
티스토리 뷰
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다)
이전 포스트를 통해서 강화학습 상에서의 Model의 정의에 대해서 소개하고, Model을 통해서 생성한 simulated experience를 바탕으로 model을 update하는 Planning에 대해서 다뤘다. 사실 이런 planning과정과 별개로 실제 environment로부터 얻은 experience를 바탕으로 update하는 것을 Direct RL이라고 표현한다. 이번 포스트에서 소개할 Dyna algorithm (sutton)은 앞에서 소개된 Planning과 Direct RL이 결합된 형태로 되어 있다.

우선 기존의 Q-learning과 마찬가지로 실제 environment로부터 experience(혹은 trajectory)를 얻어 value function을 update하는 과정은 동일하다. (direct RL update)
$$ Q(s,a) \leftarrow Q(s,a) + \alpha \big(r + \gamma \max_{a'}Q(s',a') - Q(s,a) \big) $$
이제 차이가 있다면 이 experience를 value function을 update하는데 뿐만 아니라, Planning할때 model을 update하는데도 활용한다는 것이다. (model learning) 이 model을 바탕으로 기존의 environment로부터 experience를 얻는 것과 동일하게 가상의 experience를 뽑아낸다. (search control) 사실 value function입장에서는 update를 하는 목적을 가진 이상, 해당 experience가 model에서 나왔는지, 실제 environment에서 나왔는지 상관하지 않는데, 이렇게 얻은 가상의 experience를 가지고 value function를 update하는 과정까지가 Q-planning이 수행되는 절차이다.(planning update)
$$ Q(s,a) \leftarrow Q(s,a) + \alpha \big(r + \gamma \max_{a'}Q(s',a') - Q(s,a) \big) $$
(사실 Q-learning이나 Q-planning이나 value function을 update하는 과정은 위에서 보는 것처럼 동일하다.)
강의에 소개되었던 예제를 잠시 다뤄보면,
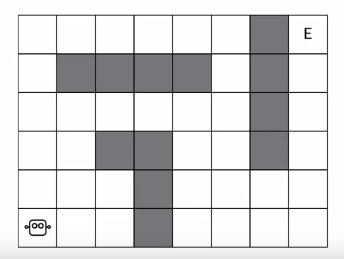
위의 그림과 같이 좌측 하단의 robot이 E로 표시된 goal까지 도달하는 Maze가 있다고 가정해보자. 그럼 처음 episode에서는 robot도 exploration을 하면서 자기가 간 state에 대한 value function을 만들 것이다. 이 모든 과정은 실제 Maze에서 이뤄지는 것이다. 참고로 노란색 칸은 robot이 지나간 부분이고, 흰색은 지나가지 않은 부분이다. 노란색의 경우 robot이 해당 칸을 거쳐서 최종 goal에 도달했기 때문에 이를 통해서 해당칸에서 next state에 어떤 일이 일어날 것인지 알게 된다. 결국 value function을 update할 수 있게 된다. 반면 흰색은 지나가지 않았기 때문에 해당칸에 도달했을 경우 next state가 어떻게 될지는 장담할 수 없다. 그래서 value function을 update할 수 없다.

그리고 이렇게 한번 쌓은 경험으로 robot이 내부적으로 Planning을 하게 된다. 이때는 실제 Maze가 아닌 쌓은 경험(노란색으로 표기된 부분)에 기반한 Model에서 value function을 update하게 된다. 게임으로 따지면 replay하는 것이라고 보면 좋을거 같다.

충분한 Planning 과정을 거치면 robot이 가지고 있던 model의 value function이 update될 것이고, 이렇게 되면 노란색칸에 대해서는 어떤 action이 optimal한지 알게 된다는 것이다. 즉, 해당 칸에 대해서 그나마 optimal한 policy를 구할 수 있다는 것이다.

이렇게 Planning을 통해서 학습된 model을 실제 environment에 적용해보면, 그래도 기존처럼 하나씩 해보면서 policy를 update하는 것에 비하면 더 빠르게 optimal policy를 찾을 것이다.

물론 아직 하얀 칸(방문하지 않은 state)에 대한 value function이 정의되지 않았기 때문에, 다른 exploration이 가미되어야 하지만, 대략적으로 Dyna가 적용된 agent는 이렇게 Q-learning과 Q-planning이 결합된 형태로 model과 policy를 학습하는 과정을 거친다. (Q value function(or state-action value function)이 기반이 되기 때문에 Dyna-Q라고 표현하기도 한다.) 구조는 아래와 같다.

사실 (a)~(d)까지의 과정은 앞에서 소개한 바와 같이 전형적인 Q-learning 과정과 동일하다. 이 부분이 우리가 direct RL이라고 표현하는 부분이고, Dyna-Q에서는 direct RL외에도 앞에서 소개한 것처럼 model learning과 search control, model update 과정이 더해진다. (e) 부분이 바로 model learning에 해당하는 부분인데, 여기서 알고리즘은 model에서 나온 next_state와 reward를 기억하는 역할을 수행한다. 참고로 여기서 유념해야 할 것은 model을 학습시킬 때의 environment가 deterministic이라는 것을 가정한 상태에서 학습한다는 것이다. 다시 말하자면, model에 어떤 action과 state를 넣었을 때 나오는 next_state와 reward가 상황에 따라 달라지는 것이 아니라, 딱 고정된다는 것이다. 만약 model에 action과 state를 넣었을 때 나오는 next_state와 reward가 막 달라진다면(or stochastic한 environment라면), 한정된 trajectory를 가지고 학습해야 하는 model 입장에서는 유의미한 정보를 가지기도 힘들 것이다.
그리고 마지막으로 (f)에서 Q-planning(search control + planning update)을 여러 차례 수행한다. 이때 search control 과정은 기존에 방문했던 state와 그때의 action을 random하게 sampling하는 것이고, planning update는 샘플링된 state와 action에 기반해서 next_state와 reward를 구해서 이를 바탕으로 Q value function을 update하는 과정을 나타낸다. 이 과정이 단순히 한두 차례만 수행되면, 전체 Q value function을 개선하는데 있어서 큰 의미가 없겠지만, 이 과정이 전체 episode에 걸쳐서 여러번 반복적으로 수행된다면, 그만큼 optimal한 policy를 빠르게 찾을 수 있을것이다. 마치 사람이 상상속으로 학습하고 실제에서 좋은 성과를 나타내는 것처럼 말이다.
참고로 어떤 강의를 보면서 experience replay라는 개념을 배운적이 있는데, 개인적으로 이게 Dyna-Q 알고리즘의 planning과 매우 유사하다는 생각을 가진 적이 있었다. 그래서 찾다보니까 stackoverflow에 experience replay의 개념과 Dyna-Q 알고리즘의 planning간의 개념적 차이에 관해서 답변이 달려있는게 있어 짧게 글을 달아본다.
Q. algorithm의 planning 부분을 살펴보면, Dyna-agent는 agent가 사전에 경험했던 것들중에서 n개의 state-action pair \((s,a)\)를 random하게 sampling하고, 이를 environment의 model에 넣어줘서 sampling된 next_state \(s'\)과 reward \(r\)를 이용해서 Q-learning update를 수행한다. sutton 책에서는 Dyna-Q에서는 이 과정을 experience replay의 한 형태라고 소개하지 않고, 책의 마지막 부분에 잠깐 소개되고 있는데, 이 두개의 차이를 잘 찾지 못하겠다. 과연 Tabular Dyna-Q를 experience replay의 한 형태라고 봐도 좋을까?
A. 두 개의 개념이 비슷한 형태와 결과를 띄나, 구현상의 차이를 가지고 있음. Dyna-Q 알고리즘은 tabular 형태로 value function을 가지고 있으면서 사전에 deterministic environment라는 전제를 가지고 있으나, experience replay는 tabular 형태가 아닌 function approximation을 사용했고, deterministic environment가 아닌 nondeterministic environment에서 동작하도록 구현되었음.
'Study > AI' 카테고리의 다른 글
| [RL] The Objective for On-policy Prediction (0) | 2019.11.11 |
|---|---|
| [RL] Estimating value function with supervised learning (0) | 2019.11.06 |
| [RL] Dealing with inaccurate models (0) | 2019.10.08 |
| [RL] Model & Planning (0) | 2019.09.25 |
| [RL] Expected SARSA (0) | 2019.09.18 |
| [RL] Q-learning: Off-policy TD Control (0) | 2019.09.11 |
| [RL] SARSA : GPI with TD (3) | 2019.09.11 |
- Total
- Today
- Yesterday
- windows 8
- Off-policy
- arduino
- 강화학습
- Offline RL
- 파이썬
- Kinect for windows
- 한빛미디어
- Kinect
- SketchFlow
- 딥러닝
- Kinect SDK
- dynamic programming
- End-To-End
- Windows Phone 7
- PowerPoint
- Policy Gradient
- 인공지능
- Expression Blend 4
- Gan
- Distribution
- DepthStream
- processing
- RL
- bias
- reward
- TensorFlow Lite
- Pipeline
- ColorStream
- Variance
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |