
 [RL] Policy Gradient Algorithms
[RL] Policy Gradient Algorithms
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Policy Gradient Algorithms Abstract: In this post, we are going to look deep into policy gradient, why it works, and many new policy gradient algorithms proposed in recent years: vanilla policy gradient, actor-critic, off-policy actor-critic, A3C, A2C, DPG, DDPG, D4PG, MADDPG, TRPO, lilianweng.github.io Policy Gradient 강화학습의 목적은 o..
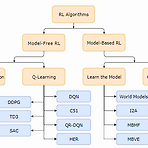 [RL] (Spinning up) Kinds of RL Algorithms
[RL] (Spinning up) Kinds of RL Algorithms
(본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 2: Kinds of RL Algorithms — Spinning Up documentation We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make somethin spinningup.openai.com RL Algorithm의 ..
- Total
- Today
- Yesterday
- bias
- 한빛미디어
- Pipeline
- Gan
- Kinect SDK
- Off-policy
- TensorFlow Lite
- Offline RL
- Distribution
- Expression Blend 4
- SketchFlow
- PowerPoint
- ColorStream
- End-To-End
- Windows Phone 7
- processing
- 강화학습
- DepthStream
- 딥러닝
- ai
- windows 8
- Kinect for windows
- dynamic programming
- RL
- Policy Gradient
- 파이썬
- reward
- Kinect
- arduino
- Variance
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |