
티스토리 뷰
(본 글은 OpenAI Spinning Up을 개인적으로 정리한 글입니다. 원본)
Part 2: Kinds of RL Algorithms — Spinning Up documentation
We’ll start this section with a disclaimer: it’s really quite hard to draw an accurate, all-encompassing taxonomy of algorithms in the modern RL space, because the modularity of algorithms is not well-represented by a tree structure. Also, to make somethin
spinningup.openai.com
RL Algorithm의 분류
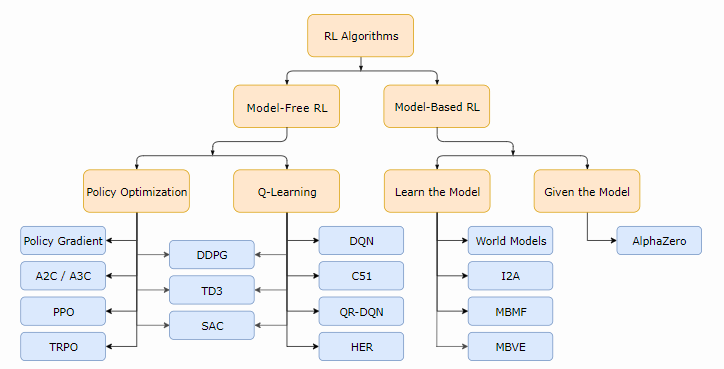
먼저 서두에 밝힐 부분은 현대 RL에서 연구되는 알고리즘들을 정확하고 세분화하게 분류하는 것이 정말 어렵다는 것이다. 그 이유는 algorithm 각각의 modularity가 tree 형태로 잘 표현하기가 쉽지 않기 때문이다. 또한 소개 페이지에 맞게 작성하기 위해서 몇몇 최신 기술들( exploration, transfer learning, meta learning 등등)은 생략해야만 했다. 아무튼 이번 페이지에서 말하고자 하는 것은 다음과 같다.
- Deep RL 알고리즘들이 무엇을 학습하고, 어떻게 학습하는지에 관하여 가장 기초적인 설계 형태를 부각하고자 함
- 이런 선택들간의 trade-off를 언급하고자 함
- 알고리즘의 선택과 관련하여 몇몇 눈에 띄는 현대 알고리즘을 소개하고자 함
Model Free vs Model-based RL
RL 알고리즘에서 가장 형태가 나눠지는 중요한 부분 중 하나는 agent가 environment의 model에 접근하거나, 학습하는지에 대한 여부이다. Environment의 model이라고 하는 것은 state transition과 reward를 예측하는 함수를 말한다.
model을 가지는 것에 대한 큰 장점은 agent로 하여금 미리 어떤 선택 범주가 있고, 그 중 어떤 것을 선택할 것인지에 대해서 명확하게 결정할 수 있는, 결국 agent가 plan을 할 수 있게 해준다는 것이다. 그렇게 하면 agent는 학습된 policy로부터 미리 planning을 통해 결과를 추출해낼 수 있게 된다. 이런 접근 방식이 잘 드러난 예가 바로 AlphaZero이다. AlphaZero가 잘 동작하면, model을 가지지 않은 방식들과 비교해서 sample efficiency 관점에서 상당한 성능 향상을 얻을 수 있다.
주요 단점은 environment에 대한 ground-truth model이 일반적으로는 agent에 적용되지 않는다는 것이다. 이런 경우에 agent가 해당 model을 사용하고 싶으면, experience로부터 처음부터 model을 학습시켜야만 하는데, 여기에는 여러 난관들이 존재한다. 가장 큰 난관은 model내의 bias가 agent에 의해 도출되는 경우인데, 이 경우 agent는 학습된 model에 대해서는 잘 동작하지만, real-environment에 대해서는 sub-optimal하거나 (어쩌면 엄청 나쁘게) 동작하는 경우가 발생하게 된다. Model-learning은 원론적으로는 매우 어려운 작업이며, 그렇기 때문에 수많은 시간을 쓰고, 계산을 열심히 하는 등 노력을 많이 해도 실패하는 경우가 발생한다.
보통 model을 사용하는 알고리즘을 model-based method라고 표현하고, 그렇지 않은 것들을 model-free라고 부른다. model-free method가 model-based method에 비해서 sample efficiency 측면에서 잠재적인 성능 개선을 얻을 수 없지만, 구현하거나 세부 튜닝을 하기가 상대적으로 쉽다. 이 소개글을 쓰는 시점(2018년 9월)에는 model-free method들이 조금더 많이 다뤄지고, model-based method들에 비해서 더 활발하게 개발되며, 테스트되고 있다.
What to Learn
RL 알고리즘을 나누는 또다른 중요한 부분은 무엇을 학습하느냐에 대한 질문이다. 여기에 대한 일반적인 답변은 다음과 같이 들 수 있다.
- Stochastic하거나 Deterministic한 Policy
- Action-value function (Q-function)
- Value function
- 그리고 environment model
What to learn in Model-free RL
model-free RL에서 agent를 나타내고 학습시키는데 두가지 주요 방법론이 있다.
Policy Optimization : 해당 기법을 사용한 알고리즘들은 Policy를 \(\pi_{\theta}(a|s)\)로 명시한다. 그래서 policy를 결정짓는 parameter \(\theta\)를 최적화시키게 되는데, 이때 performance objective function \(J(\pi_{\theta})\)에서 gradient ascent를 취함으로써 직접적으로 최적화시키거나, 아니면 \(J(\pi_{\theta})\) 의 local approximation을 최대화하는 방식으로 간접적으로 최적화시킨다. 이런 최적화 기법은 거의 항상 on-policy에서 동작하는데, 이 말은 가장 최근에 수행한 policy에 따라서 action을 취하는 동안 매 업데이트가 발생할 때마다 수집된 데이터만 사용한다는 것을 의미한다. Policy optimization은 또한 일반적으로 on-policy value function \(V^{\pi}(s)\)를 구하기 위해서 사용하는 approximator인 \(V_{\phi}(s)\)를 학습시키는 것과 연관이 있는데, 보통 policy를 어떻게 update하는지를 규명하는데 사용하게 된다.
Policy Optimization 기법을 사용한 몇몇 예제는 다음과 같다.
- A2C / A3C (Advantage Actor-Critic Agent / Asynchronous Advantage Actor-Critic) Mnih et al, 2016
: performance를 직접적으로 극대화시키기 위해서 gradient ascent를 사용했다. - PPO (Proximal Policy Optimization) Schulmann et al, 2017
: performance를 극대화시키기 위해서 간접적으로 update하는 기법을 사용했는데, \(J(\pi_{\theta})\)가 얼마나 update에 대한 결과에 변화를 끼치는지를 판단하기 위해, 이를 대략적으로 추정치를 알려주는 surrogate objective function을 최대화시키는 방법을 구현했다. - TRPO (Trust Region Policy Optimization) Schulmann et al, 2015
Q-learning : 해당 기법을 사용한 알고리즘들은 Optimal action-value function \(Q^{*}(s, a)\)를 구하기 위해서, \(Q_{\theta}(s, a)\)라는 approximator를 학습한다. 일반적으로, Bellman Equation에 기반한 objective function을 사용한다. 이 최적화 방법은 거의 항상 off-policy에서 동작하는데, 이 말은 agent가 데이터를 얻을 때, environment에서 어떻게 탐색했는지 여부와 상관없이, 학습동안 수집된 데이터를 모두 사용하는 것을 의미한다. 여기서 구하고자 하는 policy는 optimal state-action function인 \(Q^{*}\)와 optimal policy인 \(\pi^{*}\)간의 관계를 통해 얻을 수 있게 되는데, 이 때 Q-learning agent가 취하는 action은 다음 함수를 통해 도출할 수 있다.
$$ a(s) = arg\max\limits_{a}Q_{\theta}(s, a) $$
Q-learning 기법을 사용한 예제는 다음과 같다.
- DQN (Deep Q-Network) Mnih et al, 2013
: Deep RL을 본격적으로 나오게 한 고전 논문 - C51 (Categorical 53-Atom DQN) Bellemare et al, 2017
: 기대치가 \(Q^{*}\)인 return 상에서의 distribution을 학습하는 방법이 적용되었다. - QR-DQN (Quantile Regression DQN) Dabney et al, 2017
- HER (Hindsight Experience Replay) : Andrychowicz et al, 2017
Policy Optimization과 Q-learning간의 trade-off : policy optimization의 주요 강점은 "사용자가 원하는 것을 직접적으로 최적화하겠다는 입장" 에서 나오는 것처럼 원론적이라는 것이다. 이런 경향으로 인해 안정적이고 신뢰성있게 동작한다. 반면, Q-learning은 self-consistency equation을 충족시키기 위해 \(Q_{\theta}\)를 학습함으로써, agent 성능에 대해 간접적으로만 최적화를 진행한다. 보통 이런 종류의 방법들은 많은 실패가 발생하며, 이로 인해 덜 안정적으로 동작하는 경향이 있다.
Q-learning이 어떻게, 왜 실패하는지에 대해서 더 찾아보고 싶으면 다음 정보를 참고하면 된다.
1) Tsitsiklis and van Roy가 쓴 고전 논문
2) Szepesvari가 review한 논문 (section 4.3.2 참조)
3) Sutton and Barto가 쓴 책 (chapter 11, 특히 chapter 11.3 - "the deadly triad" of function approximation, bootstrapping, and off-policy data, together causing instability in value-learning algorithms)
하지만, Q-learning은 실제 동작할때, 실질적으로 더 많은 샘플을 효율적으로 얻는 것에 대해서 이점을 가지고 있는데, 그 이유는 policy optimization 기법들에 비해서 더 효율적으로 데이터를 제사용할 수 있기 때문이다.
Policy Optimization 과 Q-Learning간의 보완 : 이상하게도, policy optimization과 Q-learning은 서로 호환이 되지 않는다. (그런데 어떤 환경에서는 동일한 것으로도 판명났다.) 그리고 두 방법 사이에서 존재하는 알고리즘들도 존재한다. 이런 알고리즘은 각각의 강점과 약점 사이의 trade-off를 잘 다룰 수 있다. 이에 대한 예로는
- DDPG (Deep Deterministic Policy Gradient) Lillicrap et al, 2015
: deterministic policy와 Q-function을 서로의 성능을 향상시키기 위해 동시에 학습시키는 기법 - SAC (Soft Actor-Critic) Haarnoja et al, 2018
: 학습을 안정화시키기 위해 stochastic policy와 entropy regularization, 그리고 몇몇 기법을 사용한 방법으로 일반적인 benchmark에서는 DDPG보다 성능이 좋음 - TD3 (Twin Delayed DDPG) Fujimoto et al, 2018
What to Learn in Model-Based RL
model-free RL과는 다르게, model-based RL에 대한 쉽게 정의가능한(easy-to-define) 방법들도 적지 않다. model을 사용한 방법도 많이 있다. 몇몇 예제를 제공하긴 할 것이지만, 여기 있는 것이 전부 설명되어 있지는 않을 것이다. 각각의 경우, model이 주어지거나, 학습된 상태에 있을 것이다.
Backgroud : Pure Planning : 가장 기본적인 접근 방법은 policy를 명확하게 도출하지 않고, 대신 action을 선택하는데 있어서 model-predictive control (MPC) 와 같은 pure planning 기법을 활용한다. MPC에서는, agent가 environment를 관찰할 때마다, model에 대해서 가장 optimal한 plan을 계산하는데, 이때 plan은 현재 시점에서 정해진 시점 이후까지 취해질 모든 action들을 묘사한 것을 말하게 된다. (현재 시점 이후의 reward는 학습된 value function을 통해서 현재의 알고리즘이 planning하면서 사용될 것이다.) 그러면 agent는 action들이 포함된 plan 중에서 처음 action만 취하고, 나머지들은 action이 취해지는 시점에 모두 배제시킬 것이다. 그러면 매순간 environment와 interact하기 위한 새로운 plan을 만들어낼텐데, 이를 통해서 기대한 것보다 모자른(shorter-than-desired) plan에서 나온 action이 수행되는 것을 피할 수 있게 된다.
- MBMF (Model-Based Deep RL with Model-free Fine-tuning) Nagabandi et al, 2017
: Deep RL 에서 몇몇 표준 benchmark task를 통해 학습된 environment model을 사용해서 MPC를 탐색하는 기법
Expert Iteration : 앞에서 언급한 pure planning에 이어 나온 직관적인 방법은 policy \( \pi_{\theta}(a|s)\)를 학습하고 사용하자는 것이다. agent는 (Monte Carlo Tree Search와 같은) planning 알고리즘을 model에 사용하고, 현재 사용하고 있는 policy로부터 sampling함으로써 plan에 대한 후보 action들을 추출해낸다. 그러면 planning 알고리즘은 policy 자체가 스스로 생성해낸 것보다 더 좋은 action을 만들어내게 되는데, 이런 일련의 과정이 policy보다 상대적으로 "expert"가 되는 것이라 표현하는 것이다. 그러면 policy는 planning algorithm의 결과물과 유사한 action을 만들어내도록 업데이트가 되는 것이다.
- ExIt (Expert Iteration) T. Anthony et al, 2017
: Hex라는 게임을 할 수 있도록 deep neural network을 학습시키는데 해당 방법을 씀. - AlphaZero Silver et al, 2017
: 이런 방법을 적용한 또다른 예제
Data Augmentation for Model-Free Methods : policy나 Q-function을 학습시키는데 Model-free RL 알고리즘을 사용하되, 다음 부분에서 다른 것과 차이가 있다.
1) agent를 업데이트시키는데 있어 실제 얻은 experience를 가상(fictitious)으로 확장시킴.
2) agent를 업데이트시키는데 있어 가상의 experience만 사용함.
- MBVE (Model-Based Value Expansion) Feinberg et la, 2018
: 실제 얻은 경험을 가상으로 확장시킨 예제 - World Models Ha and Schmidhuber, 2018
: 가상의 경험을 사용해서 agent를 학습시킨 예제. 이를 "training in the dream"이라고 표현함
Embedding Planning Loops into Policies : 또다른 접근 방식은 planning과정을 policy안에 하나의 subroutine처럼 직접적으로 내장하는 것이다. 이를 통해서 policy의 output이 많이 사용되는 model-free 알고리즘을 통해서 학습되는 동안 complete plan이 그 policy에 세부 정보를 제공하는 것이다. 여기에 핵심 요소는 framework 안에 있는데, policy가 plan을 언제 사용하고 어떻게 사용하는지에 대해서 학습할 수 있게 된다는 것이다. 이런 동작은 model bias로 인해서 발생하는 문제를 작게 만들어 주는데, 그 이유는 만약 model이 특정 state에 대해서 planning하는 것이 나쁘다고 판단될 경우, policy가 그 model이 나쁘다고 생각하고 무시하게끔 간단하게 학습할 수 있기 때문이다.
- I2A (Imagination-Augmented Agents) Weber et al, 2017
: agent로 하여금 이런 형식의 imagination을 전달할 수 있게끔 해주는 예제
'Study > AI' 카테고리의 다른 글
| [RL] (Spinning Up) Proof for Using Q-Function in Policy Gradient Formula (0) | 2019.05.23 |
|---|---|
| [RL] (Spinning Up) Proof for Don't Let the Past Distract You (0) | 2019.05.23 |
| [RL] (Spinning Up) Intro to Policy Optimization (0) | 2019.05.22 |
| [RL] (Spinning Up) Key concepts in RL (0) | 2019.05.20 |
| [ETC] Google Coral Dev Board (0) | 2019.05.07 |
| [ETC] Atari-wrapper 설치하다 error가 발생하는 경우 (0) | 2019.04.30 |
| [RL] Windows 10에서 OpenAI Gym & Baselines 설치하기 (13) | 2019.04.30 |
- Total
- Today
- Yesterday
- 딥러닝
- Windows Phone 7
- dynamic programming
- ColorStream
- PowerPoint
- Kinect
- processing
- TensorFlow Lite
- Expression Blend 4
- Python
- Off-policy
- arduino
- SketchFlow
- Variance
- Kinect SDK
- Gan
- Distribution
- DepthStream
- Pipeline
- 파이썬
- 한빛미디어
- Policy Gradient
- bias
- 강화학습
- RL
- End-To-End
- Kinect for windows
- windows 8
- reward
- Offline RL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |