
 [RL] Q-learning
[RL] Q-learning
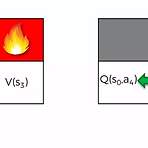
강화학습 포스트를 하면서 Bellman Equation을 거쳐 Markov Decision Process까지 오면서 얻어낸 Bellman Equation은 다음과 같다.$$V(s) = \underset{a}{\max}(R(s, a) + \gamma \sum_{s'} P(s,a,s') V(s'))$$ 다시 말해 다음 State의 Value를 계산할 때, 해당 상태에서 특정 행동 a를 취해서 s'로 갈 수 있는 모든 경우의 수를 고려하고 그에 대한 확률의 평균값을 계산해 최대치가 될 수 있는 state의 Value를 구하는게 MDP였다. 그런데 위와 같이 구한 결과 값은 결국 특정 State에 대한 Value를 구한 것이지, 그 Value를 구하는데 있어 행동이 고려된 것이 아니었다. 다시 말해 Agent가..
 [RL] Markov Decision Process (MDP)
[RL] Markov Decision Process (MDP)
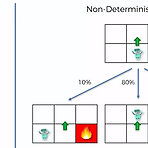
우선 지난 포스트에서도 소개했다시피 Bellman Equation은 각 칸별로 state에 대한 value를 매김으로써 goal까지 가는 최적의 경로를 계산할 수 있었지만, 계산하는 과정에서 확률적인 부분이 고려되지 않아 조금 적용하기 어려운 부분이 있었다. 이 때문에 경로 계산시 확률적인 요소까지 고려한 방법이 이 포스트에서 소개할 Markov Decision Process (MDP)이다. Bellman Equation이 가정했던 것은 왼쪽 그림과 같이 Agent에게 위로 가게끔 하면 Agent는 그 지시에 따라서 위로 움직이게 된다는 것이다. 그런데 이렇게 되면 실질적으로 가르치는 사람이 Agent를 조정하는 형식이 되므로, 학습에 대한 의미가 없어진다. 이때문에 방향 선택에 대해 어느정도의 임의성을..
- Total
- Today
- Yesterday
- processing
- Gan
- 파이썬
- DepthStream
- Kinect SDK
- bias
- 한빛미디어
- Variance
- Distribution
- SketchFlow
- 딥러닝
- RL
- PowerPoint
- Pipeline
- End-To-End
- Off-policy
- 강화학습
- Windows Phone 7
- TensorFlow Lite
- arduino
- reward
- ColorStream
- windows 8
- dynamic programming
- Expression Blend 4
- Policy Gradient
- Kinect for windows
- Kinect
- Offline RL
- Python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |