

 [R] Basic DataType
[R] Basic DataType
R도 결국 프로그래밍을 해야 결과를 얻을 수 있는 부분이고, 여러가지 연산이 들어가다 보니 자연적으로 연산에 필요한 데이터를 어딘가에 저장할 곳이 필요하다. 당연히 여타 프로그래밍과 마찬가지로 DataType(자료형)이라는 걸 사용하게 되고, R에서는 대표적으로 3가지의 DataType을 많이 사용한다. - logical - numeric - character logical은 쉽게 말해서 논리적인 값을 말한다. C같은데서도 크게 True와 False라는 형태의 Boolean DataType을 지원하는데 R에서도 마찬가지로 TRUE와 FALSE 라는 상수로 logical을 표현한다. 그리고 다른거와 다르게 한가지가 logical 변수에 포함되는데 그게 NA(Not Available) 이라는 것이다. 말그대..
 [ML] Million Song Dataset
[ML] Million Song Dataset
분산처리 과제를 하다보니까 음악과 관련한 데이터 처리에 관한 내용이 있었는데, 관련 dataset을 공유해보고자 한다. Columbia 대학에 있는 LabROSA라는 데서 만든 음악 정보와 관련한 Dataset이다. 여기에는 음악과 관련한 metadata나 audio feature 같은게 포함되어 있고, 실제 과제에서 사용하는 Dataset은 10000개 정도의 음악 샘플을 가지고 학습을 할 것이다. 사실 이 10000개라는 정보량이 이 Dataset에서 제공하는 정보량의 약 1%에 해당하는 분량이다. 그러니 실제 우리가 직접 다룰 수 있는 건 대략 백만여개 정도의 곡이 되는 것이다. 이런 걸 어떻게 써먹을까? 우리 주변에도 음원 서비스를 제공하는 업체들이 여러군데 있다. 보통 그런데 들어가면 사용자에게..
 [Big Data] Data Cleaning & Integration
[Big Data] Data Cleaning & Integration
전에도 잠깐 이야기했었는데, 요즘 MIT에서 하는 Tackling the Challenges of Big Data 라는 과목을 듣고 있다. 비싼돈 주고 듣는 수업이라서 나름 준비도 하고, 녹화도 해가면서 모르는 내용은 다시 보고 있는데, 생각보다 빅데이터에 관한 포괄적인 개론을 다루고 있어서 많은 걸 배우고 있다. 어떤 글에서도 봤는데, 사람들 사이에서 아직도 빅데이터나 사물인터넷에 대한 개념이 아직까지는 뚜렷하지 않은 듯하고, 나역시 정확히 뭐다 라고 정의하기는 참 힘든 부분이 있었는데, 그래도 이 강의를 들어보니까, 빅데이터와 관련해서 어떤 연구가 진행되고 있고, 어떤 기법들이 사용되고 있는지에 대해서 대충 가늠할 수 있는 듯 했다. 그 중 한 내용을 잠깐 요약을 해보고자 한다. 지금 듣고 있는 강의..
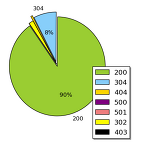 [Big Data]Apache Spark를 활용한 예제 - web page request analysis
[Big Data]Apache Spark를 활용한 예제 - web page request analysis
마침 빅데이터 강의 과제를 하는 도중에 재미있는 주제가 있어서 한번 소개해보고자 한다.미국 Florida에 보면 흔히 잘 알고 있는 NASA 우주센터가 있다. 그런데 사실 여기는 우주에 관해서만 연구하는 장소만 있는게 아니라 WWW 서버가 있는 곳이기도 하다. 다시 말해 미국에서 인터넷 연결을 되어 있는 곳이라면 이 서버를 거쳐서 원하는 정보를 주고 받게 되는 것이다. 당연히 이 서버로 들어오는 정보는 사용자가 어디로 request를 하는지, 최종적인 목적지(endpoint), 그리고 그 페이지를 접속했을 때 받은 request code 등이 있겠다. (이 모든게 HTTP 프로토콜 안에 정의되어 있다.) 물론 이 정보를 활용하게 된다면 사람들이 어떤 페이지에 많이 접속하는지, 혹은 어떤 페이지에 접근했을..
 [Big Data] Apache Spark를 이용한 과제 수행
[Big Data] Apache Spark를 이용한 과제 수행
최근에 듣기 시작한 과목중에 분산 시스템을 활용한 빅데이터 강의가 있길래 듣고 있다. apache spark 라는 걸 사용해서 진행한다는데 앞으로 어떤걸 배울지 궁금하다. 화면으로 보이는 내용이 바로 ipython notebook이라는 건데, web상에서 실시간으로 문서 작성, 수정 및, python code를 직접 수행할 수 있게끔된 일종의 포멧형태이다. 강의 과제는 보통 이렇게 notebook 형식으로 주고 그안에 제시된 과제를 spark를 이용해서 해결하는 방법으로 진행되는 거 같았다. 그런데 무엇보다 신기했던건 vagrant라는 툴이었다. 좀 찾아보니까 이 툴은 가상머신 관리 프로그램이라고 한다. 보통 특수환경을 요구했던 강의들은 그 환경이 구축된 VM 이미지를 배포했었다. 그런데 아무래도 일반 ..
 [R] Generate Heatmap using ggmap
[R] Generate Heatmap using ggmap
R로 진짜 상상하는 그 모든 것을 만들 수 있는거 같다.위의 이미지는 chicago 시내에서 발생하는 차량 도난 데이터를 google maps에서 뽑은 지도 위에 올린 이미지다. 그리고 이 이미지는 미국 전역의 살인 사건 발생 빈도를 heatmap으로 표현한 것이다. legend를 보면 알겠지만 색깔이 밝을수록 살인사건이 많이 발생하는 것을 나타낸다. 위와 같은 출력형태를 보통 heatmap이라고 하는데, 보통 빈도가 많은 곳을 진하게 표현하는 식으로 visualization이 이뤄진다. 지금 듣는 강의에선 보니까 이렇게 공공기관에서 공개한 csv 파일을 R로 import 시키고, 그 정보를 ggmap을 통해서 표현하는 과정을 보여주고 있다. 아마 내가 알기론 우리나라도 빅데이터를 정책쪽으로 반영하면서 ..
 [MOOC] Tackling the challenges of Big data
[MOOC] Tackling the challenges of Big data
요즘 공부할게 무척 많아졌다는 생각이 든다. 물론 본업이 폰의 플랫폼에 관한 것이니까 어쩔 수 없이 시스템쪽을 계속 공부하고 있지만, 점점 big data나 cloud computing에 대한 관심과 더불어서 온라인강의에서도 그런 강의들을 많이 제공하는 것 같다. 예를 들어서 현재 듣고 있는 강의중에 MIT에서 강의하는 Analytics Edge가 그렇다. 이 강의를 듣고 있는 사람이 있으려나 싶은데, 정말로 재미있는 주제를 통계와 기계학습과 관련해서 가르친다. 쉬운 예제로는 간단한 linear model을 만들어서 포도주의 판매량을 예측하고 이에 영향을 미치는 변수를 가려낸다던지, 조금더 고민해야 될 과제로는 2012년 미 대선에 대한 결과를 실제로 머신러닝에 접목시키고, 승부를 예측하면서 실제 결과와..
 [Machine Learning] Watson in Jeopardy
[Machine Learning] Watson in Jeopardy
우연히 Text Analytics 강의를 듣다보니까 watson에 대한 동영상이 있어서 공유해본다. 아는 사람도 있겠지만 Watson은 IBM에서 만든 인공지능형 컴퓨터다. 이게 참 대단한 것은 보통 사람만이 인지한다고 여겨지는 문맥(context)를 어느정도 이해한다는 것이다. 정말 말이라고 하는 것은 항상 어려운 것이다. 지칭 대명사를 사용해도 문장에 따라 그 단어가 뭘 지칭하는지는 단순히 문장만 봐서는 알수가 없다. 그 전후의 문장을 보고 어느정도의 유사성을 띠어야 대략 유추할 수 있는 거지, 확실하게 "이건 이거다" 라고 할 수 없는 건 주변 상황에서도 많이 겪어봤을 것이다. 아무튼 이런 문맥을 어떤 특수한 mechanism을 통해서 유사성을 빠르게 찾고자 했던게 목적이고, 실제로 보면 엄청 신기..
 [R] Matrix Multiplication in R
[R] Matrix Multiplication in R
잠깐 R을 활용해서 Matrix Multiplication을 하는 방법에 대해서 소개하고자 한다. 어차피 dataset을 다루게 되면 그 dataset은 분명히 몇개의 row와 column으로 이뤄져 있을 것이고, 이를 활용해서 Linear Model을 찾으려면 반드시 필요한 작업이 Matrix Multiplication일 것이다. 예제로 다음과 같은 4개의 미지수로 이뤄진 방정식이 있다고 가정하자. 우리가 알고 싶은건 a,b,c,d 각각의 값이 되는데 실제로 손을 이용해서 계산하면 Inverse도 해줘야 되고 복잡하다. 그런데 R이나 matlab 같이 Matrix operation에 특화되어 있는 툴을 활용하면 무척 쉽게 계산할 수 있다. 일단 R에서 좌변의 coefficient에 해당하는 행렬을 만들..
 [Statistics] linear function을 활용한 세계 기록의 변화
[Statistics] linear function을 활용한 세계 기록의 변화
*이 포스트는 edX에서 진행되는 Foundations of Data Analysis의 강의 내용을 직접해본 결과물입니다. 이번에 다뤄본 내용은 시간에 따라서 운동선수가 갱신하는 세계 기록이 시간에 따라서 어떻게 변하는지를 확인하는 것이었다. 일단 결론적으로 말하자면 매우 linear하게 변한다. 보통 이런 패턴을 하나의 linear function으로 만들어서 미래에는 어떤 기록이 나올지도 예측을 할 수도 있다. 우선 Dataset은 다음의 파일을 사용했다. 우선 R Studio에서 위의 csv 파일을 import 하면 다음과 같은 데이터들이 출력될 것이다. 잘보면 중간에 우리가 잘 아는 아사파 포웰이라던지 우사인 볼트도 있는게 보일것이다. 그 데이터는 남자 100m 세계 기록을 깬 순서를 보여주고 있..
 [Statistics] Introduction to Random Variable (2)
[Statistics] Introduction to Random Variable (2)
이전에 한 내용은 엄청 작은 data만을 가지고 했었는데 이번에는 225개의 데이터를 가지고 해보겠다. 이번에 다루는 내용은 앞에서 소개했던 control 군의 population을 알아보는 데이터를 사용했다. 이중 12개만 sampling을 하고 그것에 대한 평균을 구했다. 참고로 population이란 dataFrame은 Bodyweight이란 항목만 가지고 있다. 이렇게 하면 당연히 225개 중에서 12개를 뽑는 것이므로 조금더 데이터가 다양하게 나온다. 밑에 있는 sampling과 mean을 여러번 해보면 제각기 다른 결과를 출력한다. 이런게 Random Variable이다. 할때마다 값이 달라지는 변수.. 그런데 이전 포스트에서도 잠깐 언급했던 것처럼 우리가 원하는 결론을 도출하기 위해서는 어떻..
 [Statistics] Introduction to Random Variable (1)
[Statistics] Introduction to Random Variable (1)
* 이 포스트는 edX에 열려있는 Statistics and R for the life science 의 강의를 실제로 해본 내용입니다. 통계학을 이용한 life science의 강의 내용 중 하나가 바로 이 포스트의 제목인 Random Variable을 포함한 Probability Distribution에 대한 내용을 다뤘다. 실제 R을 이용해서 왜 Random Variable을 뽑는지가 첫 강의였는데 잠깐 강의 내용을 들여보면 다음과 같다. 우선 지방과 체중간의 관계를 쥐를 통해서 보여주려는 결과를 가지고 다뤘고, 이에 대한 data handling을 보여주고자 했다. 그런데 실험을 해본 사람은 알겠지만 xx에 대한 효과를 보여주기 위해서는 필요한게 두가지가 있다. 바로 대조군과 실험군이다. 일단 우..
 [ML] Perceptron Learning Algorithm (PLA)
[ML] Perceptron Learning Algorithm (PLA)
*잘못된 내용을 전달할 수도 있으므로 참고하시기 바랍니다. 가령 대출을 심사하는 은행원이라고 가정을 해보자. 이때 최종 목적은 돈을 잘 갚을 거 같은 사람한테 돈을 빌려주고, 그에 대한 이자를 받을 수 있게 하는 것이다. 반대로 대출 능력이 없는 사람을 걸러내서 최대한 돈을 안 빌려주는 것도 그 목적 중에 하나다. 결국 은행원이 낼 수 있는 output 자체는 돈을 빌려주냐 마냐가 될 것이다. 물론 이윤을 극대화할 수 있도록 얼마만큼 대출을 하겠느냐도 문제가 될 수 있겠지만, 지금은 일단 돈을 빌려주냐 안 빌려주냐에만 초점을 맞춰보자. 그러면 은행원은 대출을 원하는 사람의 어떤 모습을 근거로 대출 여부를 판단할까? 당연한 이야기일 수도 있겠지만 일을 할 수 있는 능력이 있느냐, 최종학력은 어떻게 되느냐,..
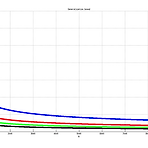 [Machine Learning] Generalization bound
[Machine Learning] Generalization bound
수업시간에 다룬 Vapnik - Chervonenkis generalization(VC generalization) 을 표현해봤다. 우리가 Machine Learning을 하는 이유 자체는 개념에도 담겨있다시피 기계를 학습시키기 위함이고, 당연히 미래에 들어올 데이터에 대한 예측을 요구하는 것이다. 이를 위해서는 기존에 받아둔 Sample Data를 가지고, 그 Sample에 대한 hypothesis를 구해서, 최종 결과와 비교해야 한다. 당연히 sample에 대한 hypothesis가 최종 결과와 거의 비슷하게 나오면, 이 hypothesis를 가지고 미래에 들어올 Data를 구별하게 될 것이다. 보통 이런 개념을 In-sample Error와 Out-of-Sample Error간의 차이로 표현하기도 ..

- Total
- Today
- Yesterday
- Distribution
- Policy Gradient
- 강화학습
- windows 8
- Gan
- DepthStream
- processing
- 파이썬
- ai
- Expression Blend 4
- Off-policy
- SketchFlow
- Offline RL
- dynamic programming
- End-To-End
- Kinect for windows
- 딥러닝
- Kinect
- TensorFlow Lite
- RL
- bias
- reward
- Pipeline
- Variance
- Kinect SDK
- Windows Phone 7
- PowerPoint
- 한빛미디어
- arduino
- ColorStream
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |