
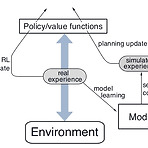
 [RL] Dyna as a formalism for planning
[RL] Dyna as a formalism for planning
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트를 통해서 강화학습 상에서의 Model의 정의에 대해서 소개하고, Model을 통해서 생성한 simulated experience를 바탕으로 model을 update하는 Planning에 대해서 다뤘다. 사실 이런 planning과정과 별개로 실제 environment로부터 얻은 experience를 바탕으로 update하는 것을 Direct RL이라고 표현한다. 이번 포스트에서 소개할 Dyna algorithm (sutton)은 앞에서 소개된 Planning과 Direct RL이 결합된 형태로 되어 있다. 우선 기존의 Q-learning과 마찬가지로 실제 environment로부터 e..
 [RL] Q-learning: Off-policy TD Control
[RL] Q-learning: Off-policy TD Control
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 사실 Q-learning에 대해서는 옛날에 한 포스트를 통해서 다뤘었는데, 다시 정리를 해보고자 한다. 일단 알고리즘은 아래와 같다. 이전 포스트에서 다뤘던 SARSA와 거의 비슷한데, 한가지 다른 부분이 바로 Value function을 update하는 부분이다. 다시 한번 SARSA의 update 부분을 살펴보자. $$ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (\color{red}{R_{t+1}} + \color{red}{\gamma Q(S_{t+1}, A_{t+1})} - Q(S_t, A_t)) $$ 그런데 위의 식은 사실 Dynamic Programm..
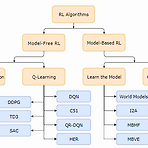 [RL] (Spinning up) Kinds of RL Algorithms
[RL] (Spinning up) Kinds of RL Algorithms
(본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 2: Kinds of RL Algorithms — Spinning Up documentation We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make somethin spinningup.openai.com RL Algorithm의 ..
- Total
- Today
- Yesterday
- PowerPoint
- 딥러닝
- Kinect
- Offline RL
- 강화학습
- windows 8
- Policy Gradient
- Variance
- Distribution
- RL
- Kinect for windows
- Gan
- DepthStream
- arduino
- SketchFlow
- Expression Blend 4
- Windows Phone 7
- Off-policy
- End-To-End
- 파이썬
- reward
- dynamic programming
- bias
- 한빛미디어
- Kinect SDK
- TensorFlow Lite
- ColorStream
- processing
- ai
- Pipeline
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |