
 [RL] CS285 - Understanding Policy Gradients
[RL] CS285 - Understanding Policy Gradients
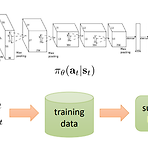
(해당 포스트는 UC Berkeley 에서 진행된 CS285: Deep Reinforcement Learning, Decision Making and Control를 요약한 내용이며, 그림들은 강의 장표에서 발췌한 내용입니다.) CS 285 GSI Yuqing Du yuqing_du@berkeley.edu Office Hours: Wednesday 10:30-11:30am (BWW 1206) rail.eecs.berkeley.edu Comparison to maximum likelihood 이전 포스트의 마지막에 다뤘던 식이 아래와 같다. $$ \nabla_{\theta}J(\theta) \approx \frac{1}{N} \sum_{i=1}^N \big( \sum_{t=1}^T \nabla_{\thet..
Study/AI
2022. 11. 9. 23:26
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- 강화학습
- Kinect SDK
- End-To-End
- windows 8
- Off-policy
- Kinect for windows
- 파이썬
- 딥러닝
- bias
- ai
- Gan
- Policy Gradient
- DepthStream
- Windows Phone 7
- Variance
- SketchFlow
- Kinect
- Offline RL
- RL
- 한빛미디어
- processing
- arduino
- reward
- PowerPoint
- Expression Blend 4
- TensorFlow Lite
- Distribution
- Pipeline
- ColorStream
- dynamic programming
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
글 보관함