학습시키면서 기록된 데이터 중 백만개의 샘플링 데이터를 사용하면서 continuous control에 대한 차이에 대해서도 실험했다. 논문에서는 위에서 논의했던 것처럼 (Fujimoto et al, 2019)에서 Batch-Constrained Q-learning를 적용했고, 이 알고리즘도 합리적으로 잘 동작한다는 점도 확인했다. 하지만 또한 (Fujimoto et al, 2018) (앞에서 논의한 BCQ 논문의 저자이기도 하다) 논문에서 Twin-Delayed DDPG (TD3라고 알려져있다)를 간단하게 사용하고, 일반적인 off-policy 형식으로 학습하면서 offline DDPG보다 더 좋은 결과를 얻을 수 있다는 점도 확인했다. TD3가 DDPG보다는 조금 더 강력한 off-policy의 continuous control deep Q-learning으로 알려져 있기 때문에, 이 결과를 통해서 효과적인 Batch RL을 위해서는 강력한 off-policy 알고리즘만 있으면 된다는 사실을 뒷바침할 수 있게 되었다.
- 결과적으로 위의 관찰된 결과를 통해서 저자들은 Random Ensemble Mixture (REM)라는 알고리즘을 제안했는데, 이 알고리즘은 Q-network에 대한 ensemble을 사용하고, random convex 조합들간의 bellman consistency를 유지하도록 해줬다. 어떻게 보면 이 방법은 Dropout이 동작하는 것과 유사하다. REM은 offline 형태와 online 형태가 존재하는데, offline 형태에서는 REM은 구조가 단순함에도 불구하고, C51과 QR-DQN 보다 성능이 좋았다. 여기에서 "단순함"을 통해서 저자들은 이전의 distributional 기법들이 했던 것처럼 주어진 상태에 대한 가치 함수의 전체 분포를 추정한 것을 사용하지 않아도 되었다.
사실 위의 내용이 그들이 한 전부는 아니었다. 이 논문의 과거 버전에서는 QR-DQN을 학습시킬 때 기록된 데이터를 바탕으로도 실험했었다. 하지만 이 논문의 주 저자가 언급하기로는 너무 많은 실험들을 통해서 읽는 사람들에게 혼란을 줄 수 있었기 때문에 이 실험들에 대한 결과를 배제하였다. 추가로 QR-DQN을 학습시킬 때 얻은 기록된 데이터에 대해서 언급하자면, online QR-DQN의 성능을 넘어서기 위해서는 정말로 강력한 off-policy Deep RL 알고리즘을 학습할 필요가 있었다. 나도 이부분에 대해서 인정했던 것이, 사실 이 논문에서 수행된 모든 실험들을 따라가기 어려운 점도 존재했었다.
아래의 그림은 이 논문과 관련된 몇몇 알고리즘(DQN, QR-DQN, Ensemble-DQN(baseline) 그리고 REM(논문에서 제안된 알고리즘)에 대한 시각화 결과이다.

이 논문을 읽으면서 느꼈던 가장 큰 점은, Offline RL에서는 데이터의 quality가 매우 중요하고, 하나의 고정된 정책보다는 여러 개의 서로 다른 정책들로부터 얻은 데이터를 사용하는 것이 훨씬 낫다는 점이었다. 논문에서도 알고리즘을 학습시키면서 기록된 데이터를 사용했었는데, 이 설정을 해석해보자면, 매 4 스텝마다 정책 parameter에 대한 gradient update가 이뤄지고, 이를 통해서 정책 자체가 변화하게 되는 것이다. 이를 통해서 Offline RL에서 데이터에 대한 다양성을 확대시킬 수 있었다. 실제로 (Fujimoto et al, 2019)에서는 REM과 off-policy 알고리즘들이 좋은 성능을 보일 수 있는 원동력은 학습 데이터의 구성에 따라 달라진다고 주장했다. 그렇기 때문에 앞에서 소개한 논문들이 서로 모순을 주장하는 것이 아니냐고 생각하는 것은 옳지 않다. 오히려 이 알고리즘들은 같은 목표를 달성하기 위한 서로 다른 방법들에 대해서 제안했다고 생각하는 것이 정확할 것이다. 어쩌면 제일 좋은 방법은 단순하게 강력한 off-policy 알고리즘을 사용하면서 엄청나게 큰 데이터를 사용하는 것이면서, 이런 off-policy 알고리즘을 batch 설정에 맞게 특화하는 것일지도 모르겠다.
IRIS: 오프라인 로봇 manipulation data로부터 interation 없이 제어를 학습하기 위한 함축적 강화
이 논문은 IRIS: Implicit Reinforcement without Interaction at Scale 이란 알고리즘에 대해서 제안했다. 이 알고리즘은 대단위의 로보틱스 데이터로부터 offline 학습을 하는 것에 특화되어 있는데, 이 데이터에는 부가적으로 최적화되어있는 것도 있고, 고도로 multi-modal이 되어 있을 수도 있다. 이 알고리즘은 이번 포스트에서 내가 소개한 다른 논문들처럼 Batch RL 형태를 따르고 동일한 off-policy 알고리즘으로부터 파생되었는데, 이 논문에서는 그 논문들을 많이 인용되어 있다는 사실도 발견했다.
이 알고리즘은 아래와 같이 시각화할 수 있다.

논문의 내용을 요약하면 아래와 같다.
- IRIS에서는 제어를 "high-level"과 "low-level" controller로 나눠서 살펴보았다. high-level mechanism을 따르게 되면 주어진 state \(s_t\)에서는 반드시 새로운 목표 state인 \(s_g\)를 뽑아야 한다. 이후에 low-level mechanism이 해당 목표 state에 대한 조건을 두어서 취해야 할 행동 \(a \sim \pi_{im}(s_t \vert s_g)\)을 뽑아내게 된다.
- high-level policy도 두 부분으로 쪼개서 살펴볼 수 있다. 첫번째 policy는 몇몇 목표가 될만한 state action pair를 샘플링하게 되고, 두번째 policy가 샘플링한 pair 중 가장 좋은 목표 pair를 low-level controller에게 전달한다.
- low-level controller에서는 주어진 목표 state \(s_g\)에 대해서 해당 목표에 해당되는 action \(T\)를 취한다. 그리고 나서 high-level policy에게 control을 반환하여 goal state를 다시 샘플링할 수 있게끔 해준다.
- 전체 에피소드는 에이전트가 실제 목표 state에 충분히 가까워지면 종료되게 된다. 이 때 전체 환경은 continuous state domain, 즉 연속성을 띄고 있기 때문에 이 가까운지 여부를 확인하기 위해서 해당 state에 대한 거리 threshold를 뽑는다. 또한 해당 환경이 sparse reward domain, 즉 reward가 희소하기 때문에 이에 따른 어려움이 존재한다.
그러면 각 요소들은 어떻게 학습시킬까?
- high-level controller의 첫번째 부분은 목표에 대한 조건부 VAE (Conditional Variational AutoEncoder - cVAE)를 사용한다. 그래서 데이터에서 state에 대한 sequence가 주어졌을 때, IRIS는 해당 시점에서 \(T\) 시점 만큼 이후에 대한 state-action pair(즉 \((s_t, s_{t+T})\) 내의 데이터들)를 샘플링한다. 이때 cVAE의 encoder \(E(s_t, s_{t+T})\)에서는 latent variable들의 집합에 대한 tuple들을 gaussian distribution을 띄게끔 매핑한다. 예를 들어서 \(\mu, \sigma = E(s_t, s_{t+T})\)와 같이 말이다. 그러면 decoder는 미래의 state에 대해서 \(\hat{s}_{t+T} \sim D(s_t, z)\)와 같이 만들어낼 수 있어야 하는데, 이 때 \(z\)는 앞에서 구한 \(\mu\)와 \(\sigma\)를 가지는 gaussian distribution에서 샘플링한 것이다. 이렇게 뽑은 데이터는 학습할 때 사용하는 것이고, 검증 시점에서는 일반적인 표준 정규 분포에서 \(z\)를 샘플링하여 (\(z \sim \mathcal{N}(0, 1)\)) 사용한다. 결과적으로 이렇게 하면 학습하면서 regularization이 되는 효과를 얻게 되는데, 이를 decoder에게 통과시키고, 마지막으로 goal state를 뽑게 된다.
- high-level controller의 두번째 부분에서는 (이 포스트의 서두에서 소개했던) Batch Contrained Deep Q-learning (BCQ)의 변형된 형태를 일부로 취하는 action cVAE를 사용하여, high-level controller의 value function으로 활용한다. 이 cVAE는 goal를 예측한다기 보다는 주어진 state에 맞춰진 action을 예측하게 된다. 이 때, cVAE는 샘플링된 state-action pair (\(s_t, a_t\))를 샘플링해서 예측값이 \(a_t\)가 나올 수 있도록 학습시킬 수 있다. 이렇게 하면 cVAE가 학습 데이터의 일부로써 action을 모델링할 수 있기 때문에 이를 BCQ에 접목시킬 수 있게 된다.
- low-level controller는 RNN으로 되어 있는데, 주어진 \(s_t\)와 \(s_g\)에서 \(a_t\)를 뽑을 수 있도록 되어 있다. 이 신경망은 behavior cloning으로 학습시키기 때문에, 더이상 Batch RL을 사용하는 영역이 아니다. 그러면 어디에서 goal을 얻을 수 있을까? 간단하다. 이미 IRIS가 앞에서 언급한대로 정해진 step (\(T\))에서만 low-level controller를 동작시키기 때문에, 길이가 \(T\)인 state-action sequence를 뽑게 되고, 그러면 마지막 state를 goal로 취급할 수 있게 되는 것이다. 직관적으로 이렇게 학습된 low-level controller는 \(T\) step 동안 시작 state에서 "goal" state에서 어떻게 동작해야 되는지를 알게 된다. 참고로 여기서 "goal"이라는 것은 실제 환경의 goal이 아닌 학습을 위해서 인위적으로 설정한 것을 말한다. 이 개념은 내가 이전에 다뤘던 Hindsight Experience Replay의 개념을 상기시켜 준다.
여기서 몇가지 고려할 부분이 있다.
- 저자들이 주장하기로는 IRIS가 다양한 solution을 다룰 수 있게끔 할 수 있다고 하는데, 이는 goal cVAE가 명시적으로 다양성을 부여하여 다양한 goal들을 샘플링할 수 있기 때문이다. 반면 low-level controller는 주어진 시간 "resolution"에 대한 short-horizon goal만 모델링할 수 있는데, 이로 인해서 다양한 solution을 쉽게 뽑을 수 없다.
- 또한 IRIS는 off-policy data를 처리할 수 있는데, 알고리즘에서 사용한 BCQ가 생성된 데이터에 대해서 action이 제한되고, 이로 인해서 goal를 선택하기 위해서 사용될 가치 함수가 정확해지기 때문이다.
- 저자들은 IRIS를 high level과 low-level controller로 나눴는데, 이는 이론적으로 이런 구조가 suboptimal한 문제를 처리하는데 도움이 되기 때문이다. 그래서 high-level controller는 높은 가치를 가지는 goal를 선택하게 되고, low-level controller는 단순히 A에서 B까지만 가면 되는 것이다. 이런 계층적 구조는 일반적으로 사람들이 좋아하는 구조이기도 하다.
사실 논문에서 Batch RL을 사용한 부분은 흥미로운 부분이다. 어떤 정책을 학습시키기 위해서 Batch RL을 사용하지 않고, 단지 가치 함수를 학습시키는데 사용했기 때문이다. 이로 인해서, 이 논문은 어떻게 보면 off-policy RL을 다뤘던 논문들과 유사한 것처럼 보일 수 있으나, 여기에서는 단순히 state를 평가할 목적으로만 활용했다. 또한 왜 저자들이 BCQ의 변형된 형태가 단순한 것이라고 주장했을까? 내가 생각하기에는 저자들이 perturbation model을 학습하는 것을 꺼려했던 것이 아닐까 싶은데, 이렇게 되면 이 model이 candidate로 사용되는 action들을 혼란? 섭동시키지 않았을까 하는 것이다. 또한 그들은 twin critic 구조를 사용하지 않았다.
논문에서는 IRIS를 세개의 데이터로 검증했다. 이중 두 개는 그들이 이전에 만들었던 RoboTurk라는 것인데, 이에 대한 내용은 stanford AI 블로그에서 확인할 수 있다. 사실 나도 이전에 RoboTurk를 사용해보지 않았기 때문에 논문의 결과를 이해하기가 어려웠던 점은 있었다.
- Graph Reach: 논문에서는 2D로 이뤄진 단순한 경로 탐색 예제를 사용했는데, 이 예제는 어쩌면 인위적이면서도 여러 목적을 고려하거나 suboptimal demonstration를 검증하기 쉽게끔 되어 있다. Ken Goldberg 교수 연구실에서 발표한 SAVED (Safety Augmented Value Estimation from Demonstrations) 논문처럼 suboptimal 상황에서의 검증을 위해서 경로 탐색 문제를 사용하는 경우들이 종종 있다.
- Robosuite Lift: 이 예제는 Robosuite lift 예제(참고로 robosuite는 mujoco 기반의 simulation framework이다)와 관련되어 있는데, 이 문제는 RoboTurk를 사용해서 시뮬레이션 상에서 단일 인간이 물체를 드는 것이다. 사실 인간은 이 경우 내부적으로 suboptimal demonstration을 사용한다.
- RoboTurk Can Pick and Place: 이제 물건을 집고 옮기는 문제인데, RoboTurk를 사용하면 서로 다른 사람들이 제어하면서 다양한 샘플들을 수집할 수 있게 된다. 이 것에 대한 전반적인 내용은 앞에서 언급한 것처럼 Stanford AI 블로그에서 확인할 수 있다. 참고로 나는 RoboTurk를 사용해보진 않았지만, 지금까지 검증한 환경 중에서는 가장 자연적인 것처럼 보이긴 한다.
이 문제들에 대해서 IRIS는 이상적인 베이스라인이라고 할 수 있는 BCQ와 비교했다.
결과적으로 봤을때 이 논문은 이번 글에서 소개하고 있는 "행동에 대해 제한을 두는" 알고리즘과 "거대한 데이터셋으로부터의 학습(learning from large scale datasets)"이 섞인 형태라고 생각한다. 그리고 처음으로 offline RL이 robot manipulation의 일부분으로 사용될 수 있다는 것을 보여주기도 했다. 이와 유사한 작업을 한 프로젝트도 있는데, DeepMind에서 실제 로봇을 대상으로 한 것이며, 바로 우리가 다음에 다룰 주제이기도 하다.
Reward Sketching과 Batch RL을 활용하여 데이터 기반의 Robotics 확장
이번에 다룰 DeepMind 논문은 ("NeverEnding Storage"라고 하는) 크고 어마어마한 오프라인 데이터셋을 강력한 off-policy RL 알고리즘과 묶었을때의 이점을 부각한다. 그래서 강화학습과 HCI, database 시스템이 결합되었을때 어떤 것이 가능한지를 보여준다. 논문에서는 크게 5개의 단계로 접근하는데, 아래 그림에서 잘 설명했다.

위 과정에 대해서 자세히 설명하자면,
- Demonstration. 이 데모는 다양한 원천이 존재한다. 사람이 직접 수행한 것일 수도 있고, 스크립트로 구현한 정책일 수도 있고, 혹은 학습된 정책일 수도 있다. 우선 데이터는 사람이 직접 수행하거나 스크립트 정책으로부터 뽑는다. 하지만 로봇이 해당 일에 대해서 학습하고 계속 수행하고자 할때, 로봇이 쌓은 trajectory는 NeverEnding Storage에 저장한다. 부수적으로 이 논문에서는 여러 task 환경을 고려했기 때문에, 하나의 정책은 다양한 task에 대해서 수행하게 되는데, 각각 시작 조건이나 나름의 reward를 가지는 형태를 띄게 된다.
- Reward Sketching. 사람에 의해서 선택된 데이터의 일부는 reward를 나타내기 위한 것이다. 이 부분은 인간이 관여된 부분이기도 하고 reward design이 사실 매우 어렵기 때문에 매우 신중을 기해야 하며, 매 프레임별로 숫자를 일일이 메겨야 하는 사람으로는 절대 진행할 수 없다. (내가 이 일을 직접한다고 생각하면 거의 토할 것 같다) 논문의 저자들은 인간들이 상식적으로 reward를 sketch할 수 있도록 GUI를 구성했고, 이를 reward sketching이라고 이름지었다. 이 과정을 통해서 매 프레임별로 0~1사이의 reward를 유연하게 설정할 수 있다.
- Learning the reward. 이 시스템에서는 (이미지가 들어오는 상황에서) 프레임으로부터 task별 reward를 예측할 수 있는 reward function neural network \(r_{\psi}\)를 학습시킨다. 뭔가 곧바로 어떤 값을 도출하기보다, 논문에서 시도한 것은 동일한 에피소드 상에서 두개의 프레임 \(x_t\)와 \(x_q\)를 가지고 hinge loss를 통해 reward function의 일관적인 조건을 계속 유지키는 것과 관련있다. 그래서 만약 reward function이 update되면, NeverEnding Storage에 저장되어 있는 매 타임스텝별 reward를 다시 재정의 할 수 있게 되는 것이다.
(작성중)
'Study > AI' 카테고리의 다른 글
| [RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl) (0) | 2022.04.19 |
|---|---|
| [RL][Review] Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (BEAR) (0) | 2022.04.13 |
| [RL][Review] Off-Policy Deep Reinforcement Learning without Exploration (BCQ) (2) | 2022.04.12 |
| [RL] Windows에서 Dopamine 설치 (0) | 2021.12.22 |
| [RL] MuJoCo 2.1.0 무료 공개 (5) | 2021.10.21 |
| [DL] Figure KL Divergence (0) | 2021.09.13 |
| [DL][Embedded] Semantic Segmentation on Coral Dev board (0) | 2021.08.20 |
- Total
- Today
- Yesterday
- Kinect for windows
- Offline RL
- Pipeline
- Off-policy
- dynamic programming
- DepthStream
- 파이썬
- Distribution
- ColorStream
- bias
- RL
- TensorFlow Lite
- SketchFlow
- Kinect
- 한빛미디어
- PowerPoint
- 강화학습
- reward
- Expression Blend 4
- 딥러닝
- End-To-End
- arduino
- processing
- Windows Phone 7
- Policy Gradient
- Variance
- 인공지능
- Gan
- Kinect SDK
- windows 8
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |