

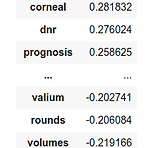
 [ML][TIP] Logistic Regression에서의 coefficient를 통한 Feature importance 확인
[ML][TIP] Logistic Regression에서의 coefficient를 통한 Feature importance 확인
요새 듣고 있는 강의 중 하나가 MIT에서 강의하는 "Machine Learning for Healthcare"라는 것인데, 이 강의에서는 다양한 의학데이터(텍스트, 영상 등)을 활용해서 머신러닝/딥러닝 모델을 만드는 것을 다루고 있다. 단순히 모델을 만드는 코딩 스킬보다도 의학 데이터에 내재된 어려움과 이를 해결하기 위한 전처리 기법, 생각해볼만한 통계적 기법 등을 다루고 있어서, 재미있게 듣고 있다. 사실 의학쪽으로 domain expert가 아닌 이상에야 해당 데이터를 다룰 일은 없겠지만, 내가 잘 알지 못하는 분야에서 어떻게 활용되는지를 배우고 나면, 또다른 새로운 분야에 접목시킬 때는 어떻게 고민해봐야 할지 감이 올 것 같아서 듣는 이유가 있다. Machine Learning for Health..
 [ML] Theory of the perceptron
[ML] Theory of the perceptron
MIT openlearninglibrary에서 perceptron 관련 좋은 내용이 있어 공유해본다. 참고로 이전에도 한번 perceptron 관련 내용을 다룬 적이 있다. [Machine Learning] Perceptron Learning Algorithm (PLA) *잘못된 내용을 전달할 수도 있으므로 참고하시기 바랍니다. 가령 대출을 심사하는 은행원이라고 가정을 해보자. 이때 최종 목적은 돈을 잘 갚을 거 같은 사람한테 돈을 빌려주고, 그에 대한 이 talkingaboutme.tistory.com Linear separability \(x\)와 \(y\)로 이뤄진 어떤 dataset \(\mathcal{D}_n\)이 있는 상태에서 해당 dataset 전부를 통틀어 아래의 수식을 만족하는 param..
 [RL] Windows 10에서 mujoco_py 구동
[RL] Windows 10에서 mujoco_py 구동
이전에 Linux에서 mujoco-py를 돌릴 때 발생할 수 있는 그래픽 라이브러리 관련 오류를 해결하는 방법에 대해서 공유한 적이 있다. 사실 그것도 그러려니와 Linux에서 할 수 있는게 많아, 집에서도 Windows 10이랑 Linux랑 듀얼부팅으로 설치해서 사용하고 있다. 그런데 아무래도 Windows 10에서 Linux로 넘어가려면 재부팅도 해야되고, 신경쓸게 많아져 Windows 10에서 할 수 있는 방법이 있지 않을까 찾아보다가, 마침 이와 관련된 글이 있어서 직접해보고 공유해보고자 한다. Install OpenAI Gym with Box2D and Mujoco in Windows 10 How to install OpenAI Gym[all] with Box2D v2.3.1 and Mujoco..
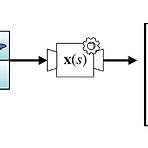 [RL] Feature Construction for Linear Methods
[RL] Feature Construction for Linear Methods
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) - 관련된 책 내용 : 9.4 - Linear Methods : 9.5.3 - Coarse Coding : 9.5.4 - Tile Coding : 9.7 - Non-linear Function Approximation : ANN 이전 포스트에서 설명한 Linear Function Approximation은 일반적으로 표로 표현된 value function을 어느 유사한 function으로 근사함으로써 효율성을 가져오자는 취지에서 나온 것이고, 보통 이 function을 조절하는데 weight vector \(\mathbb{w}\)를 사용한다. 그래서 이에 대한..
 [DS] Distributions
[DS] Distributions
Probability mass functions Make a PMF Plot a PMF Cumulative distribution functions Make a CDF Compute IQR Plot a CDF Comparing distribution Extract education levels Plot income CDFs Modeling distributions Distribution of income Comparing CDFs Probability mass functions import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from empiricaldist import Pmf, Cdf ..
Categorical Plot Types¶ In [1]: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline stripplot() and swarmplot()¶ In [2]: df = pd.read_csv('./dataset/schoolimprovement2010grants.csv') In [3]: sns.stripplot(data=df, x='Award_Amount', y='Model Selected', jitter=True) Out[3]: In [4]: # Create and display a swarmplot with hue set to the..
1. The most Nobel of Prizes¶ The Nobel Prize is perhaps the world's most well known scientific award. Except for the honor, prestige and substantial prize money the recipient also gets a gold medal showing Alfred Nobel (1833 - 1896) who established the prize. Every year it's given to scientists and scholars in the categories chemistry, literature, physics, physiology or medicine, economics, and ..
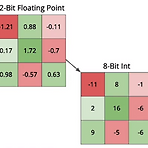 [DL] Optimization Techniques
[DL] Optimization Techniques
보통 딥러닝에서 Model의 size를 줄이거나 동작 속도를 향상시키기 위해서 수행하는 Optimization 기법으로 크게 3가지 방법을 드는데, accuracy 측면에서 약간 손해보면서 Model Size를 줄이는 Quantization, training시 필요한 metadata나 Operation을 안쓰게끔 하는 Freezing, 그리고 Layer의 복잡성을 줄이기 위해서 여러 Operation을 하나의 Operation으로 바꾸는 Fusion 등이 있다. Quantization Quantization은 Model을 구성하는 weight이나 bias들이 과연 몇 bit으로 표현하느냐와 연관된 내용이다. 물론 정확성 측면에서는 각 weight와 bias들이 소수점 자리까지 정확히 update하고 계산..
팁이라고 하기도 그런데 기억차원에서 남긴다. 데이터가 서버한곳에 모아져 있을 경우, 거기에 저장되어 있는 데이터를 처리하고 싶은 경우가 있다. 보통 가장 쉽게 할 수 있는 방법은 아래와 같이 서버의 데이터를 로컬PC로 다운로드한다. (혹은) Jupyter server가 실행된 PC상으로 업로드를 해서 처리한다. 일텐데, 굳이 이런 다운로드/업로드 과정을 생략하려면, python의 requests library를 사용해서 url로 직접 접속할 수 있게 할 수 있다. 보통은 github같이 공개된 곳에 올리면 해당 dataset의 url에 requests.get를 하고 그 데이터의 text를 pd.read_csv()등을 통해서 처리할 수 있다. 예시는 아래와 같다. import pandas as pd imp..
 [DL] Types of Computer Vision Models
[DL] Types of Computer Vision Models
보통 computer vision에 활용되는 model은 수행 task에 따라서 크게 3가지 형태로 나눠볼 수 있다. 이미지를 분류하는 Classification, 이미지를 인식하는 Detection, 그리고 이미지를 따오는 Segmentation이다. Classification은 말 그대로 이미지나 이미지내 특정 object에 대한 class를 결정하는 것이다. 이에 대한 결과는 참/거짓 과 같은 2진으로 나올 수도 있지만, class가 여러 개라면 그 class의 종류만큼 나올 수 있다. (참고로 일반적으로 많이 사용되는 ImageNet Dataset은 약 20000여개의 class로 구성되어 있다고 한다.) 보통은 예측된 class에 대한 확률값으로 표기되어, 사람이 딱 봤을 때 가장 높은 확률을 ..
 [DL] Pre-Trained Model in OpenVINO
[DL] Pre-Trained Model in OpenVINO
일반적으로 pre-trained model이란 말그대로 training을 끝낸 이후에 산출물로 나온 모델을 말한다. 보통 training을 할 때 가장 큰 문제가 데이터의 특성을 이해하기 위해서 데이터 자체도 많이 모아야 할 뿐더러, 이에 필요한 비용이나 시간적인 문제가 발생하는데, pre-trained model을 사용하면 이런 문제를 피할 수 있다. Pre-Trained Model은 Intermediate Representation (IR) format으로 구성되어 있고, 보통 xml같은 markup language나 binary 형태로 이뤄져 있다. 그래서 이걸 Inference Engine, 간단하게 말해 학습된 모델로부터 결과를 얻어내는 영역에 넣어주면 우리도 pre-trained model을 ..
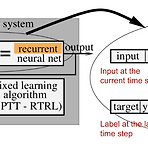 [RL] Meta Reinforcement Learning
[RL] Meta Reinforcement Learning
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Meta Reinforcement Learning Meta-RL is meta-learning on reinforcement learning tasks. After trained over a distribution of tasks, the agent is able to solve a new task by developing a new RL algorithm with its internal activity dynamics. This post starts with the origin of meta-RL an lilianweng.github.io Meta-RL은 강화학습 task에 meta l..
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트들을 통해서 설명하고자 했던 것은 기존의 Q-table과 같은 Tabular 방식이 아닌, Value를 하나의 Function, 즉 Value Function으로 근사하는 방법이 존재하고, 이때 이 근사된 Value Function과 실제 Value Function과의 오차를 줄일 수 있는 방법으로 Gradient Descent를 적용할 수 있다는 것이었다. 그래서 Function Approximation을 Monte Carlo에 적용한 Gradient MC과 제한적이기는 하나, Gradient를 TD Learning에 적용한 Semi-Gradien..
 [RL] The Objective of TD
[RL] The Objective of TD
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 역시 Function Approximation 기법을 Monte Carlo Method처럼 TD Learning에다가도 접목시킬 수 있다. 우선 Monte Carlo method에 Function Approximation을 접목한 Gradient Monte Carlo에서 weight이 update되는 과정을 다시 돌아보면 다음과 같다. $$ \mathbf{w} \leftarrow \mathbf{w} + \alpha[ G_t - \hat{v}(S_t, \mathbf{w})] \nabla \hat{v}(S_t, \mathbf{w}) $$ 이를 사용하면 estima..
 [RL] The Objective for On-policy Prediction
[RL] The Objective for On-policy Prediction
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트를 통해서 기존의 tabular method가 아닌 Function Approximation으로 value function을 정의하는 방법을 대략적으로 설명했다. 일단 뭐가 되던 간에 우리가 만들 value function은 각 state에 대한 value function이 차별성을 잘 띄고 있어야 하고(high discrimination), 전체 state에 대한 일반화도 잘되어야 한다.(high generalization) 그렇게 해서 어떤 linear value function \( \hat{v}(s, \mathbf{w})\) 을 만들었다고 가..
- Total
- Today
- Yesterday
- TensorFlow Lite
- DepthStream
- windows 8
- Off-policy
- reward
- 한빛미디어
- SketchFlow
- Gan
- 딥러닝
- Pipeline
- Kinect SDK
- dynamic programming
- ai
- arduino
- processing
- Policy Gradient
- Windows Phone 7
- Variance
- ColorStream
- PowerPoint
- Kinect
- Distribution
- Offline RL
- Expression Blend 4
- RL
- 파이썬
- End-To-End
- bias
- 강화학습
- Kinect for windows
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |