

 [ML] Data내에서 NaN 데이터 처리하기
[ML] Data내에서 NaN 데이터 처리하기
가끔 데이터를 외부에서 읽어오다보면 원하지 않는 데이터들이 포함되는 경우가 종종 있다. 예를 들어 전체 결과에 영향을 주는 변수(outlier)가 있는가 하면, 아예 데이터가 없는 경우(NaN)도 존재한다. 이중 NaN을 처리하는 방법에 대해서 잠깐 언급해보고자 한다. 내가 생각하는 NaN이 있으면 안 좋은 이유는 딱 한가지, NaN 자체가 Pandas 내에서 mean이나 median을 계산할 때, 그 자체적으로 수행이 안된다는 것이다. 가령 NaN은 내부적으로 np.nan으로 처리되는데 이 값에 어떤 값을 더하거나 빼도 그 결과가 NaN으로 반환되어 정상적인 결과를 얻을 수 없다. 이 때문에 NaN을 배제해야 할 필요성이 생기는데, 이를 해결하는 방법도 여러가지가 있다. 아예 NaN은 배제하고 계산한다..
 [Python] Cartopy install 및 실행
[Python] Cartopy install 및 실행
Python visualization package 중에 Cartopy라는 게 있다. 흔히 데이터를 출력하는데 있어 지리 정보를 포함하는 경우, 이를 실제 map에다가 투영시킬 때 이 package를 사용한다. Anaconda repo에서도 이를 배포하고 설치해야 import시킬 수 있다. 설치 방법은 간단하다.1conda install -c conda-forge cartopycs 다음 spyder에서 사용하면 된다. 아마 메인으로 쓰는 건 coordinate reference system (crs)와 coordinate feature(cfeature) 일 것이다. 내가 듣고 있는 강의에서는 3마리 새의 이동 경로를 그려보고 실제 지도상으로 투영시키는 작업을 했다. 그래서 그 과정을 취하면 이런 결과를 ..
 [ML] KNN 구현해보기 - Finding Nearest Neighbors
[ML] KNN 구현해보기 - Finding Nearest Neighbors
이전 포스트에서 거리를 구하는 함수와 다수결 값을 구하는 함수를 정의했었고, 이번 포스트에서는 kNN 의 핵심인 가까운 이웃을 찾는 함수를 구현해보고자 한다. 우선 kNN의 처리 과정을 단계별로 써보면1. 전체 데이터 집단을 살펴보고, 2. 그중 한점과 다른 점간의 거리들을 구한 후 3. 그 거리를 나열해 기준에 적합한 점들을 반환해주면된다. 이게 kNN이 동작하는 원리다. 예를 들어 이런 케이스를 살펴보자위와 같이 빨간색 점들이 있는데 파란 점이 왔을때 어떤 빨간점이 파란점과 가깝다고 표현할 수 있을까? 당연히 딱 보기에도 (2, 2)에 있는 점과 (3, 2)에 있는 점이 파란 점에 가깝다고 할 수 있다. 이게 가깝다고 정의한것은 당연하다. 두 점 사이의 거리를 구해 그게 가장 짧은 거리를 찾은 것이다..
 [ML] KNN 구현해보기 - Introduction
[ML] KNN 구현해보기 - Introduction
머신러닝의 수많은 주제 중 아마 제일 잘 다뤄지는 주제가 바로 Classification이 아닐까 생각된다. 물론 어떤 값을 예측한다던가, 어떤 일이 발생할 확률 같이 명확한 수치가 나오는 건 아니지만, 과거의 Data를 통해서 미지의 입력값이 어떤 종류로 분류하는 것 자체도 머신러닝에서 다뤄질 수 있는 주제가 아닐까 생각한다. 물론 이런 Classification 문제를 해결하는 여러 알고리즘들이 있겠지만 이번 포스트를 통해서 다루고자 하는 주제는 흔히 k-NN이라고 불리는 k-Nearest Neighborhood Algorithm 이다. 이름이 사실 거창해서 그렇지 두 점사이의 거리를 구하는 공식(보통 Euclidean Distance라고 표현한다.)만 알고 있으면 그 원리가 명확하게 설명되는 알고리..
 [Python] Numpy Random Module
[Python] Numpy Random Module
numpy package에는 random이라는 module이 있다.여기에 있는 random 함수를 쓰면 0에서 1 사이의 수를 반환해준다.123import numpy as np numpy.random.random()cs만약 여러개의 값을 한꺼번에 반환받고 싶으면, random 함수의 인자로 자기가 받고 싶은 자료의 크기를 넣어주면 된다. 예를 들어 1x5의 random 함수의 결과를 받고 싶으면 1numpy.random.random(5)cs를 해주면 되고, 만약 2행 2열의 행렬의 형태로 받고 싶으면1numpy.random.random((2,2))cs위와 같이 tuple의 형식으로 집어넣으면 된다. 물론 이에 대한 반환값의 자료는 numpy의 array 형태로 나온다. 물론 위의 형태는 단순한 rando..
 [DL] 해보면서 배우는 딥러닝 - ANN 평가하기
[DL] 해보면서 배우는 딥러닝 - ANN 평가하기
( 이 포스트는 Udemy에서 진행되는 DeepLearning A-Z 강의를 요약, 정리한 내용입니다.) 지난 포스트까지 ANN을 구현해보고 실제로 84% 가량의 결과를 얻은 것을 확인했다. 그런데 실제로 해본 사람이라면 알겠지만, 할때마다 결과가 달라지는 것을 알 수 있을 것이다. 나같은 경우에도 처음 할때는 86% 정도의 Accuracy를 얻을 수 있었지만, 하면 할수록 낮아지는 것을 확인할 수 있었다. 그럼 내가 얻은 결과가 과연 신뢰할 수 있을만한 결과일까? 혹은 우연치않게 맞은 결과일까? 결국 확인해보는 수밖에 없다. 먼저 살펴보기에 앞서 왜 이럴 수 밖에 없는지를 보고자 한다. 우리가 처음 Dataset을 생성할 때, 학습을 시킬 Training Set과 검증을 할 Test Set으로 구분했다..
 [DL] 해보면서 배우는 딥러닝 - tensorflow를 GPU로 구동하는 방법
[DL] 해보면서 배우는 딥러닝 - tensorflow를 GPU로 구동하는 방법
Conda를 활용해서 tensorflow 환경을 구성하고 package를 설치할 때 tensorflow-gpu를 설치했다면, 기본 설정이 CPU 연산이 아닌 GPU연산으로 변경된다. 이렇게 될 경우 keras의 Fit()함수를 써서 학습을 시킬 경우 cuDNN package를 못찾는 경고가 뜬다. 이 경고는 해당 시스템에 cuDNN이 포함된 CUDA Toolkit이 설치되어 있지 않기 때문에 발생하는 문제이고, Nvidia 사이트에서 CUDA Toolkit을 설치해야 한다. 참고로 윈도우 환경에서는 랩탑이든 데스크탑이든 Nvidia 칩셋이 있는 경우에만 gpu를 통해서 연산이 가능하다. AMD나 Intel GPU를 사용하려면 OpenCL같은게 포팅되어 있어야 하는데, 얼핏 찾기로는 Linux용 tenso..
 [DL] 해보면서 배우는 딥러닝 - ANN 구현 (3)
[DL] 해보면서 배우는 딥러닝 - ANN 구현 (3)
* 여기에 담긴 내용은 Udemy에서 진행되는 DeepLearning A-Z(https://www.udemy.com/deeplearning)의 일부를 발췌했습니다. 지난 포스트까지 했던 작업은 Artificial Neural Network의 토대를 잡고 그 안에 들어갈 Layer의 정의, 특히 1개의 Input Layer와 2개의 Hidden Layer, 그리고 마지막 output Layer를 만들고 각각에 적용할 Activation function까지 정의했다. 이제 만들어진 Layer를 ANN로 묶어서 처리하는 과정이 필요하다. Keras에서는 이 과정을 compile이라고 말하는 것 같다. compile 함수의 인자로는 다음 내용이 들어간다. 여기서 필요한 인자는 optimizer, loss, me..
 [DL] 해보면서 배우는 딥러닝 - ANN 구현 (2)
[DL] 해보면서 배우는 딥러닝 - ANN 구현 (2)
* 여기에 담긴 내용은 Udemy에서 진행되는 DeepLearning A-Z(https://www.udemy.com/deeplearning)의 일부를 발췌했습니다. 지난 포스트에서 test set과 training set을 생성했다. 이제 Artificial Neural Network을 구현해야 한다. 몇가지 Neural Network 생성용 library가 있는데, 여기서는 tensorflow와 Keras를 사용하려고 한다. 추가로 Keras의 내부 모듈중 Sequential 과 Dense를 사용하고자 한다. 참고로 Sequential은 Neural Network를 초기화하는데 필요한 모듈이고, Dense는 Neural Network를 구성하는 Layer를 생성하는데 필요하다.32333435# Impo..
 [DL] 해보면서 배우는 딥러닝 - ANN 구현 (1)
[DL] 해보면서 배우는 딥러닝 - ANN 구현 (1)
* 여기에 담긴 내용은 Udemy에서 진행되는 DeepLearning A-Z(https://www.udemy.com/deeplearning)의 일부를 발췌했습니다. 나도 딥러닝이라는 것을 잘 모르는 상태에서 뭔가를 해보려는데 마침 간단한 python 예제(?)가 있어 같이 코드를 보면서 진행해보고자 한다. 우선 학습의 목적은 고객 정보가 담긴 Dataset을 분석해 성향을 분석하는 일종의 Churn Modeling이 되겠다.우선 spyder를 실행하고 필요한 Library를 불러온다. 일단 수치연산을 위한 numpy와 pandas, 시각화를 위한 matplotlib을 가져온다.123import numpy as npimport matplotlib.pyplot as pltimport pandas as pdc..
 [DL] 해보면서 배우는 딥러닝 - Theano, Tensorflow, Keras 설치 (windows판)
[DL] 해보면서 배우는 딥러닝 - Theano, Tensorflow, Keras 설치 (windows판)
회사에서 스터디한다고 tool 설치하다가 삽질하던 case가 있어서 한번 남겨본다. 우선 windows 환경에서 제일 쉽게 설치하는 방법은 Anaconda라는 python기반의 IDE를 사용해서 설치하는 것이다. 물론 메인 사이트에선 python만 사용해서 설치하는 방법을 소개하고 있지만, 이게 더 편한거 같다. 우선 Anaconda를 설치한다. 이때 설치할때 중간 옵션에 보면 anaconda의 실행영역을 시스템 PATH 에 넣겠냐는 설정이 있는데, 이를 반드시 설정하고 설치한다.(기본적으로 체크되어 있던 것으로 설치한다.) 정상적으로 설치되었으면 command prompt를 열어서 conda를 실행해본다. 이때 conda의 help comment가 출력되지 않으면 해당 실행영역이 PATH로 안잡혀있다는..
 [Optimization] JuliaBox
[Optimization] JuliaBox
이런 문제를 아마 어디서 본적이 있을 것이다. 아마 눈보다 손이 빠른 사람은 벌써 연습장을 꺼내서 변수를 통일하고 미지수를 줄이려 노력할 것이다. 아쉽게도 이문제는 해가 정해진 문제가 아니다. 따라서 손으로 계산한다고 해도 그 답을 쉽게 구할 수 없다. 보통 이런식의 문제를 NLP(Non-linear Programming) 이라고 하는데, 말그대로 비선형적인 문제에 대한 답을 구하는 절차라고 이해하면 좋을 듯 하다. ( 사실 처음에 Programming이란 말이 들어가서 진짜 코딩하고 그런건가 싶었는데, 그게 전혀 아니었다.) 아무튼 이런 문제의 목적은 solution, 그중에서도 가장 최적의 solution(optimal solution)을 구하는 것이다. 앞에서도 언급했다시피 손으로 풀기 힘든 문제이..
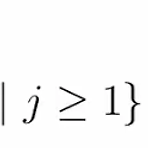 [Probability] Coin Flip Example
[Probability] Coin Flip Example
주사위와 함께 확률문제에서 가장 많이 나오는 요소중 하나가 바로 동전이다. 물론 주사위에 비하면 sample space도 작기도 하지만 무엇보다도 확률과 관련한 문제를 직관적이고 쉽게 표현한다. 다음과 같은 event를 가정해보자. 하나의 동전을 여러번 반복해서 던지고 이에 대한 결과를 기록하는 것으로 말이다. 이때의 sample space는 다음과 같이 표현할 수 있다.S = { r1r2r3 ... | rj = T or rj = H } (참고로 여기서 T는 앞면(toward), H는 뒷면(head) 의 약자이다) 이때의 outcome은 주사위를 몇번 던졌냐에 따라서 다 다르다. 무작위로 HTTTHTTHTHTH... 라는 식으로 나올 수도 있는 것이다. 물론 조건을 넣을 수도 있다. 가령 첫번째 두번째 ..
 [Probability] Dice Example
[Probability] Dice Example
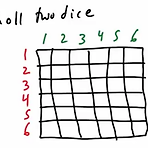
보통 확률 이야기가 나오면 가장 많이 나오는 내용이 주사위다. 물론 주사위도 여러개 있겠지만, 흔히 다루는 주사위인 정육면체를 두고 가정해보자. 그러면 빨간 주사위를 던졌을 때를 event라고 정의했을 때, 이 event에서 얻을 수 있는 outcome은 1,2,3,4,5,6 6개이다. 마찬가지로 초록 주사위를 던졌을 때 event도 얻을 수 있는 outcome이 동일하다. 이걸 하나의 sample space로 표현하면와 같이 도식화 할 수 있다. 이걸 이제 수학적으로 표현하면S = { (1,1), (1,2), (1,3), ... (6,5), (6,6)} 가 되는데, 이걸 좀더 유식하게 표현하면,S = { (i,j) | 1 ≤ i ≤ 6, 1 ≤ j ≤ 6} (i는 빨간 주사위의 outcome) (j는 ..
어떤 예측되지 않은 일이 발생했을 때, 보통 outcome이 발생했다고 표현한다. 이런 outcome들이 모여 하나의 집합을 이룰 때, 이걸 event라고 표현한다. 여기서 그치지 않고, 지금 논의되고 있는 시점상에서 이뤄진 event들, 혹은 outcome들 모두를 통틀어서 sample space라고 하고, 기호로는 S 로 표현한다. 물론 outcome이 발생하지 않은 case도 있을텐데 이같은 경우는 empty set (∅) 이라고 말한다. 집합 이야기가 나왔으니, 집합 상관관계를 따질 수 있다. event A안에 있는 모든 outcome이 event B에도 포함되어 있다고 하면, 이같은 케이스는 A가 B에 포함되어 있다고 표현하고 수학적 기호로는 A ⊂ B표현한다. 사실 나도 이 개념이 맨처음에는 ..
- Total
- Today
- Yesterday
- RL
- End-To-End
- Distribution
- Off-policy
- Variance
- Windows Phone 7
- PowerPoint
- 강화학습
- Gan
- Kinect SDK
- Pipeline
- bias
- 한빛미디어
- ColorStream
- Policy Gradient
- processing
- SketchFlow
- ai
- Offline RL
- dynamic programming
- 파이썬
- arduino
- windows 8
- 딥러닝
- Kinect
- TensorFlow Lite
- Expression Blend 4
- DepthStream
- reward
- Kinect for windows
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |