
 [Embedded][DL] Tensorflow Lite - Quantization
[Embedded][DL] Tensorflow Lite - Quantization
이전 포스트에서도 계속 언급했다시피, 딥러닝 모델을 모바일이나 임베디드 환경에서 그대로 돌리기 어려운 이유는 일반 PC와 달리 메모리나 성능, 저장공간 등의 제한이 있기 때문이다. 이 때문에 해당 모델을 어떻게 최적화(Optimization)하느냐가 임베디드 환경상에서도 최적의 성능을 낼지 여부를 결정하는 요소가 된다. Tensorflow Lite도 결국은 Model deploy시 이 최적화를 해주는 기능이 포함되어 있는 것인데, 이 때 Quantization이 적용된다.치ㅑ Quantization은 간단히 말해서 Neural Network의 내부 구성이나 표현되는 형식을 줄이는 과정을 말한다. 예를 들어서 현재 구성된 Neural Network의 weight이나 activation output이 32b..
 [Thing][Embedded] Sparkfun Edge
[Thing][Embedded] Sparkfun Edge
며칠전에 Tensorflow Lite 관련해서 Google 쪽이랑 미팅을 했다. 우리 회사도 MCU를 많이 쓰다보니까 MCU를 타겟팅한 Tensorflow Lite가 올라가면 좋겠지만, 실제 현업에서 적용하기에는 고려할 사항이 많다. 아무래도 optimization에 초점을 맞춘 framework다 보니, 모델 사이즈 측면도 있고, 과연 Tensorflow Lite를 지원하게끔 MCU compiler가 기능을 지원하냐 그런 문제도 있고, 아직까지는 갈길이 좀 먼거 같다. 그래도 그쪽 엔지니어가 이런거 많이좀 써보고 미리 경험해보라면서 EVB 하나를 줬었는데, 보니까 Sparkfun Edge였다. 아마 짐작하기로는 Google이 ARM Cortex-M계열 MCU에도 올릴 수 있다는 것을 보여주기 위해서 출..
 [Book][ML] 파이썬을 활용한 머신러닝 쿡북
[Book][ML] 파이썬을 활용한 머신러닝 쿡북
(해당 포스트에서 언급되는 "파이썬을 활용한 머신러닝 쿡북" 책은 한빛미디어로부터 제공받았고, 이에 대한 서평을 쓴 것 임을 알려드립니다.) 현업이나 학교 과제 중에서 머신러닝 관련 일을 하게 되면, 제일 번거로운게 API의 사용이나 내가 원하는대로 고치는 것이다. 물론 Tensorflow나 Scikit-learn과 같이 유명한 프레임워크는 API documentation도 제공하고, 많은 사람들이 실제로 접해보면서 나름 쉽게 풀어쓴 예제들이 많이 제공되지만, 꼭 찾다보면 내가 필요한 것을 설명한 게 없는 경우가 많다. 나같은 경우에는 얼마 전에 언급한 Exploratory Data Analysis (EDA)에 필요한 문제를 해결하다가 딱 맞게 설명된 예제도 없어서 나름 응용해본 케이스를 소개했었는데, ..
홈페이지에는 Tensorflow Lite로 구현할 수 있는 Image Classification이나 Object detection, Question Answering 같은 예제들이 소개되어 있다. 참고로 Raspberry PI같이 Embedded 환경에서 Test해볼 수 있는 Image Classification이랑 Object Detection 같은 것만 예제로 제공되고 있다. 아무튼 전반적인 Tensorflow Lite가 어떻게 돌아가는지를 확인해볼 수 있는 예제를 살펴보고자 한다. 우선 Keras로 간단한 Linear regression을 위한 model을 한번 만들어본다. import tensorflow as tf x = [-1, 0, 1, 2, 3, 4] y = [-3, -1, 1, 3, 5, ..
 [Embedded][DL] Tensorflow Lite - Introduction
[Embedded][DL] Tensorflow Lite - Introduction
보통 Deep Learning을 생각하면, 엄청 복잡한 모델, 예를 들면 Image Classification을 할 때 CNN으로 구성한다던지, 뭔가 예측을 할때 LSTM같은 특정 기능을 하는 모델을 생각할 것이다. 이런 것들을 실제 폰이나 전자 제품에 올라가있는 Microcontroller 같은데에서도 동작할까? 기본적으로 Deep Learning 모델을 학습시키는 PC를 생각하면, 일반적으로 x86 cpu를 쓰고 별도로 GPU같은 가속기를 달기도 하며, 모델을 읽어오거나 저장할 공간이 충분하고, Windows나 Linux같은 OS가 올라가 있겠지만, 폰에는 ARM cpu가 들어있고, PC에 비해서는 상대적으로 저성능이고, 심지어 Microcontroller에는 OS도 없는 환경이 대부분일 것이다. 이..
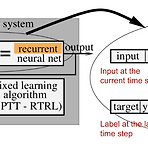 [RL] Meta Reinforcement Learning
[RL] Meta Reinforcement Learning
(해당 글은 OpenAI Engineer인 Lilian Weng의 포스트 내용을 원저자 동의하에 번역한 내용입니다.) Meta Reinforcement Learning Meta-RL is meta-learning on reinforcement learning tasks. After trained over a distribution of tasks, the agent is able to solve a new task by developing a new RL algorithm with its internal activity dynamics. This post starts with the origin of meta-RL an lilianweng.github.io Meta-RL은 강화학습 task에 meta l..
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트들을 통해서 설명하고자 했던 것은 기존의 Q-table과 같은 Tabular 방식이 아닌, Value를 하나의 Function, 즉 Value Function으로 근사하는 방법이 존재하고, 이때 이 근사된 Value Function과 실제 Value Function과의 오차를 줄일 수 있는 방법으로 Gradient Descent를 적용할 수 있다는 것이었다. 그래서 Function Approximation을 Monte Carlo에 적용한 Gradient MC과 제한적이기는 하나, Gradient를 TD Learning에 적용한 Semi-Gradien..
 [RL] The Objective of TD
[RL] The Objective of TD
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 역시 Function Approximation 기법을 Monte Carlo Method처럼 TD Learning에다가도 접목시킬 수 있다. 우선 Monte Carlo method에 Function Approximation을 접목한 Gradient Monte Carlo에서 weight이 update되는 과정을 다시 돌아보면 다음과 같다. $$ \mathbf{w} \leftarrow \mathbf{w} + \alpha[ G_t - \hat{v}(S_t, \mathbf{w})] \nabla \hat{v}(S_t, \mathbf{w}) $$ 이를 사용하면 estima..
 [RL] The Objective for On-policy Prediction
[RL] The Objective for On-policy Prediction
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트를 통해서 기존의 tabular method가 아닌 Function Approximation으로 value function을 정의하는 방법을 대략적으로 설명했다. 일단 뭐가 되던 간에 우리가 만들 value function은 각 state에 대한 value function이 차별성을 잘 띄고 있어야 하고(high discrimination), 전체 state에 대한 일반화도 잘되어야 한다.(high generalization) 그렇게 해서 어떤 linear value function \( \hat{v}(s, \mathbf{w})\) 을 만들었다고 가..
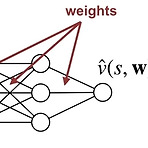 [RL] Estimating value function with supervised learning
[RL] Estimating value function with supervised learning
(해당 포스트는 Coursera의 Prediction and Control with Function Approximation의 강의 요약본입니다) 이전 포스트까지 다룬 알고리즘들은 기본적으로 state/action에 따른 value가 table 형식으로 정의된 tabular value function을 사용했다. 이런 케이스 value function을 정의하기는 쉽지만, 일반화(generalization)을 하기가 어렵다. 예를 들어서 action이나 state가 table처럼 구분할 수 있는 discrete한 값이 아니라 continuous한 값을 가진 경우라면, 위와 같은 tabular value function을 사용하기 어렵다. 또한 state space나 action space의 scale이 ..
- Total
- Today
- Yesterday
- Python
- Gan
- arduino
- reward
- processing
- Kinect SDK
- bias
- Windows Phone 7
- Policy Gradient
- Distribution
- dynamic programming
- Expression Blend 4
- Variance
- 파이썬
- ColorStream
- Kinect
- DepthStream
- Off-policy
- TensorFlow Lite
- 한빛미디어
- Pipeline
- Kinect for windows
- PowerPoint
- End-To-End
- 딥러닝
- 강화학습
- RL
- windows 8
- SketchFlow
- Offline RL
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |