
 [Kinect with OpenCV] Hand Tracking using Depth Data & Blob
[Kinect with OpenCV] Hand Tracking using Depth Data & Blob
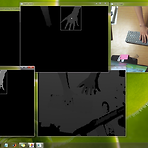
결국 CAMshift는 포기하고 다른 방법으로 가기로 했습니다. 이제 활용할 방법은 전에도 한번 소개해드린 blob Labeling을 기반으로 가기로 했습니다. 사실 저도 영상처리 지식이 많이 부족해서 다른분 도움을 많이 받았습니다. 그래서 Blob마다 LabelIndex가 잡히고 그걸 토대로 오른손만 따라가는 프로그램을 구현해봤습니다. 옆에 콘솔창으로 나오는 것이 바로 오른손의 3D Position입니다. 그리고 test창에 나타나고 있는 것이 원본 파일입니다. 현재 Blob이 두개 나타나고 있지만 DepthHand창에는 오른손에 해당하는 Rectangle만 넘겨줘서 관심영역을 삼고 있습니다. 보다시피 왼손만 나온 경우에는 blob으로는 잡히지만 콘솔창의 좌표로는 아무것도 출력이 되지 않고 있습니다. ..
 [Kinect with OpenCV] C로 만들어보는 뎁스 이미지 호출
[Kinect with OpenCV] C로 만들어보는 뎁스 이미지 호출
사실 지난번에 어떤 분께서 c로 칼라이미지를 구현하는 방법은 나와있는데 뎁스 이미지를 구하는 법도 소개해주면 좋겠다고 하셔서 늦었지만 간단하게 소개해드리고자 합니다. 전체적인 코드 구성은 사실 지난번에 소개해드렸던 컬러 이미지 호출과 거의 유사합니다. 다만 뎁스 이미지는 컬러이미지와 다르게 그냥 컬러 데이터를 뿌려주는 것이 아니라 중간에 depth값을 컬러로 변환시켜주는 과정이 필요합니다. 이 부분은 뒤에서 소개해드리도록 하고 일단 기본적으로 Kinect SDK Developer Toolkit의 예제를 통해서도 depth를 어떻게 빼는지를 확인할 수 있습니다. 그런데 밑에 있는 Depth-D3D와는 무슨 차이인지를 궁금해 하실 분도 계실겁니다. 이 밑에 있는 Depth-D3d와 DepthWithColor..
 [Kinect with OpenCV] CAMShift 적용 (2) Color Segmentation
[Kinect with OpenCV] CAMShift 적용 (2) Color Segmentation
문제가 발생했습니다. 사실 color에 기반한 CAMShift를 사용하면 hue값만 가지고 손의 위치를 잡을 수 있기 때문에 쉽게 구할 수 있습니다.하지만 제가 적용하려고 하는 것은 Depth니까 기본적으로 1 channel일테고, 그러면 거기서 Hue 값을 뽑아내도 hexacon의 특성상 다른 특성들도 구분하지 못하게 됩니다. 또한 히스토그램을 뽑아낸 과정에서 배경인 검정색의 영향이 엄청 크게 작용합니다. 결론적으로 Color 기반의 CAMShift를 그대로 적용하기 힘들다는 것이지요. 그래서 그와중에 생각한 방법중 하나가 Depth에 Color를 segmentation을 해보는게 어떨까였습니다. 그래서 color 손에 대해 Camshift를 수행한 후 해당 Rectangle을 Depth에만 넘겨주면 ..
 [Kinect with OpenCV] CAMShift 적용 (1)
[Kinect with OpenCV] CAMShift 적용 (1)
이제 손을 분리했으니까 손에 대한 추적을 해야됩니다.그런데 보통 추적이라면 어떤 생각을 하시나요? 무작정 따라다니는거? 사실 추적이라는 정의의 조건에는 단순히 따라다는 것에만 그치는 것이 아니라 기존의 타겟을 놓치지않고 잡는다는 것이 포함됩니다. 즉 감시용 CCTV에서도 움직이는 사물에 대해서 추적을 한다는 것은 단순히 탐지만 하는 것이 아니라 끝까지 궤적을 알고 있어야 하는 거지요. 하지만 제가 작성하고 있는 프로그램에는 아직 그런 추적이라는 개념이 적용되지 않았습니다. 그래서 오른손이 나와있다가 왼손이 나오면 왼손이 잡히는 오동작이 발생합니다. 물론 이를 해결하기 위한 방법들이 여러가지가 나오는데 영상처리분야에서 타겟 추적에 가장 많이 쓰이는 기법이 바로 Mean Shift와 CAM shift입니다...
 [Kinect with openCV] cvDistTransform을 활용한 무게 중심점 도출
[Kinect with openCV] cvDistTransform을 활용한 무게 중심점 도출
보통 영상처리를 하면 웹캠을 활용해서 처리하는데 저는 키넥트로 하다보니까 주변에 소스도 없고 참 난감하네요. 아무튼 지난 포스트에서는 Convexhull을 활용해서 가장 외곽점을 이어주는 도형을 보여드렸습니다. 사실 손가락의 갯수는 그걸로 끝납니다. 그냥 Convexhull을 한 점에다가 cvCircle을 해주고 그렇게 해서 생긴 원의 갯수를 활용하면 손가락 몇개인지 구분이 됩니다. 하지만 거기에도 문제는 있습니다. 그때는 손이 항상 위를 가리키고 있을 때니까 일정하게 정해진 갯수만 빼주면 되지만 만약 손이 옆에서 들어온다던가 위에서 나오면 원의 갯수가 꼭 손가락의 갯수만큼 생긴다는 걸 보장할 수 없습니다. 물론 그에 따른 보정코드도 필요할 것이고요. 그리고 제가 못하는 건지는 모르겠는데 위에서 Conv..
 [Kinect with openCV] ConvexHull
[Kinect with openCV] ConvexHull
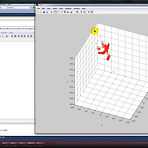
지난번까지 손의 궤적을 추적해서 매트랩으로 도식화하는데까지 보여드렸습니다. 그런데 사실 문제가 조금 있습니다. 사실 제가 구한 중심점은 실제 중심점이 아니라 ROI를 토대로 만든 가상의 중심점입니다. 그래서 사실 손의 중심이 아니라 팔의 중심이라고 하는게 맞겠지요. 그래서 다른 Tracking 기법을 적용하기가 참 힘듭니다. 그만큼 참조해야할 범위가 넓고 만약 다른손이 중간에 끼어들면 ROI는 다른게 잡혀버리기 때문이지요. 결론적으로는 손이라는 범위를 팔에서 축소시킬 필요가 있습니다. 물론 그 방법에는 다양한 방법이 있고 이와 관련된 논문이 많이 나와있습니다만 가장 많이 사용하고 보편적으로 사용하는게 바로 ConvexHull이 아닐까 생각합니다. 사실 제가 연구실에서 세운 목표는 키넥트의 DepthMap..
 [Kinect with OpenCV] NuiTransformDepthImageToSkeleton 을 활용한 손의 실제점 유추(수정본)
[Kinect with OpenCV] NuiTransformDepthImageToSkeleton 을 활용한 손의 실제점 유추(수정본)
생각해보니까 이전에 구했던 좌표점이 잘 못 구해진 값이었습니다. NuiTransformDepthImageToSkeleton()의 인자는 pixelx와 pixely값, 그리고 실제의 depth값이 들어갑니다. 그걸 구하려면 해당 pixel에서의 depth를 구해야 됬었는데 저도 코드에 대한 이해가 부족해서 그냥 넣으면 되겠지 하고 넣었습니다. 그래서 지난번 동영상에서는 z값이 0.105에서 변하지 않았습니다. 그걸 수정하기 위해서 원의 중심점을 구한후 전역변수로 선언한 CvPoint에 넣어서 depthStream을 읽어올때 조건문을 삽입하면됩니다. 이때 조건은 픽셀을 읽어올때의 포인트가 CvPoint랑 같게 하면 되겠지요. 어차피 한 픽셀에 depthStream이 담겨져 있을 것이고 그안에 depthVal..
 [OpenCV with Kinect] NuiTransformDepthImageToSkeleton을 사용한 좌표 변환
[OpenCV with Kinect] NuiTransformDepthImageToSkeleton을 사용한 좌표 변환
아.. 1주일동안 삽질하던게 함수하나로 이렇게 해결이 되어 버리네요.사실 제가 구하고자 했던 것이 이미지상의 손의 위치를 실제 키넥트와의 거리를 측정함으로써 계산하는 것이었습니다. 그런데 아무리 찾아도 내용이 안나오니까 어떻게 마련한 대안이 예제에 포함되어 있는 Depth-D3D 입니다. 보다시피 각 픽셀에 대한 위치가 3D로 나오기 때문에 저는 이 값을 취할 수 있을 줄 알았습니다. 그런데 확인해보니까 이렇게 3D로 매핑해주는 부분이 geometry Shader에서 처리하는 것이더군요. 결론적으로 기존에 만든 코드랑은 완전 별개라는 겁니다. 아.. 생각하다하다 msdn을 살펴보자 해서 찾은 함수가 바로 NuiTransformDepthImageToSkeleton 이라는 함수입니다.사실 제가 헷갈렸던 건 ..
 [OpenCV] ROI의 중심에 Text 입히기
[OpenCV] ROI의 중심에 Text 입히기
지난 포스트까지 손의 ROI를 뽑아서 손을 따라디니게끔 했습니다. 여기다가 손의 위치를 실시간으로 알기 위해서 픽셀데이터를 출력하게 했습니다. 보시면 x, y값이 나오는데 실제 값이 아니라 화면상의 픽셀값입니다. 물론 해당영역 내에서만 움직인다고 가정하면 저걸로도 충분한 위치를 뽑을 수 있겠지요. 참고로 Unity3D에서는 camera 의 viewpoint를 world상에 투영시켜주는 함수가 있었는데 그런게 있었으면 좋겠네요.동작 영상입니다.

 [OpenCV] Labeling 후의 손 이미지에 대한 관심영역(ROI) 설정
[OpenCV] Labeling 후의 손 이미지에 대한 관심영역(ROI) 설정
지난 번에 Labeling을 시도했었고 그 결과 움직이는 손에 따라서 사각형을 그리는 작업까지 했었습니다. 하지만 그건 단순하게 움직이는 물체를 감지하고 그 영역에 대한 사각형을 그리는 것이지 프로그램 자체에서는 그게 손인지 뭔지를 정확히 알 수 없습니다. 우선 지금까지 쭉 진행해온 것에 따르면 그 이미지에서 손만을 따오기 위해서 해당 사각형 부분을 관심영역(Region Of Interest)로 지정해줘야 합니다. 물론 이를 위해서 필요한 함수는 cvSetImageROI() 정도가 될겁니다. 그래야 손이라는 영역만 따오고 그 안에서 ConvexHull을 수행할 수 있겠지요. 그 결과입니다. 여기서 우측에 나와있는 창이 바로 손만을 따서 뽑아낸 이미지입니다. 해당 이미지의 convexHull을 계산한 후에..
 [OpenCV] Labeling을 통한 손 추적
[OpenCV] Labeling을 통한 손 추적
저번 포스트에서 ConvexHull을 사용한 방법을 보여드렸는데 실제로 키넥트에서 적용시켜보니까 영 이상한 점끼리 이어주는 한계가 발생했습니다. 그래서 다음과 같은 방법을 통해서 손의 이미지를 뽑아내기로 했습니다. Labeling을 통한 손 추적 -> Labeling 내부에서 ConvexHull 수행 -> convexityDefects 계산 우선은 가장 흔하게 공개되어 있는 마틴님 자료를 이용해서 Labeling을 시도했습니다. 하다보니까 조금씩 진전이 생기는 것 같네요. 물론 갈길이 멀긴 하지만요..
 [OpenCV] Laplacian 함수
[OpenCV] Laplacian 함수
계속적으로 외곽선에 대한 정리를 해보고 있습니다. 이전에 다뤘던 sobel이나 scharr 필터 같은 경우에는 미분 차수를 어떻게 하느냐에 따라서 결과값의 변화가 나타나는 것을 알 수 있었습니다. 그런데 Marr 라는 사람이 이런 방법 외에도 영상처리에 Laplacian을 적용할 수 있지 않을까 해서 1982년에 Vision이라는 책에 그 내용을 정리합니다. 보통 함수는 다음과 같이 구성됩니다.보다시피 2차 미분항들의 합으로 구성되어 있습니다. 이미지의 가로와 세로에 대한 그레디언트를 2차 미분한 값인 거지요. 사실 보면 거의 소벨 함수에서 xorder와 yorder를 2로 한 값과 유사할 거라고 여겨집니다. 실제로 내부를 들여다보면 다음과 같이 구현되어 있습니다. 중간에 Sobel에 관해서 접근하는 항..
- Total
- Today
- Yesterday
- Pipeline
- Gan
- Kinect SDK
- dynamic programming
- PowerPoint
- ColorStream
- Windows Phone 7
- bias
- windows 8
- arduino
- Off-policy
- Kinect for windows
- 딥러닝
- RL
- DepthStream
- Policy Gradient
- processing
- SketchFlow
- ai
- 강화학습
- 한빛미디어
- Expression Blend 4
- Offline RL
- End-To-End
- 파이썬
- TensorFlow Lite
- Kinect
- Distribution
- Variance
- reward
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |