
 [RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
[RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
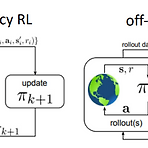
(본문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Offline Reinforcement Learning from Algorithms to Practical Challenges - Kumar et al, NeurIPS 2020 Tutorial (사이트, 실습코드) 원래 거진 3시간짜리 tutorial이기 때문에 정리하는데 시간이 걸릴듯 하다. 그래도 전반적인 Offline RL의 문제와 이론에 대해서 잘 설명되어 있어서 차근차근 설명해보고자 한다. 기본적인 RL 내용도 포함되어 있어, Offline RL 부분만 뽑아서 정리한다. Can we develop data-driven RL methods? 보통 강화학습이라고 하면 다음과 같은 환경을 가정하고 진행한다. 일반적으로는 어떤 환경이 주..
 [RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl)
[RL][Review] Offline RL without Off-Policy Evaluation (onestep-rl)
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Offline RL without Off-Policy Evaluation - Brandfonbrener et al, NeurIPS 2021 (논문, 코드) 요약 이전에 수행된 대부분의 Offline RL에서는 off-policy evaluation과 관련된 반복적인 Actor-critic 기법을 활용했다. 이 논문에서는 behavior policy의 on-policy Q estimate를 사용해서 제한된/정규화된 policy improvement를 단순히 한번만 수행해도 잘 동작하는 것을 확인했다.이 one-step baseline이 이전에 발표되었던 논문에 비하면 눈에 띌만큼 간단하면서도 hyperparameter에 대해서 robust한..
- Total
- Today
- Yesterday
- Pipeline
- Kinect for windows
- Expression Blend 4
- 딥러닝
- Kinect
- processing
- Policy Gradient
- 한빛미디어
- ColorStream
- End-To-End
- bias
- arduino
- ai
- 강화학습
- Offline RL
- SketchFlow
- TensorFlow Lite
- Gan
- Distribution
- Kinect SDK
- Off-policy
- 파이썬
- dynamic programming
- Variance
- PowerPoint
- DepthStream
- windows 8
- reward
- RL
- Windows Phone 7
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |