
 [ARM] Registers on the ARM Cortex M4
[ARM] Registers on the ARM Cortex M4
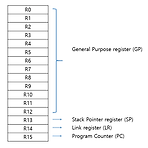
R0부터 R12 까지는 General Purpose(GP) Register, 즉 범용적으로 사용할 수 있는 register를 나타낸다. 이때 범용적이라고 함은 이 register field에 어떤 data가 담길 수도 있으며, 혹은 어떤 영역을 가리키는 address가 들어갈 수 있다는 것이다. R13은 Stack pointer(SP)이며, 보통 프로그램 구동시 필요한 Stack의 top을 가리키는 index를 담고 있다. R14는 Link Register 인데, 만약 어떤 함수가 호출될 경우 함수의 return address를 담고 있다. 물론 return address 뿐만 아니라 interrupt 같은 exception을 다룰때도 사용되기도 한다. 마지막으로 R15는 Program Counter(P..
 [Architecture] Processes
[Architecture] Processes
예전에 Process가 뭐냐는 이름으로 포스팅을 한적이 있다.2014/08/29 - [About Study/OS] - [Process] What is a process? 다룬지도 한참되었기도 하고 강의에 해당 주제로 하는게 있어 다시 정리해보고자 한다. Process란 현재 프로그램이 동작하는 개념 그 자체를 말한다. 프로그램이 돌아가면서 사용되는 CPU, MMU, 혹은 input/output device 로부터 resource를 할당받아서 돌아가는 주체이다. 각 process는 state 라는 것을 가지고 있는데, 사용자는 이 state를 보면서 현재 process의 상태를 확인할 수 있다. 물론 state라는 단어 자체가 상태를 의미하긴 하지만 process state에는 보통 아래와 같은 내용들이 ..
 [Architecture] MMU improvements
[Architecture] MMU improvements
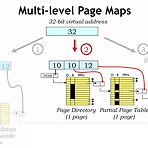
이번 포스트에서는 MMU의 효율을 높일 수 있는 방법에 대해서 다뤄보려고 한다. 지난 시간에 언급한 내용중에 보면 - Page map의 entry 중 일부만 physical memory에 상주한다. 라고 한 내용이 있었다. 왜 하필 일부일까. 이때도 항상 계산때 강조한 p, v, m 값을 살펴보면 된다. 지금까지 살펴본 값들을 살펴봐도 일반적으로 virtual page number에 할당된 bit수가 physical page number에 할당된 bit수보다 많은 것을 알 수 있었다. 아무래도 1대1 mapping이 발생하려면 두개의 bit수가 같아야 하는데, 그게 아니니 일부만 상주할 수 있는 것이다. 이런 문제를 해결하기 위한 방안이 multi-level page map이다. 위의 그림과 같이 vir..
 [Architecture] Contexts
[Architecture] Contexts
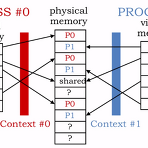
Context란 page map상의 entry에 의해서 교환되어지는 정보들을 말한다.사실상 cpu가 memory를 접근하는데 있어서 다뤄지는 정보를 말할 수도 있겠다. 아무튼 프로그램이 구동되려면 해당 프로그램도 실제 physical memory상에 올라가야 하는데, 이 것도 일종의 context로 구성되어 있다고 할 수 있다. 참고로 이런 context는 프로그램상으로 중복되지 않는다. 아는 개념이겠지만, 프로그램이 shared memory를 쓰지 않는 이상, 사용하는 memory 영역은 각각 독립적이며, 예를 등러 어떤 프로그램내에서 virtual address 0번이 가리키는 physical address는 다른 프로그램내의 virtual address 0번이 가리키는 physical address..
 [Architecture] Building the MMU (2)
[Architecture] Building the MMU (2)
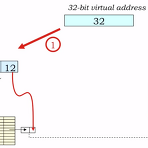
이제 TLB (Translation Look-aside Buffer)까지 적용된 MMU의 동작을 살펴볼 차례이다. CPU에서 생성된 virtual address는 맨처음 TLB를 살펴보고 기존에 저장된 cache data중 원하는 VPN->PPN 정보가 있는지를 찾게 된다. 보통 여기서는 miss의 가능성을 최대한 줄이기 위해서 size 자체는 작지만 fully-associative 형태의 SRAM cache가 들어간다. 만약 TLB에 원하는 데이터가 있으면 굳이 Page table을 거치지 않고, 직접적으로 physical memory에 접근할 수 있게 된다. 하지만 원하는 정보가 TLB에 없는 경우라면 virtual address는 page table쪽으로 가서 translation 작업이 이뤄지게 ..
 [Architecture] Building the MMU (1)
[Architecture] Building the MMU (1)
이번 포스트에서는 MMU를 어떻게 설계하는지에 대해 다뤄보려고 한다. MMU의 동작에 있어서 주요한 역할을 하는 변수는 크게 P, V, M으로 볼 수 있다. P는 virtual address, physical address에서 해당 page map의 index를 가리키는 offset을 구성하는 address의 bit 수이다. V는 virtual page number로 쓰이는 bit수이고, M은 physical page number로 쓰이는 bit 수이다. 아마 지난 포스트에서도 봤었겠지만, 이 P, V, M을 이용해서 page의 크기를 구할 수도 있고, 또는 page의 갯수도 도출할 수 있다. 위 변수로 구할 수 있는 정보는 다음과 같다. 보통 CPU를 고를 때 32bit니, 64bit니 하고 구분을 지..
 [Architecture] Page faults
[Architecture] Page faults
이런 상황을 가정해보자. 현재 상황은 CPU가 Page map상의 virtual page 5번에 접근하려고 하고 있다. 그런데 현재 해당 entry의 resident bit은 0이다. 즉, 이 virtual page가 찾고자 하는 데이터는 physical memory에 없다는 뜻이다. 이런 경우에 이전 포스트에서 소개했던 것처럼 MMU는 CPU에게 exception signal을 보내고, CPU는 context switching이 발생하면서 exception handler를 수행하게 된다. 이 전체 과정을 page fault라고 언급했었다. 우선 그때도 소개했지만 page fault가 발생하면 page fault handler는 disk로부터 읽어올 데이터를 저장할 공간을 physical memory로부..
 [Architecture] Basics of Virtual Memory (2)
[Architecture] Basics of Virtual Memory (2)
Demand Paging의 전제는 Virtual Page들이 HDD 같은 secondary storage에 있고, MMU가 비어 있는 것에서부터 출발한다. 즉, physical memory에는 Page와 관련한 정보가 없는 것부터 출발하는 것이다. 이 상태에서 CPU가 프로그램을 구동하기 시작하면, CPU내에서 사용되는 virtual address는 실제 해당 프로그램이 올라가 있는 memory의 physical address로 맵핑된다. 만약 해당 address로 접근했을 때, 원하는 내용이 physical memory에 있는 경우는 그냥 그 정보를 CPU가 사용함으로써 처리가 종료된다. 그런데 만약 그 정보가 없는 경우면 어떻게 될까? 이렇게 virtual address가 가리킨 주소가 physica..
 [Architecture] Basic of Virtual Memory (1)
[Architecture] Basic of Virtual Memory (1)
System내의 Memory상에서 쓰이는 address는 크게 두가지가 있다. CPU는 Virtual Address, Memory는 Physical Address를 사용하는데, 실제로 데이터를 가지고 있는 주체인 Memory 관점에서 보면 실제로 저장되는 공간을 물리적으로 표현하는 것이고, CPU는 이 주소를 간접적으로 표현하기 위해 이렇게 구분 지은것으로 이해하면 좋을 거 같다. 아무튼 CPU와 Main Memory 사이의 주소 체계가 다르기 때문에 이를 중간에서 변환할 요소가 필요한데 이걸 Memory Management Unit (MMU)라고 한다. 물론 위 그림에서 CPU와 MMU 사이에는 SRAM으로 구성된 cache도 포함되어 있어야 하겠지만, 여기서는 생략되었다. 그럼 이 MMU가 addre..
 [Architecture] Memory Hierarachy
[Architecture] Memory Hierarachy
(* 이 포스트는 MIT에서 제공되는 Computation Structures 3의 강좌를 요약한 내용이다.) Memory의 가장 큰 목표는 적당한 capacity를 가지면서 빠른 Access time을 가지는 것이다. 하지만 locality라는 특성때문에 capacity가 커지면 커질수록 해당 영역에 대한 Access time은 커질 수밖에 없다. 이를 해결하기 위해서 대부분의 CPU는 몇가지 단계로 나눠진 Cache level을 가진다. Access time을 보면 알겠지만 level이 낮을수록 용량이 낮지만 그만큼 CPU에 가깝기 때문에 Access time에서 이점을 가져올 수 있고, level이 높을수록 access time이 높아지면서 더 많은 데이터를 가질 수 있게 된다. Cache의 역할은..
 [Data] Error Correction
[Data] Error Correction
흔히 뭔가 정보를 표현할때 예를 드는 것중에 하나가 위와 같은 동전이다. 여기선 보통 head를 1, tail을 0으로 표현해서 정보를 나타내게 된다. 만약 이렇게 얻은 정보를 누군가에게 전달한다고 가정을 해보자. 이때 전달과정에서 뭔가의 오류가 발생한다면, 어떻게 될까? 분명 전달하고자 하는 사람은 head를 전달하고자 했음에도 최종적으로는 tail이 전달된 케이스가 그런 경우일텐데, 이렇게 한가지 정보가 잘못 전달된 케이스를 single bit error라고 한다. 당연히 이런 경우를 방지하기 위해서 이런 오류를 탐지하고 수정하는 절차가 필요할 것이다. 여러가지 방법이 있겠지만, 이론상으로 다루는 내용 중 하나가 바로 Hamming Distance라는 것이다. Hamming Distance란 원래의 ..
 [Data] Huffman`s Algorithm
[Data] Huffman`s Algorithm
이전 포스트에서 일종의 binary tree형식으로 bit을 나열해서 Variable Length Encoding을 구한다고 언급했었는데, Tree를 만드는데도 일종의 규칙같은게 있다. Huffman`s Algorithm이라는 것인데, 한번 잠깐 소개해보고자 한다. 우선 Logic은 다음과 같다. 일단 앞의 예제를 그대로 가지고 오는 것을 생각해보자. 위에서 맨처음 스텝에 언급한 것처럼 가장 작은 확률을 가진 symbol 2개를 바탕으로 하나의 subtree를 만든다. 그러면 이렇게 된다.( 우선 C와 D의 순서는 상관없다. 같은 확률을 가지고 있기 때문에 표현하기 좋게 순서대로 나열한 것일뿐 D가 먼저와도 상관없다.) 그러면 이 subtree내의 확률들을 합쳐서 그 다음 노드에 정의를 하고 그 값을 현..
 [Data] Variable Length Encoding
[Data] Variable Length Encoding
이전 포스트에서 정보의 표현량이 고정된 방식인 Fixed Length Encoding에 대해서 언급했다. 아마 그 이전 포스트에서도 언급한 바가 있겠지만, Fixed Length Encoding 기법은 변환하기 쉽고, 모든 경우의 수가 같을 때 사용되는 방법이라고 했었고, 이와 반대 급부로 비효율적으로 정보 표현이 낭비되는 케이스도 존재한다고 했었다. 그걸 어느정도 해결하는 방법이 이제 소개할 Variable Length Encoding이다. 이름에서도 표현되는 것처럼 정보의 표현량이 고정되어 있지 않은 방식이며, 경우의 수가 각각 다를 때 이 표현 방식을 쓰게 되면 bit을 효율적으로 처리하면서 정보를 표현할 수 있다. 예를 들어서 다음과 같은 케이스가 있다고 가정해보자. 이와 같이 A, B, C, D..
 [Data] 2`s complement encoding
[Data] 2`s complement encoding
계속 encoding에 대한 이야기를 하고 있고, 이전 포스트에서는 정보의 표현량이 정해져 있는 기법인 Fixed Length Encoding에 대해서 간단하게 언급해봤다.거기서 마지막에 다뤘던 내용중에 하나가 일종의 이진법의 형식으로 정보가 표현되는 꼴이라는 이야기도 했었다. 그러면 이런걸 처음 접해보는 사람에게는 궁금한게 생길 수 있다. 이 세상의 수에는 소수도 있고, 음수도 있는데 이런 정보는 과연 이런 0과 1로 어떻게 표현하냐는데 대한 것이다. 일단 이번 포스트에서는 음수 표현법에 대해서 다뤄보고자 한다. 우선 음수를 표현하기 위해서는 이진법 표현 규격중에 signed magnitude representation 이라는 방법을 사용한다. Signed 라는 단어에 들어있는 뜻은 "부호가 있는" 이..
 [Data] Fixed Length Encoding
[Data] Fixed Length Encoding
지난번 포스트에서 Encoding에 대해서 소개를 했었다. 소개한 내용중에 아주 간단히 나온 내용이 Fixed Length Encoding 이라는 것인데 이걸 조금더 다뤄보고자 한다.그때도 언급했던 것처럼 정보를 표현하는데 있어서 표현량의 크기가 정해진 케이스가 Fixed length encoding인데, 보통 정보가 고르게 분산된 경우, 즉 모든 케이스가 동일하게 나오는 경우에는 주로 쓰는 기법이다.(Equally Likely) 지난번에 만약 이 length가 entropy보다 작은 경우에 정보의 손실이 발생할 수도 있다고 했었는데, 기본적으로는 Entropy 값이 넘는 걸로 length를 정하게 된다. 이와 같이 ABCD를 표현하는데 있어서도 A,B, C, D가는 나오는 확률이 동일하기 때문에 fix..
- Total
- Today
- Yesterday
- 한빛미디어
- arduino
- Kinect
- Windows Phone 7
- dynamic programming
- Distribution
- Off-policy
- End-To-End
- 강화학습
- Variance
- ai
- Offline RL
- Kinect SDK
- Gan
- ColorStream
- 딥러닝
- DepthStream
- 파이썬
- TensorFlow Lite
- reward
- Policy Gradient
- SketchFlow
- RL
- Pipeline
- Kinect for windows
- Expression Blend 4
- processing
- bias
- windows 8
- PowerPoint
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |