
 [RL] Dealing with inaccurate models
[RL] Dealing with inaccurate models
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트들을 통해서 얘기한 내용은 결국 model을 활용해서 planning을 할 수 있어서 sampling efficiency도 높이고, 효율적으로 policy를 학습할 수 있다고 했었다. 여기서 던질 수 있는 질문은 "그럼 정확하지 않은(inaccurate) model로 planning 등을 수행하면 policy를 improve할 수 있을까?" 이다. 예를 들어서 앞에서 다뤘던 maze example 상에서도 policy를 improve시키기 위해서는 가능한한 많은 state와 action을 취해서 얻은 value function이 있어야 하는데, 아무래도 exploration도 하고 중간..
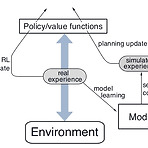 [RL] Dyna as a formalism for planning
[RL] Dyna as a formalism for planning
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트를 통해서 강화학습 상에서의 Model의 정의에 대해서 소개하고, Model을 통해서 생성한 simulated experience를 바탕으로 model을 update하는 Planning에 대해서 다뤘다. 사실 이런 planning과정과 별개로 실제 environment로부터 얻은 experience를 바탕으로 update하는 것을 Direct RL이라고 표현한다. 이번 포스트에서 소개할 Dyna algorithm (sutton)은 앞에서 소개된 Planning과 Direct RL이 결합된 형태로 되어 있다. 우선 기존의 Q-learning과 마찬가지로 실제 environment로부터 e..
- Total
- Today
- Yesterday
- Kinect for windows
- 강화학습
- bias
- SketchFlow
- processing
- 한빛미디어
- 딥러닝
- Distribution
- Kinect SDK
- windows 8
- 파이썬
- PowerPoint
- TensorFlow Lite
- Windows Phone 7
- Off-policy
- Policy Gradient
- ColorStream
- Offline RL
- End-To-End
- RL
- Pipeline
- Expression Blend 4
- ai
- dynamic programming
- DepthStream
- Kinect
- reward
- arduino
- Variance
- Gan
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |