
티스토리 뷰
How to get superior text processing in Python with Pynini
기본적인 텍스트 처리를 하는데 있어서 정규표현식을 쓰지 않을 수 없습니다. 하지만 몇몇개의 아주 간단한 것들을 포함한 많은 문제들은 유한 상태 변환기(Finite State Transducer 또는 FST)를 사용해서 더 나은 성능을 얻을 수 있습니다. FST는 간단하게 말하면 일종의 상태 기계인데, 이름에서 의미하는 것처럼 유한 개의 상태를 가지고 있습니다. 아주 엄청나게 복잡한 형태의 정규 표현식이 포함되지 않은 빠른 텍스트 인용부터 간단한 자연 언어 처리까지, 더 나아가 음성인식과 같이 FST로 할 수 있는 모든 것에 대해서 언급하기 전에 상태 기계가 어떤 것인지를 알아보고, 상태 기계를 정규 표현식과 더불어 어떻게 사용할 수 있는지를 확인해보고자 합니다.
껌자판기에서 상태 기계로 가기 까지..
상태 기기는 상태들간의 전이를 수행하는 일종의 소프트웨어 또는 하드웨어를 말합니다. 예를 들어 껌 자판기는 두개의 상태 중 하나를 가진다고 할 수 있습니다.
0. 동전이 들어있지 않다.
1. 동전이 하나 들어있다.
껌 자판기에서는 두가지 전이가 있을 수 있습니다:
A. 동전을 기계에 집어넣는다.
B. 손잡이를 돌려, 맛있는 껌을 손에 넣는다.
그리고, (A) 전이는 기계가 (0) 상태인 동전이 비어있을 때만 가능하고, (B)전이는 기계가 (1)인 동전이 들어있을 때만 가능합니다. 다음 이미지에서 껌 자판기에서의 상태와 전이에 대해서 원과 화살표를 이용해서 설명하고 있습니다.
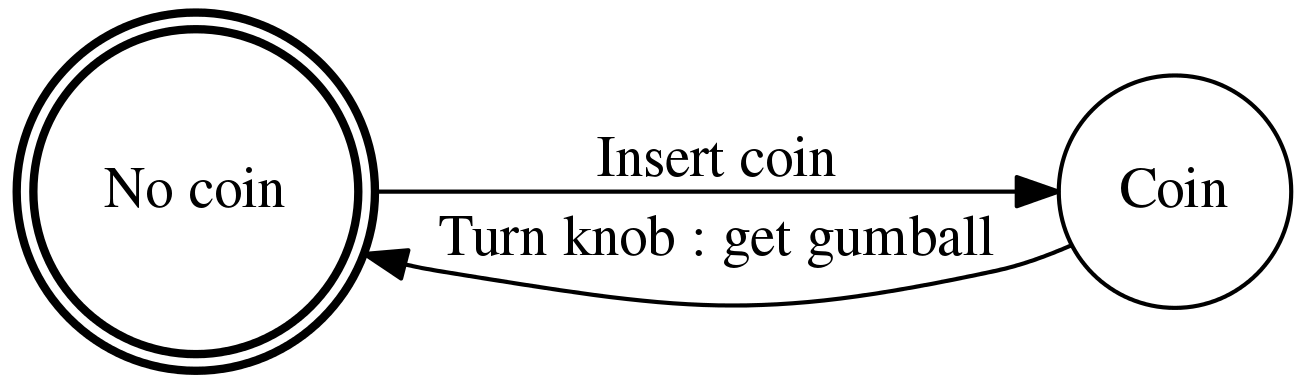
<그림 1. 두개의 상태와 두개의 전이를 가진 상태 기기로 모델링된 껌 자판기 >
상태 기계에서 정규 표현식까지..
같은 의미에서 정규 표현식 확인기도 상태 기계라고 생각할 수 있습니다. /ba+/ 라는 정규 표현식을 고려해보면 이건 ba, baa, baaa 같은 걸 찾을 수 있습니다. 이는 아래와 같은 상태 기계로 표현할 수 있습니다.
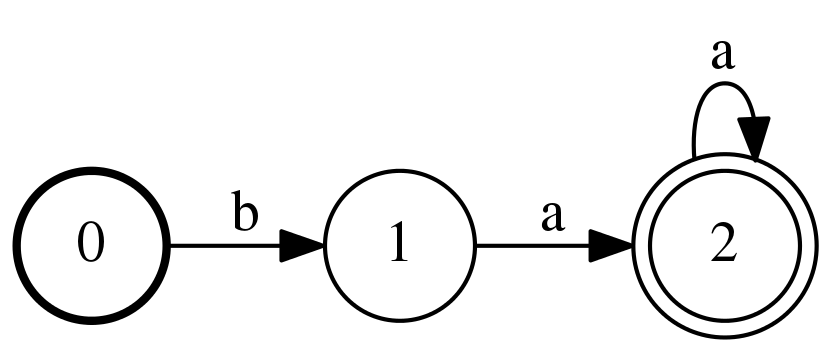
<그림 2. /ba+/정규 표현식을 찾기 위한 상태 기계.
0 상태위 두꺼운 원이 시작 상태이고, 2 상태로 표현된 두개의 원은 종료 상태를 나타낸다.>
우리는 정규표현식이 다음과 같은 상태 기계를 통해서 어떤 경로를 만족했을 때에만 해당 구문이 정규 표현식을 만족했다고 말합니다. 이 경로를 정의하기 위해, 우리는 다음과 같은 특성들을 먼저 정의해야 합니다.
- 적어도 하나의 상태는 시작 상태로 정의되어야 한다.(그림에서는 두꺼운 테두리로 그려진 형태로 표시됨)
- 적어도 하나의 상태는 종료 상태로 정의되어야 한다.(그림에서는 두개의 테두리로 그려진 형태로 표시됨)
- 각 전이는 라벨이 동반되어야 하며, 위에서는 b라는 문자로 표현되어 있다.( 화살표 위에 라벨이 표시됨)
상태 기계를 통과하는 길은 시작 상태에서 시작해 종료 상태로 끝나는 형태로 구성된 일종의 전이 집합체입니다. 전이 라벨을 붙여보면, 형태에 일치하는 문자열을 얻을 수 있습니다. 예를 들어, 만약 문자열이 baa이라면, 다음과 같은 전이를 취할 수 있습니다:
- 상태 0에서 상태 1로 전이되는 라벨 b
- 상태 1에서 상태 2로 전이되는 라벨 a
- 상태 2에서 상태 2로 전이되는 라벨 a
상태 0이 시작 상태이고, 2는 종료 상태이기 때문에, 이 문자열은 정규 표현식에 맞는 형태입니다. 하지만 b와 같은 경우는 종료 상태가 아닌 상태 1로 길이 끝나기 때문에 유효한 길이 아니라고 볼 수 있습니다. 이와 마찬가지로 moo라는 단어 역시 m이나 o로 정의된 전이가 없기 때문에 역시 유효한 길이 아니라고 볼 수 있습니다.
이런 형태의 상태 기계를 유한 상태 수용자(Finite-State Acceptor 또는 FSA)라고 알려져 있는데, 그 이유는 이 상태 기계가 어떤 구문을 수용하거나 거부하는 유한 개의 상태를 가지고 있기 때문입니다. 그리고 모든 정규 표현 엔진은 구문을 판정하는데 있어서 직접적으로나 간접적으로 FSA를 사용하고 있습니다.
정규표현식에서 유한 상태 변환기까지..
유한 상태 변환기(FST)는 FSA의 일반화된 형태이며, 각 전이는 라벨들로 연동되어 있습니다. 이 때의 각 라벨은 입력 문자열과 출력 문자열이라는 두개의 형태를 생성합니다. 결과적으로 변환기 자체는 두 문자열간의 관계를 모델링해주는 역할을 합니다. FSA는 모든 전이가 같은 입력과 출력 라벨을 가지는 특별한 케이스라고 보시면 될거 같습니다.
수십년간의 연구덕분에 FST를 컴파일하고, 조합하며, 최적화하고 찾는 효율적인 알고리즘들이 많이 나와있고, 대부분의 알고리즘들이 음성 인식 분야에 적용되고 있습니다. 여기에서 우리는 FST가 자연 언어들은 인용하고 생성하는데 간단하고 효율적인 도구인지에 대해서 알아보고자 합니다.
응용 1: 문자열 태깅
수많은 문자의 집합체를 가지고 있고, 여기서 괜찮은 치즈의 종류와 관련된 아무 내용을 XML 형식으로 태깅하기를 원한다고 가정합시다. 예를 들어 다음과 같이 문자열이 주어지고,
input_string = "Do you have Camembert or Edam?"괜찮은 치즈의 종류에 대한 리스트를 가지고 있다고 가정했을때
cheeses = ("Boursin", "Camembert", "Cheddar", "Edam", "Gruyere",
"Ilchester", "Jarlsberg", "Red Leicester", "Stilton")우리는 다음의 것을 얻을 수 있습니다.
output_string = "Do you have <cheese>Camembert</cheese> or <cheese>Edam</cheese>"이제 여기서 Python의 re 라이브러리를 사용해서 해당 리스트를 간단하게 정규 표현식으로 컴파일할 수 있습니다.
re_target = re.compile("(" + "|".join(re.escape(ch) for ch in cheeses) + ")")하지만 이에 대한 결과물은 비결정성이라는 좋지않은 특성을 가지고, 이는 비효율적인 매칭을 야기합니다. 결과적으로 re모듈은 (그리고 대다수의 정규 표현 엔진들)은 엄청나게 복잡한 행동을 야기하는 역추적방식으로 동작하게 됩니다.
효율적인 매칭을 위한 FSA vs. 정규 표현식
하지만 구글에서 개발된 오픈소스형 유한 상태 변환 라이브러리중 하나인 Pynini를 사용하면 결정성 FSA를 쉽게 생성할 수 있습니다.
fst_target = pynini.string_map(cheeses)이 함수는 결과로 나올 FSA가 결정적이라고 가정하는 접두어 트리 형식의 관점에서 FSA를 생성합니다.
이제 괄호를 삽입하기 위해서 이런 것들을 어떻게 사용하면 될까요? Python의 re모듈을 사용하면 re.sub를 사용한 문자열 대체법을 포함해서 백레퍼런스와 같은 몇가지 방법들을 고려해볼 수 있습니다. 위에서 얻은 결정적 FSA인 fst_target을 이용할 때, 가장 간단한 방법은 문자열대 문자열간의 재작성되는 관계를 활용해서 대체를 표현하는 FST를 새로 생성하는 것입니다. 다음 예시를 통해서 소개하고자 합니다.
우선 좌변과 우변에 태그를 삽입할 수 있는 변환기를 하나 만듭니다. 예를 들어서 이것을 사용하면 빈 문자열에 태그를 매핑할 수 있습니다.
ltag = pynini.transducer("", "<cheese>")
rtag = pynini.transducer("", "</cheese>")그러고 난 후에 우리가 찾고자 하는 결정적 FSA의 좌변과 우변에 앞에서 얻은 변환기를 추가할 수 있는 대체 변환기를 새로 생성합니다. (아래의 식에서의 +는 FST에서의 추가 연산을 수행하는 연산자입니다.)
substitution = ltag + fst_target + rtag이제 이 변환기는 태그가 삽입된 형태, 그 자체를 나타냅니다. 그런데 언급한 바와 같이 이 변환기를 임의의 문자열에 바로 적용할 수 없습니다. 왜냐하면 변환기는 치즈 이름이 아닌 문자열에 대해서는 찾을 수 없기 때문입니다. 이 작업을 마무리하기 위해서는 맞지않는 문자열에 대해서는 그냥 통과시킬수 있는 FST도 필요합니다. 이때문에 cdrewrite라는 것을 사용합니다. (구문 의존적 재작성"context-dependent rewrite"의 약자로 표현했습니다.)
이 함수는 최소한 4개의 인자를 필요로 하는데 그 종류로는:
1. 대체 변환기
2. 대체를 위한 좌변 구문 (cf. 후행 연산)
3. 대체를 위한 우변 구문 (cf. 선행 연산)
4. 우리가 입력으로부터 찾기를 원하는 알파벳 문자들을 표현한 FSA
이전의 과정을 통해서 이미 1을 만들었고, 구문의 규칙에 대해서 별다른 제한 사항이 없기 때문에 2, 3에 대해서는 빈 문자열을 삽입했습니다. 4에 대해서 생각해보면, null byte('\0')을 제외한 모든 유효 바이트와 몇몇 예약된 문자('[' , '\', ']')들을 사용할 수 있습니다.
chars = ([chr(i) for i in xrange(1, 91)] +
["\[", "\\", "\]"] +
[chr(i) for i in xrange(94, 256)])
sigma_star = pynini.string_map(chars).closure()위의 변화기들을 이용해서 태그를 삽입해주는 변환기를 만들었습니다.
rewrite = pynini.cdrewrite(substitution, "", "", sigma_star)이제 남은 일은 위의 과정을 문자열에 적용해보는 것입니다. 가장 간단한 방법은 임의의 문자열과 재작성된 변환기를 결합하고, 이렇게 만들어진 결과물을 문자열로 변환시키는 것입니다.
output = pynini.compose(input_string, rewrite).stringify()응용 2: 복수의 규칙
다음과 같이 "The current temperature in New York is 25 degrees" 라는 문장을 고려해봅시다. 일반적으로 이런 문장은 다음과 같은 형식으로부터 나왔을 겁니다:
The current temperature in __ is __ degrees이런 형식은 첫번째 공백에는 지역에 대한 이름이 들어갔을때, 그리고 두번째 공간에는 숫자가 들어갔을 때 정상적인 문장이 됩니다. 그런데 뉴욕이 진짜 추워서 온도계가 화씨 1도를 나타냈을 때 어떻게 표현할까요? 이런 식으로 표현되는 것은 원하지 않을 것입니다.
The current temperature in New York is 1 degrees여기서 필요한 것은 주어진 문맥에 대해서 단위를 적절하게 조절할 수 있는 방법이나 규칙인 것입니다. Unicode Consortium에서는 이것과 관련하여 몇가지 가이드라인이 있습니다. 여기에 따르면 우선 해당 문구가 얼마나 다른 언어의 형태를 가지고 있는지 수를 정의하고 어떤 환경에서 그런 문구가 써지는지를 우선적으로 고려해야 합니다. 언어학적 관점으로 봤을때 이런 상세 기술은 때때로 무의미할 수도 있으나, 대부분 보편적으로 사용되고, 새로운 언어에 대해서 지원될 때 유용하게 쓰입니다.
degress에 대해서 다루자면, 기본적으로 여러가지 형태를 띤다고 가정한 상태에서 특정 구문에 대해서는 복수의 규칙을 단수화해야 합니다. degrees나 다른 케이스에서도 확인할 수 있는 것처럼 이건 단지 단어의 마지막에 s 문자를 삽입하는 경우도 있지만 inches와 같이 -ches로 끝나는 단어에 대해서는 문자의 끝을 es으로 매듭짓길 원할 것이고, feet나 pence에 대해서처럼 foot이나 penny와 같이 불규칙적으로 변하는 경우도 있습니다.
Pynini에서 단순성 혹은 특별한 목적을 가진 python 함수들
물론 이런 경우를 다룰수 있는 특별한 목적을 가진 Python 함수도 있지만, 여기서는 Pynini를 이용해서 아주 간단하게 처리하는 방법에 대해서 고려해보고자 합니다. 먼저 일반적인 케이스에 덧붙여서 불규칙적인 케이스도 다룰 수 있는 singular_map 를 정의하는 것부터 시작해봅니다.
singular_map = pynini.union(
pynini.transducer("feet", "foot"),
pynini.transducer("pence", "penny"),
# Any sequence of bytes ending in "ches" strips the "es";
# the last argument -1 is a "weight" that gives this analysis
# a higher priority, if it matches the input.
sigma_star + pynini.transducer("ches", "ch", -1),
# Any sequence of bytes ending in "s" strips the "s".
sigma_star + pynini.transducer("s", ""))그러고 난 후에 이전에 소개한 바와 같이, 단위가 "1"인 케이스에 대해서 단수화를 처리할 수 있는 구문 의존적 재작성 규칙을 정의할 수 있습니다. 그리고 구두법, 여백, 문자열의 끝을 나타내는 특별한 심볼인 "[EOS]"와 같은 전체 어플리케이션의 규칙 rc에 대한 우변 구문을 정의할 수 있습니다.
rc = pynini.union(".", ",", "!", ";", "?", " ", "[EOS]")
singularize = pynini.cdrewrite(singular_Map, " 1 ", rc, sigma_star)이 규칙을 적용하기 위한 일종의 편의 함수도 정의할 수 있습니다.
def singularize(string):
return pynini.shortestpath(
pynini.compose(string.strip(), singularize)).stringify()그리고 아래와 같이 사용할 수 있습니다.
>>> singularize("The current temperature in New York is 1 degrees")
>>> "The current temperature in New York is 1 degree"
>>> singularize("That measures 1 feet")
>>> "That measures 1 foot"
>>> singularize("That measures 1.2 feet")
>>> "That measures 1.2 feet"
>>> singularize("That costs just 1 pence")
>>> "That costs just 1 penny"규칙을 적절하게 바꿈으로써 다른 언어들도 다룰 수 있습니다. 예를 들어 러시어어 같은 경우 더 복잡한 복수화 규칙이 있는데, 이 규칙의 경우에는 단순히 단수냐 복수냐의 차이뿐만 아니라 다양한 규칙이 적용될 수 있는 상태에 대해서도 각각의 다른 형태를 가집니다.
우리는 단지 FST로 할 수 있는 것들에 대해서 아주 일부에 대해서만 다뤄봤습니다. 이것들을 텍스트 마크업하는데 사용하게 되면, 쇠사슬과 같이 서로 묶여있는 여러개의 FST를 하나의 기계로 조합할 수 있고, 이건 정보를 추출하는데 있어서 중요한 기법이 됩니다. 이 기법은 위에서 언급한 바와 같이 언어 형태론을 다루는 수많은 규칙들이 내재되어 있는 언어 합성에 사용될 수 있고, 숫자나 날짜, 시간, 가격에 대한 발음과 같은 비슷한 것들이 하나의 강력하고, 최적화된 FST로 형성됩니다.
FST는 또한 어떤 시퀀스에 대한 확률적 모델을 암호화하는데 사용될 수 있습니다. 음성 인식기는 음성에서 전화기로, 전화기에서 단어로, 단어에서 발성으로 매핑되어 있는, 일종의 WFST들이 연쇄적으로 묶여있는 형태로 구성되어 있습니다. 이때 하나의 모델이 생성된다면, 우리는 shortest-path alogorithm을 사용해서 가장 확률이 높은 결과물을 쉽게 찾을 수 있게 됩니다. 이렇게 되면, 당신이 폰으로 어떤것을 이야기 할 때나, 그걸 다시 들을 때, 실시간으로 문자열이 풀린 형태의 FST들을 볼 수 있을 겁니다.
강찬석
한 전자회사에서 시스템 소프트웨어 엔지니어로 있으면서 통신 관련 소프트웨어를 개발중입니다. 컴퓨터에 관해서 다양하고 광범위한 주제에 관심을 가지고 있으며, 배운 지식을 블로그(http://talkingaboutme.tistory.com)를 통해 공유하는 것을 더 좋아하는 사람입니다.
'Hobby' 카테고리의 다른 글
| 5 things you should be monitoring (0) | 2019.01.29 |
|---|---|
| Question answering with TensorFlow (0) | 2018.03.27 |
| How to build—and grow—a strong design practice (0) | 2018.03.27 |
| Building deep learning neural networks using TensorFlow layers (0) | 2018.03.05 |
| 4 essential skills software architects need to have but often don’t (0) | 2017.03.01 |
- Total
- Today
- Yesterday
- windows 8
- 파이썬
- Kinect SDK
- Kinect
- Gan
- bias
- Windows Phone 7
- Variance
- 한빛미디어
- TensorFlow Lite
- PowerPoint
- Distribution
- Pipeline
- Policy Gradient
- 딥러닝
- dynamic programming
- reward
- arduino
- processing
- Offline RL
- RL
- End-To-End
- ai
- Off-policy
- ColorStream
- Kinect for windows
- SketchFlow
- 강화학습
- Expression Blend 4
- DepthStream
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |