
티스토리 뷰
(해당 포스트는 UC Berkeley 에서 진행된 CS285: Deep Reinforcement Learning, Decision Making and Control를 요약한 내용이며, 그림들은 강의 장표에서 발췌한 내용입니다.)
CS 285
GSI Yuqing Du yuqing_du@berkeley.edu Office Hours: Wednesday 10:30-11:30am (BWW 1206)
rail.eecs.berkeley.edu
The goal of reinforcement learning
이 강의 주제는 신경망을 활용한 강화학습을 다루는 것이다. 강화학습의 목표라고 하면 어떤 환경에서 잘 동작하는 policy를 찾는 것인데, Deep RL에서는 이 policy가 신경망으로 표현된다. 그래서 이 policy를 \(\pi\)라고 표현한다면, 신경망의 weight \(\theta\)에 의해서 어떤 policy인지 결정되기 때문에 일반적으로는 \(\pi_{\theta}\)라고 표기한다. 그리고 추가로 policy의 역할은 어떤 state에서 어떤 action이 가장 좋은 것인지를 결정하는 일종의 원칙이기 때문에, 이를 신경망으로 표현한다면 state를 input으로 받고, action을 output으로 내보내는 형태로 생각해볼 수 있다. 결과적으로 어떤 상태일때 특정 행동을 취할 확률로 policy를 나타내기에, 이를 조건부 확률 \(\pi_{\theta}(a \vert s) \)로 표현하게 되고 이렇게 놓고 보면 결국 policy는 특정 state \(s\)에서 취할 수 있는 action \(a\)에 대한 확률 분포라고 설명할 수 있다. 참고로 agent가 전지전능한 신이 아닌 이상 모든 state를 관찰할 수 없기 때문에, 만약 실제 환경에 적용할 것을 가정한다면 partially observable한 state, 다르게 말하면 observation으로 표기해야 하지만 우선 설명 부분에서는 모든 state를 관찰할 수 있는 것을 가정하고 시작한다.
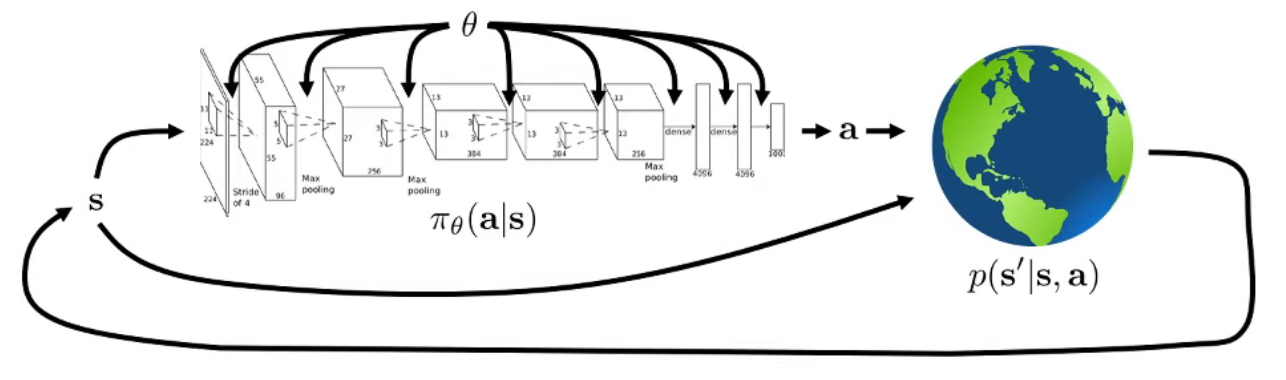
그러면 policy \(\pi_{\theta}(a \vert s)\)에서 어떤 규칙에 따라서 action \(a\)가 나오게 되고, 이 정보는 실제 환경로 들어가게 된다. 이 환경은 보통 dynamics라고 하는 transition probability 특성을 가지게 되고, \(p(s' \vert s, a)\), 즉 현재 state \(s\)에서 특정 action \(a\)를 취했을 때 next state \(s'\)로 바뀔 확률을 가진다. 그러면 이 next state \(s'\)이 다시 신경망의 input으로 들어가는 일종의 feedback loop가 반복된다. 이런 과정을 \(T\)만큼 하게 된다면, 그만큼 에이전트는 그동안 자신이 어떤 state에서 어떤 action을 취했는지에 대한 샘플들을 얻게 될 것이다. 이를 sample trajectory \(\tau\)라고 하고, 여기에는 \(s_1, a_1, \dots, s_T, a_T\)를 포함한다. 그러면 이 trajectory에 대한 분포를 표현하면, 결국 이 분포도 agent의 policy를 구성하는 신경망의 영향을 받게 되므로 결국 \(p_{\theta}(\tau)\)가 될 것이고, 이를 아래와 같은 식으로 정리를 할 수 있게 된다.
$$ p_{\theta}(\tau) = p(s_1) \prod_{t=1}^T \pi_{\theta}(a_t \vert s_t) p( s_{t+1} \vert s_t, a_t) $$
우변의 내용은 복잡해보이지만 앞에서 언급한 환경의 transition probability에 의해 initial state \(s_1\)에 도출될 확률에 policy, 그리고 transition probablity에 의해서 next state로 바뀔 확률을 product sum 형식으로 표기한 것이다. 일단 강의에서는 model-free 방식, 즉 transition probability를 알지 못한다는 상황을 전제로 진행하고 있다. 사실 어떻게보면 실제 환경이 이렇게 transition probability를 모르는 환경이기도 하다. 이제 여기에서 우리가 원하는 것은 당연히 최적의 policy를 찾아야 할 것이고, 이 policy를 결정하는 optimal \(\theta\)인 \(\theta^*\)는 이렇게 trajectory를 통해 얻은 reward의 평균이 가장 큰 \(\theta\)라고 정의할 수 있다.
$$ \theta^* = \arg \max_{\theta} \mathbb{E}_{\tau \sim p_{\theta}(\tau)}\big[ \sum_t r(s_t, a_t) \big] $$
참고로 앞에서 \(T\)라는 notation을 사용했는데, 이는 \(T\)만큼을 하나의 sample trajectory라고 지정한 것이고, 보통 이 trajectory의 크기를 horizon라고 표현한다. 그래서 \(T\)라는 크기를 지정을 해줬기 때문에 이를 finite horizon이라고 하고, 위의 식에서 표현을 조금 다르게 할 수 있다.
$$ \theta^* = \arg \max_{\theta} \sum_{t=1}^T \mathbb{E}_{(s_t, a_t) \sim p_{\theta}(s_t, a_t)} [r(s_t, a_t)] $$
(뭐 어차피 총합의 평균을 구하는 것이나 평균의 총합을 구하는 것이나 동일한 형태이긴 하다. 이걸 수학적으로는 linearity of expectation이라고 정의하고는 있다.)
반면 이 trajectory의 크기가 정해지지 않고, 무한정한 상황인 infinite horizon case도 있다. 이때의 \(\theta^*\)는
$$ \theta^* = \arg \max_{\theta} \mathbb{E}_{(s, a) \sim p_{\theta}(s, a)}[r(s, a)] $$
가 된다. 사실 infinite horizon이라고 하니 trajectory가 정의되지 않은 상태에서 어떻게 구할까 막막할 수 있겠지만 나중에 소개할 value function을 활용하면 finite horizon을 infinite 형태로 바꿔서 볼 수 있다. 일단 finite horizon case를 전제로 진행한다.
Evaluating the objective
그러면 앞의 식처럼 결국 \(\theta^*\)를 찾아야 하고, 이게 결국 policy를 구성하는 신경망의 weight이 되므로, 일반적으로 deep learning에 활용하는 gradient descent같은 기법을 사용해볼 수 있다. 그러면 objective (or loss function)을 정하게 될텐데, 이 \(\theta\)에 관한 식에서는 objective \(J(\theta)\)는 아래와 같이
$$ J(\theta) = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}\big[ \sum_t r(s_t, a_t)\big] $$
그러면 맨처음에 나왔던 \(p_{\theta}(\tau)\)에 들어있는 값인 \(p(s_1)\)이나 \(p( s_{t+1} \vert s_t, a_t) \) 는 사실 우리가 dynamics를 알고 있지 않는 한 구할 수가 없다. 그러면 이 값을 어떻게 구할 수 있을까?
그러면 간단하게 추정할 수 있는 것은 그냥 지금까지 얻은 sample trajectory들의 평균 reward값으로 근사값을 구하는 것이다. 이렇게 sample trajectory를 쭉 펼쳐놓고 본다고 해서 이를 rollout이라고 표현하는 것 같다.
$$ J(\theta) = \mathbb{E}_{r \sim p_{\theta}(\tau)} \big[ \sum_t r(s_t, a_t) \big] \approx \frac{1}{N} \sum_i \sum_t r(s_{i, t}, a_{i, t}) $$
그러면 위 식의 의미는 objective \(J(\theta)\)를 구할 때 \(N\)개만큼의 sample trajectory를 가지고,특정 time step \(t\)에서의 reward값을 모두 더한값의 평균을 구한다는 것이다. 이렇게 하면 총 reward값의 평균값에 대한 unbiased estimate를 얻을 수 있다. 물론 sample trajectory의 크기가 점점 커질수록 estimate값의 정확도는 높아지게 된다. 간단하게 예를 들자면 아래의 그림을 생각해보면 된다. 실제 상황에서 trajectory를 쌓다보면 좋은 trajectory, 나쁜 trajectory가 다 있을텐데, 결국 이 trajectory들의 평균을 구해서 이를 \(J(\theta)\) 에 대한 추정치로 삼겠다는 것이다.

Direct policy differentiation
그런데 결과적으로 이를 얼마나 정확하게 추정하냐가 목적이 아니라 이 값을 가지고 policy를 update하는게 목적이고, 앞에서 언급한 것처럼 gradient descent같은 방법을 사용하기 위해서는 결국 derivative를 구해야 한다. 일단 trajectory의 reward 총합 \( \sum_{t=1}^T r(s_t, a_t)\)를 \(r(\tau)\)라고 하고 \(J(\theta)\)를 정리한다. 참고로 지금의 notation은 discrete variable을 가정한 것인데, continuous variable을 가진 것으로도 확장시켜 볼 수 있다. 물론 continuous variable의 기대값을 구하는 방법은 그냥 확률값을 곱한 것을 쭉 누적시킨 것과 동일하기 때문에 discrete case에 있던 expectation term이 사라진다.
$$ J(\theta) = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}[r(\tau)] = \int p_{\theta}(\tau)r(\tau) d\tau $$
그러면 우리의 목적은 바로 \(J(\theta)\) 의 미분값인 \(\nabla_\theta J(\theta)\)를 구하는 것이고, 이는 아래와 같이 표현할 수 있다.
$$ \nabla_{\theta} J(\theta) = \int \nabla_{\theta} p_{\theta}(\tau)r(\tau)d\tau $$
사실 \(\nabla\)가 나오면서 저 값을 어떻게 계산할까 고민을 할 수 있겠지만 의외로 간단한 trick을 쓰면 모든 식에 대한 gradient를 계산하지 않아도 된다. RL Spinning Up 에서는 이 trick을 log-derivative trick이라고 표현했다. 쉽게 말해서 \(log\)의 미분특성을 사용하는 것인데, 아마 고등학교 수학을 까먹지 않은 사람이라면
$$ \nabla \log (x) = \frac{1}{x} $$
라는 특성을 기억할 것이다. 그러면 우리가 구해야 했던 \(\nabla_{\theta} p_{\theta}(\tau)\)도 원형이 \(\log\)였다고 가정을 해보면 아래와 같은 identity를 정의할 수 있게된다.
$$ p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau) = p_{\theta}(\tau) \frac{\nabla_{\theta}p_{\theta}(\tau)}{p_{\theta}(\tau)} $$
이중 우변의 분모항이 위의 derivative term에 있는 값이고, 추가로 붙는 값들은 자세히 살펴보면 동일한 값임을 알 수 있다. 결국 \(\nabla_\theta J(\theta)\)는 다음과 같이 정의할 수 있다.
$$ \nabla_\theta J(\theta) = \int p_{\theta}(\tau) \nabla_{\theta} \log p_{\theta}(\tau)r(\tau)d\tau = \mathbb{E}_{\tau \sim p_{\theta}(\tau)}[ \nabla_{\theta} \log p_{\theta}(\tau) r(\tau)] $$
\(\log p_{\theta}(\tau)\) 의 \(p_{\theta}(\tau)\)는 사실 맨 처음에 정의했다시피
$$ p_{\theta}(\tau) = p(s_1) \prod_{t=1}^T \pi_{\theta}(a_t \vert s_t) p(s_{t+1} \vert s_t, a_t) $$
이고, 여기에 양변에 \(\log\)를 취하면 위의 식은 다음과 같이 각 term이 더해지는 형태로 바뀐다.
$$ \log p_{\theta}(\tau) = \log p(s_1) + \sum_{t=1}^T \log \pi_{\theta}(a_t \vert s_t) + \log p(s_{t+1} \vert s_t, a_t) $$
그런데 여기에서 이제 원래의 목적대로 이 \(\log\)의 derivative를 취하면 생각보다 간단한 식이 도출된다.
$$ \nabla_{\theta} \big[ \log p(s_1) + \sum_{t=1}^T \log \pi_{\theta} (a_t \vert s_t) + \log p (s_{t+1} \vert s_t, a_t) \big] $$
역시 고등학교 때 미분 수업을 들었다면 partial derivative에 대한 내용을 알고 있을 것이고, 위의 식은 \(\theta\)에 대한 gradient를 구한 것이다. 이 말은 다르게 표현하면 \(\theta\)에 대한 식이 아니면 미분시 다 상수로 판단하고 0으로 만든다. 그런 논리를 펴면 위의 식중 첫번째 \(\log p(s_1)\)과 세번째 term인 \(\log p(s_{t+1} \vert s_t, a_t)\)이 0이 된다. 왜냐? \(\theta\)에 대한 식이 아니기 때문에.. 그러면 최종적으로 식이 아래와 같이 정리된다.
$$ \nabla_{\theta} J(\theta) = \mathbb{E}_{\tau \sim p_{\theta}(\tau)} \Big[ \big( \sum_{t=1}^T \nabla_{\theta} \log \pi_{\theta} (a_t \vert s_t) \big) \big(\sum_{t=1}^T r(s_t, a_t) \big) \Big] $$
이렇게 하니까 처음 전제로 두었던 환경의 trasition probability를 몰라서 어떻게 할 줄 몰랐던 부분을 실제로 policy가 수행되면서 쌓인 trajectory와 reward의 expectation만 가지고도 개선시킬 수 있다는 근거를 찾은 것이다.
Evaluating the policy gradient
잠깐 \(J(\theta\)를 표현하는 과정에서 rollout을 구하면서 추정하는 부분이 있었는데, 이렇게 앞에서 구한것을 여기에도 똑같이 대입해볼 수 있다.
$$ \nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{i=1}^N \big( \sum_{t=1}^T \nabla_{\theta} \log \pi_{\theta}(a_{i, t} \vert s_{i, t}) \big) \big( \sum_{t=1}^T r(s_{i, t}, a_{i, t})\big) $$
그러면 이제 이렇게 미분값을 취한 것을 바탕으로 신경망의 weight \(\theta\)를 update하면 된다.
$$ \theta \leftarrow \theta + \alpha \nabla_{\theta} J(\theta) $$
이 과정을 묘사한게 아래의 그림이 되겠다.

이것이 REINFORCE라는 간단한 policy gradient 알고리즘이고, 1992년 Williams가 Simple statistical gradient-following algorithms for connectionist reinforcement learning 라는 논문을 통해서 처음 소개했다. 참고로 REINFORCE 단어 자체는 Reward Increment = Nonnegative Factor * Offset Reinforcement * Characteristic Eligibility 의 약자에서 파생되었다. 알고리즘으로 표현하면 다음과 같은 과정으로 진행된다.
- \(\pi_{\theta}(a_t \vert s_t)\)를 수행해서 trajectory \(\tau^i\)를 샘플링한다.
- \(\nabla_{\theta} J(\theta) \approx \sum_i ( \sum_t \nabla_{\theta} \log \pi_{\theta} (a_t^i \vert s_t^i)) (\sum_t r(s_t^i, a_t^i)) \)
- \(\theta \leftarrow \theta + \alpha \nabla_{\theta} J(\theta) \)
'Study > AI' 카테고리의 다른 글
| [RL] CS285 - Reducing Variance (0) | 2022.11.09 |
|---|---|
| [RL] CS285 - Understanding Policy Gradients (0) | 2022.11.09 |
| [RL] CS285 - Off-Policy Policy Gradients (0) | 2022.11.09 |
| [RL][Review] Deterministic Policy Gradient Algorithm (3) | 2022.11.03 |
| [RL][Review] Hyperparameter Selection for Offline Reinforcement Learning (0) | 2022.05.19 |
| [RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges (2) | 2022.04.27 |
| [RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl) (0) | 2022.04.19 |
- Total
- Today
- Yesterday
- Variance
- TensorFlow Lite
- 한빛미디어
- ColorStream
- SketchFlow
- 강화학습
- Off-policy
- Expression Blend 4
- Distribution
- Gan
- 인공지능
- PowerPoint
- Policy Gradient
- Kinect for windows
- 딥러닝
- Kinect
- Pipeline
- reward
- dynamic programming
- Offline RL
- Kinect SDK
- processing
- 파이썬
- Windows Phone 7
- End-To-End
- windows 8
- arduino
- RL
- DepthStream
- bias
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |