

 [DL] Meta-Learning: Learning to Learn Fast
[DL] Meta-Learning: Learning to Learn Fast
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Meta-Learning: Learning to Learn Fast Meta-learning, also known as “learning to learn”, intends to design models that can learn new skills or adapt to new environments rapidly with a few training examples. There are three common approaches: 1) learn an efficient distance metric (metric-based); lilianweng.github.io "Learning To Lea..
이전에 다뤘던 Q-learning같은 방법들을 보면, 각 state에 대한 expected return들을 일종의 table 형식으로 관리하는 것을 확인할 수 있었다. Bellman Equation을 사용해서 우리는 나름의 각 state에 대한 \(v_{\pi}(s)\) 를 구하거나, 각 state-action pair에 대한 \(q_{\pi}(s, a)\)를 구하고 매 step마다 table을 업데이트하면서 나름의 optimal policy를 찾으려고 노력할 것이다. 여기서 주어진 환경내에서 취할 action을 정의한 policy \(\pi\)에 대한 state value function \(v_{\pi}(s)\) 를 구한다고 해보자. 강화학습의 특성상 우리는 미래에 얻을 수 있는 expected re..
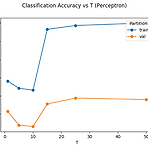 [ML] Averaged Perceptron / Pegasos
[ML] Averaged Perceptron / Pegasos
이전에 강의들을 때는 Perceptron이 그냥 Linear classification을 할때 쓰는 간단한 알고리즘이라고 생각했었는데, 나중에 와서 다시 공부해보니까, weight의 update 주기나 convergence에 대한 고민을 하면서 여러가지 기법들이 더 나온것을 알았다. 마침 하던 과제 중에 sentiment_analysis를 여러가지 perceptron으로 해서 성능 비교하는 내용이 있어 공유해본다. 참고로 Pegasos(Primal Estimated sub-GrAdient SOlver for SVM, Shalev-Shwartz et al, 2011)은 SVM을 사용할 때 gradient descent를 접목시킨 내용인데, 여타 알고리즘에 비해 convergence가 잘 되는 것으로 알고 ..
 [RL] Policy Gradient Algorithms
[RL] Policy Gradient Algorithms
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Policy Gradient Algorithms Abstract: In this post, we are going to look deep into policy gradient, why it works, and many new policy gradient algorithms proposed in recent years: vanilla policy gradient, actor-critic, off-policy actor-critic, A3C, A2C, DPG, DDPG, D4PG, MADDPG, TRPO, lilianweng.github.io Policy Gradient 강화학습의 목적은 o..
이전에 다뤘던 포스트 중에 ANN을 사용해서 Churn prediction을 했던 내용이 있다. 간단히 말해 개인에 대한 정보를 바탕으로 이 사람이 credit이 있는지 없는지 여부를 판단해주는 예제였다. 그때 사용했던 데이터를 보통 데이터 필드가 numerical variable도 있고, categorical variable도 있었다. 물론 categorical variable을 ML이나 Deep Learning에서 다루기 위해서는 뭔가 의미있는 정보로 변화시켜주는 일련의 Encoding 과정이 필요했고, 그 때 기억으로는 Scikit-learn에서 제공하는 LabelEncoder와 OneHotEncoder를 사용해서 데이터를 Binary 처리를 하고, 학습에 반영했다. 아마 이렇게 처리하는 방식이 C..
(OpenAI Spinning Up 글을 개인적으로 정리했습니다. 원본) Extra Material — Spinning Up documentation Docs » Extra Material Edit on GitHub © Copyright 2018, OpenAI. Revision 97c8c342. Built with Sphinx using a theme provided by Read the Docs. spinningup.openai.com 이번 글에서는 finite-horizon undiscounted return 상태에서 다음 식을 증명하고자 한다. $$ \nabla_{\theta} J(\pi_{\theta}) = E_{\tau \sim \pi_{\theta}} \Big[ \sum_{t=0}^{T} \b..
(이 글은 OpenAI Spinning Up의 글을 개인적으로 정리한 내용입니다. 원본) Extra Material — Spinning Up documentation Docs » Extra Material Edit on GitHub © Copyright 2018, OpenAI. Revision 97c8c342. Built with Sphinx using a theme provided by Read the Docs. spinningup.openai.com 이번 글에서는 action이 이전에 얻은 reward에 reinforce되서는 안된다는 것을 증명하고 한다. 먼저 simplest policy gradient에서의 식 중 \(R(\tau)\)를 전개해보면 다음과 같다. $$ \begin{align} \n..
( 본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 3: Intro to Policy Optimization — Spinning Up documentation In this section, we’ll discuss the mathematical foundations of policy optimization algorithms, and connect the material to sample code. We will cover three key results in the theory of policy gradients: In the end, we’ll tie those results together and desc spinningup.openai.com 이번 글에서는..
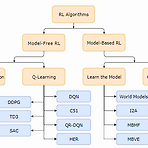 [RL] (Spinning up) Kinds of RL Algorithms
[RL] (Spinning up) Kinds of RL Algorithms
(본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본) Part 2: Kinds of RL Algorithms — Spinning Up documentation We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make somethin spinningup.openai.com RL Algorithm의 ..
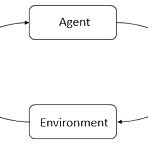 [RL] (Spinning Up) Key concepts in RL
[RL] (Spinning Up) Key concepts in RL
(본 글은 OpenAI Spinning Up 글을 개인적으로 정리한 글입니다. 원본) Part 1: Key Concepts in RL — Spinning Up documentation A state is a complete description of the state of the world. There is no information about the world which is hidden from the state. An observation is a partial description of a state, which may omit information. In deep RL, we almost always represent stat spinningup.openai.com RL을 다루면 가장 많이 나오..
 [ETC] Google Coral Dev Board
[ETC] Google Coral Dev Board
회사 지원을 받아서 미국으로 나와있다. 미국에 나오자마자 살려고 고민했던게 바로 Google에서 출시한 Coral Dev Board였는데, 이렇게 수령했다. 대충 가격은 150정도에 Tax 붙고 배송비까지 적용하니까 180불정도 했던거 같다. 이게 눈에 띄는 이유는 Google에서 만든 NPU인 TPU가 on-board 형식으로 embedded된 것이다. 지금까지 나온 형태는 Chip내에 내장되어 있던가, 아니면 Movidius에서 Neural Computing Stick 처럼 USB를 통해 처리를 지원받는 형식이었는데, 이건 위처럼 보드 타입도 있고, usb-c type으로 연결해 쓰는 타입도 있다. 나름 구글에서는 edge computing, fast ML을 지향하면 출시한 것이긴 한데, 예제좀 돌려..
 [ETC] Atari-wrapper 설치하다 error가 발생하는 경우
[ETC] Atari-wrapper 설치하다 error가 발생하는 경우
Windows 10에서 OpenAI Gym 중 Atari simulator를 설치하다가 다음과 같은 Error가 발생하는 케이스가 있다. Error 내용에도 보다시피 Microsoft Visual C++ 14.0이 설치되어 있지 않아 발생하는 문제이고, 이를 해결하기 위해서는 해당 컴파일러가 있는 위치를 환경변수의 Path로 지정해줘야 한다. 우선 다음 vs_build_tool을 설치한다.(vs 2019 기준) 아마 설치가 되어 있다면 추가 패키지 설치란이 있을텐데, 여기서 Windows 10 SDK (10.0.17134.0)을 설치해준다. 이를 설치하게 되면, C:\C:\Program Files (x86)\Windows Kits\10\bin\10.0.17134.0\x64 에 컴파일러들이 설치가 된다. ..
 [RL] Windows 10에서 OpenAI Gym & Baselines 설치하기
[RL] Windows 10에서 OpenAI Gym & Baselines 설치하기
아마 강화학습용 시뮬레이터와 알고리즘을 검증하는데 가장 많이 사용하는 것이 OpenAI Gym과 OpenAI Baselines 일 것이다. Gym은 원래의 뜻인 체육관이란 뜻에도 담겨있는 것처럼, 강화학습 알고리즘을 테스트해볼 수 있는 다양한 simulation environment가 포함되어 있다. 물론 강화학습을 하는 사람이라면 한번쯤 들어봤을 듯한 Atari나 robot Simulator인 MuJoCo도 들어있다. Baselines는 이와 반대로 Gym 환경 base에서 테스트해볼 수 있는 다양한 알고리즘들이 포함되어 있는 패키지이다. 제일 기초적인 DQN부터 시작해서 조금 발전된 형태인 DDPG, TRPO, PPO같은 알고리즘들도 구현되어 있다. 그래서 본인이 만약 알고리즘에 치중해서 개발하고 있..
이번 글은 cost와 state transition을 알지 못하는 상태에서의 optimal control을 위한 강화학습의 관점을 설명하는 것에서 시작해보고자 한다. 모두들 알다시피 Dynamic Programming을 통해서 optimal solution을 구할 수 있다. 하지만, 현재의 모델이나 cost를 모를 때나, 전체 dynamic program를 수정하기 어려운 상황이라면, RL 문제를 풀기 위해서는 approximation(근사) 기법에 의존해야 한다. 물론, dynamic program을 근사하는 것은 매우 어려운 부분이다. Bertsekas는 최근 "dynamic programming and optimal control"의 개정판을 출간했으며, 해당 책 2권의 6장을 살펴보면 dynami..
 [RL] Catching Signals That Sound in the Dark
[RL] Catching Signals That Sound in the Dark
강화학습의 본질은 시간대별로 dynamic하게 변하는 시스템의 미래를 형상화하는데 이전의 데이터를 활용하는 것이다. 강화학습의 가장 흔한 예가 episodic model을 따르는 것인데, 이는 특정 단위의 action이 정의되고, 시스템 상에서 테스트되었고, 특정 단위의 reward와 state가 관찰되고, 이런 이전의 action과 reward, state 정보들이 결합되어 행동을 결정하는 policy를 향상시키는데 사용되는 것이다. 시스템과 상호반응하는 것 자체가 매우 고급지고 복잡한 모델이기도 하고, 일반적인 확률적인 최적화 방식에 비하면 조금 더 복잡하다고 고려되기도 한다. 미래의 성능을 향상시키기 위해서 수집된 데이터 모두를 잘 활용하는 방법이 있을까? policy gradient나 random..
- Total
- Today
- Yesterday
- Pipeline
- Expression Blend 4
- Kinect
- reward
- 강화학습
- processing
- End-To-End
- 한빛미디어
- RL
- Windows Phone 7
- ai
- Kinect SDK
- Off-policy
- Kinect for windows
- ColorStream
- DepthStream
- TensorFlow Lite
- bias
- 딥러닝
- Policy Gradient
- Variance
- windows 8
- arduino
- Distribution
- Offline RL
- dynamic programming
- 파이썬
- SketchFlow
- Gan
- PowerPoint
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |