
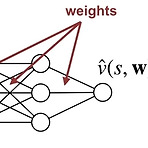
 [RL] Estimating value function with supervised learning
[RL] Estimating value function with supervised learning
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트까지 다룬 알고리즘들은 기본적으로 state/action에 따른 value가 table 형식으로 정의된 tabular value function을 사용했다. 이런 케이스 value function을 정의하기는 쉽지만, 일반화(generalization)을 하기가 어렵다. 예를 들어서 action이나 state가 table처럼 구분할 수 있는 discrete한 값이 아니라 continuous한 값을 가진 경우라면, 위와 같은 tabular value function을 사용하기 어렵다. 또한 state space나 action space의 scale이 ..
 [RL] Monte Carlo for Control
[RL] Monte Carlo for Control
(해당 포스트는 Coursera의 Sample-based Learning Method의 강의 요약본입니다) 일단 State Value Function을 이용한 Monte Carlo Method는 다음과 같이 정의가 된다. $$ V_\pi(s) \doteq \mathbb{E}_{\pi}[G_t | S_t = s] $$ 사실 State Value Function와 State-Action Value Function의 관계는 다음과 같이 정의되어 있기 때문에, $$ V_{*}(s) = \max_{a} Q_{*}(s,a) $$ 이를 활용해보면 다음과 같은 식도 구할 수 있다. $$ q_{\pi}(s, a) \doteq \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a] $$ 결국 위 식의 의..
 [RL] Flexibility of the Policy Iteration Framework
[RL] Flexibility of the Policy Iteration Framework
(해당 포스트는 Coursera의 Fundamentals of Reinforcement Learning의 강의 요약본입니다) Policy Iteration은 Policy Evaluation과 Policy Improvement를 반복하면서 현재의 policy \(\pi\)를 최대한 optimal policy \(\pi_*\)에 가깝게 update하는 방법을 말한다. 아마 Sutton책에서는 다음과 같은 그림으로 도식화를 해놨을 것이다. 아니면 이런 그림도 같이 보았을 것이다. 현재의 policy \(\pi\)와 초기의 value function \(v\)가 있으면, 처음에는 \(\pi\)에 따라 action을 취하고 이에 맞게 value function을 update하게 된다 (\(v=v_{\pi}\)) ..
- Total
- Today
- Yesterday
- 딥러닝
- TensorFlow Lite
- Expression Blend 4
- windows 8
- DepthStream
- Distribution
- Kinect
- Gan
- arduino
- Policy Gradient
- reward
- processing
- PowerPoint
- Kinect SDK
- 인공지능
- Offline RL
- Kinect for windows
- 파이썬
- 강화학습
- Off-policy
- ColorStream
- RL
- bias
- SketchFlow
- dynamic programming
- End-To-End
- Windows Phone 7
- Pipeline
- Variance
- 한빛미디어
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |