
 [RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
[RL][Review] Offline Reinforcement Learning From Algorithms to Practical Challenges
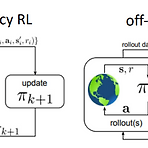
(본문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Offline Reinforcement Learning from Algorithms to Practical Challenges - Kumar et al, NeurIPS 2020 Tutorial (사이트, 실습코드) 원래 거진 3시간짜리 tutorial이기 때문에 정리하는데 시간이 걸릴듯 하다. 그래도 전반적인 Offline RL의 문제와 이론에 대해서 잘 설명되어 있어서 차근차근 설명해보고자 한다. 기본적인 RL 내용도 포함되어 있어, Offline RL 부분만 뽑아서 정리한다. Can we develop data-driven RL methods? 보통 강화학습이라고 하면 다음과 같은 환경을 가정하고 진행한다. 일반적으로는 어떤 환경이 주..
 [RL][Review] Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (BEAR)
[RL][Review] Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction (BEAR)
(논문의 의도를 가져오되, 개인적인 의견이 담길 수도 있습니다.) Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction - Kumar et al, NeurIPS 2019 (논문, 코드) 요약 Off-policy RL은 샘플링 관점에서 효율적인 학습을 위해서 다른 policy (behavior policy)로부터 수집한 데이터로부터 경험을 배우는데 초점을 맞추지만, Q-learning이나 Actor-Critic 기반의 off-policy Approximate dynamic programming 기법은 학습시 사용된 데이터와 실제 데이터간의 분포가 다른 문제로 인해서 on-policy data를 추가로 활용하지 않고서는 성능을 개선하기가 어..
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트를 통해 배울 수 있었던 것은 크게 다음과 같다. Episode가 끝나야 Value function을 update할 수 있었던 Monte Carlo Method와 다르게 TD Learning은 BootStrapping 기법을 사용해서 Value function을 update할 수 있었다. TD Learning 중에서도 Target Policy와 Behavior Policy의 일치여부에 따라서 On-policy method인 SARSA와 Off-policy method인 Q-learning으로 나눠볼 수 있다. 아무튼 두가지 방법 모두 state action value를 활용한 Bellm..
 [RL] Q-learning: Off-policy TD Control
[RL] Q-learning: Off-policy TD Control
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 사실 Q-learning에 대해서는 옛날에 한 포스트를 통해서 다뤘었는데, 다시 정리를 해보고자 한다. 일단 알고리즘은 아래와 같다. 이전 포스트에서 다뤘던 SARSA와 거의 비슷한데, 한가지 다른 부분이 바로 Value function을 update하는 부분이다. 다시 한번 SARSA의 update 부분을 살펴보자. Q(St,At)←Q(St,At)+α(Rt+1+γQ(St+1,At+1)−Q(St,At)) 그런데 위의 식은 사실 Dynamic Programm..
 [RL] Off-policy Learning for Prediction
[RL] Off-policy Learning for Prediction
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) 이전 포스트에서는 Monte Carlo method를 Policy Iteration에 적용하기 위해서 필요한 Exploration policy 중 하나인 ϵ-soft policy를 소개했다. 그러면서 참고로 소개한 내용 중에 On-policy와 Off-policy라는 것이 있었다. 이 중 Off-policy에 초점을 맞춰서 다뤄보고자 한다. 잠깐 설명이 되었던 바와 같이, On-policy는 action을 선택하는 policy를 직접 evaluate하고, improve시키는 방식을 말한다. 반대로 Off-policy는 action을 선택하는 policy와는 별개로 별도의 pol..
 [RL] Exploration Methods for Monte Carlo
[RL] Exploration Methods for Monte Carlo
(해당 포스트는 Coursera의 Sample-based Learning Methods의 강의 요약본입니다) Monte Carlo Control의 알고리즘을 보면 초기에 state와 action을 random하게 주는 Exploring Starts (ES)가 반영되어 있는 것을 확인할 수 있었다. 이 방법은 Optimal Policy를 찾는데 적합한 알고리즘일까? 사실 초기 state와 action을 random하게 주는 이유는 policy를 update하는데 있어 필요한 State-Action Value Function을 확보하기 위함이었고, 처음이 지난 이후에는 처음에 설정된 policy π에 따라 움직이는 이른바 deterministic policy이다. 분명 State-Action Va..
- Total
- Today
- Yesterday
- 강화학습
- Kinect SDK
- 인공지능
- Pipeline
- Distribution
- SketchFlow
- reward
- arduino
- Offline RL
- Kinect
- RL
- 한빛미디어
- Kinect for windows
- windows 8
- 딥러닝
- Gan
- bias
- Off-policy
- Expression Blend 4
- dynamic programming
- DepthStream
- Policy Gradient
- TensorFlow Lite
- processing
- 파이썬
- ColorStream
- PowerPoint
- Windows Phone 7
- End-To-End
- Variance
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |