
티스토리 뷰
[ML][TIP] Logistic Regression에서의 coefficient를 통한 Feature importance 확인
생각많은 소심남 2021. 4. 14. 17:52요새 듣고 있는 강의 중 하나가 MIT에서 강의하는 "Machine Learning for Healthcare"라는 것인데, 이 강의에서는 다양한 의학데이터(텍스트, 영상 등)을 활용해서 머신러닝/딥러닝 모델을 만드는 것을 다루고 있다. 단순히 모델을 만드는 코딩 스킬보다도 의학 데이터에 내재된 어려움과 이를 해결하기 위한 전처리 기법, 생각해볼만한 통계적 기법 등을 다루고 있어서, 재미있게 듣고 있다. 사실 의학쪽으로 domain expert가 아닌 이상에야 해당 데이터를 다룰 일은 없겠지만, 내가 잘 알지 못하는 분야에서 어떻게 활용되는지를 배우고 나면, 또다른 새로운 분야에 접목시킬 때는 어떻게 고민해봐야 할지 감이 올 것 같아서 듣는 이유가 있다.
Machine Learning for Healthcare
An introduction to machine learning for healthcare, ranging from theoretical considerations to understanding human consequences of deploying technology in the clinic, through hands-on Python projects using real healthcare data.
www.edx.org
아무튼 여기서 다루는 과제 중에는 MIMIC-II (Multiparameter Intelligent Monitoring in Intensive Care)라고 하는 의학 데이터 베이스를 활용해서 모델을 만드는 작업이 있다. 그 중에는 텍스트로 된 의학 데이터를 분석해서 환자의 생존 여부를 예측하는 모델을 만드는 것이 있었다. 그리고 해당 모델에서 사망 예측에 주요 영향을 끼친 Top-5 keyword도 뽑아내는 과정이 포함되어 있다. 참고로 데이터는 이런식으로 되어 있다.

이 중 우리가 관심있는 column은 chartext와 mort_hosp이다. (여기서 train,test,valid column은 단순히 데이터 구분을 위한 column이고 나머지는 관심이 없거나 학습에 영향이 없는 변수들이다)
다들 알겠지만 텍스트 데이터는 모델에 바로 넣을 수 없기 때문에 이를 숫자로 변형하는 과정이 필요하다. 가장 많이 쓰는 것이 scikit-learn에서 제공하는 TfidfVectorizer나 CountVectorizer일텐데, 우선 간단한 모델을 만드는 것은 다음과 같이 수행해봤다.
from sklearn.feature_extraction.text import CountVectorizer
train = note_df[note_df['train'] == 1]
val = note_df[note_df['valid'] == 1]
test = note_df[note_df['test'] == 1]
X_train = train['chartext']
y_train = train['mort_hosp']
X_val = val['chartext']
y_val = val['mort_hosp']
X_test = test['chartext']
y_test = test['mort_hosp']
vectorizer = CountVectorizer(max_features = 5000)
X_train = vectorizer.fit_transform(X_train.values)
X_val = vectorizer.transform(X_val.values)
X_test = vectorizer.transform(X_test.values)참고로 CountVectorizer는 지정된 max_features의 값에 맞춰서 keyword의 Count값을 계산해주는 것이다. 유의할 것은 해당 vectorizer의 형태를 만드는데는 training dataset만 쓰고, 나머지 validation/test dataset은 만들어진 vectorizer를 바탕으로 변형을 해줘야 한다.
그리고 이렇게 하면 변형된 데이터들은 numpy array 형태로 변형된다. 그럼 이 데이터를 가지고 역시 scikit-learn에서 제공하는 LogisticRegression을 수행해본다. 여기서도 참고할 부분이 LogisticRegression은 개념이 간단하지만, 함수 정의 문서를 살펴보면 성능을 좌우하는 hyperparameter들이 많이 있고, 이 값에 따라서 성능이 많이 바뀐다. 여기서는 Overfitting을 방지하기 위한 hyperparameter (C, penalty)에 대해서 탐색하고 이상적인 hyperparameter를 찾고자 했다.
from sklearn.metrics import accuracy_score
C = [0.1,0.25,1]
penalty = ['l1','l2']
for c in C:
for p in penalty:
logreg = LogisticRegression(C=c, penalty=p, solver='liblinear', max_iter=2000)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_val)
acc_score = accuracy_score(y_val, y_pred)
print('C:{}, penalty:{}, accuracy: {}'.format(c, p, acc_score))이렇게 하면 각 hyperparameter 조합별 accuracy가 쭉 출력된다. 이 모델의 경우, C=0.1, penalty='l1'일때의 accuracy가 가장 높았다.
그러면 이를 바탕으로 AUROC (Area Under Receiver Operating Characteristic)을 측정할 수 있다. 물론 단순 classification이야 앞에서 활용한 accuracy만 측정해도 되지만, 해당 측정치 이외에 false positive rate의 영향도 고려해야 한다면 ROC를 측정해야 하고, 이 ROC 곡선 아래의 영역을 계산한 것이 AUROC이다. 이 때 ROC 곡선의 x축은 False positive Rate, y축은 True positive rate이 되는데, 보통은 ROC가 1로 빨리 올라가는 곡선이 이상적인 곡선이고, 이 말은 AUROC가 크면 클수록 좋다는 것을 의미한다. scikit-learn에서는 roc_auc_score라는 함수를 통해서 쉽게 구할 수 있다.
from sklearn.metrics import roc_auc_score
logreg = LogisticRegression(penalty='l1', C=0.1, solver='liblinear', max_iter=2000)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
acc_score = accuracy_score(y_test, y_pred)
auc = roc_auc_score(y_test, logreg.predict_proba(X_test)[:, 1])
print(acc_score, auc)참고로 위와 같은 roc_auc_score를 쓰는 것은 모델이 binary classification을 수행할 때의 방법이다. 만약 classification label이 다른 경우에는 해당 함수의 인자를 조절해서 다르게 계산해야 한다.
이제 여기서 내가 조금 헷갈린 부분이다.
사실 우리 모델에 맞는 이상적인 hyperparameter도 찾았는데, 보통 이 모델의 interpretability를 위해서는 어떤 keyword도 예측에 긍정적이 영향을 미치고 부정적인 영향을 미쳤는지를 보여줘야 한다. 당연한 이야기이겠지만, 우리가 만든 모델은 Logistic Regression Model이고, 우리가 학습한 feature는 앞에서 지정한 CountVectorizer가 가지고 있는 vocabular list, 그리고 output은 mort_hosp이다. 그러면 각 feature별로 이와 연결된 coefficient가 있을 것이고, 이 값이 높으면 높을 수록 예측에 영향을 준다는 것을 의미한다. 물론 coefficient가 양수이면 mort_hosp가 1이라고 예측하는데 영향을 주는 요소이고, 음수이면 0이라고 예측하는데 영향을 주는 요소이다.
사실 처음에는 이렇게 DataFrame을 만들어서 확인하고자 했다.
keywords = pd.DataFrame(logreg.coef_, columns=list(vectorizer.vocabular_.keys()))
keywords.T.sort_values(by=0, ascending=False)이에 대한 결과는 아래와 같다.
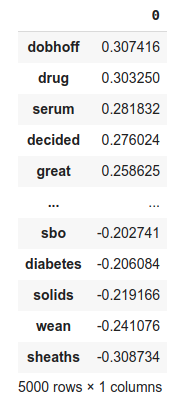
나중에 안 것인데, 저렇게 vectorizer가 가지고 있는 keyword를 직접 뽑아서 정리하는 것은 애초에 정리가 되지 않은 keyword를 그대로 출력하는 것이기 때문에, 의미없는 column이 매핑되는 결과가 발생한다. (그래서 dobhoff라는 keyword는 사실 의미없는 데이터인데, 여기서는 사망에 큰 영향을 주는 keyword로 출력되고 있다)
위의 코드를 바르게 고치면 이렇게 된다.
keywords = pd.DataFrame(logreg.coef_, columns=vectorizer.get_feature_names())
keywords.T.sort_values(by=0, ascending=False)
이렇게 뽑으면 단어들이 여러개 나오는데, esld 는 End-Stage Liver Disease의 약자로 말기 간 환자를 말하고, corneal은 각막, dnr은 역시 Do Not Resuscitate (회생 불가)의 약자이다. 딱 단어만 들어도 사망과 관련된 단어임을 알 수 있다. (아마 각막 관련 이야기는 죽으면 각막 기증과 같은 절차를 밟으면서 많이 나오는 단어가 아닐까 생각된다.)
아무튼 위와 같이 vectorizer로부터 keyword를 뽑아낼 때, 적절한 함수를 사용해야 원하는 결과를 도출할 수 있다. 이런 식으로 coefficient기반으로 어떤 keyword가 예측에 영향을 주는지를 판별할 수 있는 것을 확인할 수 있었다.
'Study > AI' 카테고리의 다른 글
| [RL] MuJoCo 2.1.0 무료 공개 (5) | 2021.10.21 |
|---|---|
| [DL] Figure KL Divergence (0) | 2021.09.13 |
| [DL][Embedded] Semantic Segmentation on Coral Dev board (0) | 2021.08.20 |
| [ML] Theory of the perceptron (2) | 2021.02.02 |
| [RL] Windows 10에서 mujoco_py 구동 (12) | 2021.01.26 |
| [RL] Feature Construction for Linear Methods (0) | 2021.01.22 |
| [DS] Distributions (0) | 2020.06.02 |
- Total
- Today
- Yesterday
- Off-policy
- Offline RL
- 강화학습
- arduino
- 인공지능
- Kinect SDK
- Kinect for windows
- RL
- processing
- TensorFlow Lite
- Policy Gradient
- End-To-End
- 파이썬
- Expression Blend 4
- DepthStream
- reward
- Pipeline
- SketchFlow
- Windows Phone 7
- Gan
- Distribution
- Variance
- windows 8
- bias
- ColorStream
- PowerPoint
- 딥러닝
- 한빛미디어
- dynamic programming
- Kinect
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |